A Container Pre-copy Migration Method Based on Dirty Page Prediction and Compression
💡 요약
- abstract: 컨테이너 라이브 마이그레이션의 사전 복사 알고리즘에 더티 페이지가 반복적으로 전송되는 문제를 해결하기 위한 연구
- introduction: 라이브 마이그레이션에서 가장 널리 사용되는 기술인 사전 복사 알고리즘은 메모리 집약적인 시나리오에서 메모리 페이지의 복사를 반복하기 때문에 전송되는 데이터의 양과 총 마이그레이션 시간이 늘어날 뿐만 아니라 반복 프로세스가 수렴되지 않아 마이그레이션이 실패할 수 있다는 문제가 있다.
- related works:
- method: 프로그램 운영체제의 locality 원칙을 활용하고, 더티 페이지 예측을 위해 랜덤 포레스트 모델을 사용하여 반복되는 더티 페이지 전송을 건너뛴다. 페이지 압축과 함께 incremental page만 전송하여 기존의 사전 복사 방식에 비해 데이터 전송 및 마이그레이션 시간을 크게 단축했다. => 메모리 페이지와 인접한 페이지의 더티 레코드를 수집하고 머신러닝 모델을 사용하여 향후 페이지가 더티화될지 여부를 예측함
- experiment: 더티 페이지가 적게/많이 발생하는 환경에서 제안하는 알고리즘은 가장 최적의 결과를 보여주었다.
- conclusion & discussion: ML 접근법을 사용하여 컨테이너 라이브 마이그레이션을 최적화하기 위한 알고리즘을 설계했으며, 전송 데이터를 줄이기 위해 압축 알고리즘을 함께 사용했다.
Introduction
- 가상화
- 가상 머신
- 컨테이너 가상화:
- 경량, 휴대성, 빠른 시작 속도
- Docker, LXC, Podman
- 서비스 마이그레이션: 가상시스템을 다른 곳으로 이동
- 콜드 마이그레이션: 전원이 꺼져 있거나 일시 중단된 가상 시스템을 새 호스트로 이동
- 라이브 마이그레이션 (=핫 마이그레이션): 전원이 켜진 가상 시스템을 새 호스트로 이동
- 마이그레이션 과정에서 서비스가 영향을 받지 않도록 하는 것을 목표로 한다.
- 사전 복사(pre-copy) 알고리즘: 라이브 마이그레이션에서 가장 널리 사용되는 기술로, 컨테이너가 실행되는 동안 메모리 페이지가 소스에서 대상으로 전송된다.
- 사전 복사는 일반적으로 남아 있는 더티 페이지 수가 충분히 낮을 때 종료된다. => 메모리 집약적인 시나리오에서 사전 복사 알고리즘은 반복 단계에서 메모리 페이지의 복사를 반복하기 때문에 전송되는 데이터의 양과 총 마이그레이션 시간이 늘어날 뿐만 아니라 반복 프로세스가 수렴되지 않아 마이그레이션이 실패할 수 있다.
- c.f. Post-copy는 네트워크를 통해 각 페이지를 한 번만 전송하는 반면, Pre-copy는 마이그레이션 중에 페이지가 소스에서 반복적으로 write가 발생하는 경우 동일한 페이지를 여러 번 전송할 수 있다.
- Pre-copy: 마이그레이션 중에 source에서 VM 상태를 최신 상태로 유지
- Post-copy: source와 destination 간에 VM 상태를 분할
- 실시간 마이그레이션 중에 대상이 실패하면 사전 복사는 VM을 복구할 수 있지만 사후 복사는 복구할 수 없다
Related Work
- pre-copy: 더티 메모리 페이지를 반복적으로 복사하여 가상 머신 다운타임을 단축, 부하가 높고 메모리 쓰기 집약적인 시나리오에서는 반복 단계에서 일부 메모리 페이지가 자주 수정되어 매우 더티한 일부 메모리 페이지가 반복적으로 전송될 수 있어서 전송되는 데이터의 양을 증가시킬 뿐만 아니라 반복 프로세스가 수렴하지 못하는 원인이 될 수 있다
- 페이지 중복 전송 문제를 피하기 위해, 자주 더럽혀지는 페이지를 추적하여 전송 종료 단계에 저장하는 재사용 거리 개념 제안
- 마르코프 예측 모델을 사용하여 메모리 페이지의 기록된 과거 동작을 사용하여 상태 전이 행렬을 통해 페이지가 다시 수정될 확률을 계산하고 예측 확률이 낮은 페이지만 전송하는 방법을 제안
- related dirty rate에 기반한 예측 방법을 제안했다. 페이지의 수정 확률 P를 실제 수정 시간 R과 결합하여 관련 더티 페이지 비율 PR을 얻은 후, R과 PR이 모두 설정된 임계값보다 큰 경우에만 페이지 전송을 건너뛴다.
- => 페이지의 시간적 상관관계만 고려할 뿐 공간적 상관관계는 고려하지 않음
- 마이그레이션 과정에서 메모리 더티 페이지의 생성 속도를 줄이기 위해 CPU 스케줄링을 사용하여 마이그레이션의 원활한 진행을 보장함 => 필연적으로 애플리케이션 성능 저하로 이어질 수 있으며 여러 번의 반복이 완전히 해결되지 않음
- 대역폭 인식 기반의 데이터 압축 방법을 제안하여, 마이그레이션 대역폭에 따라 적절한 압축 알고리즘을 동적으로 선택하여 전송할 페이지를 압축한 후 목적지로 전송함으로써 전송 데이터의 양을 줄이고 전체 마이그레이션 시간을 단축함
- post-copy
- hybrid copy
- 로그 기반 추적
- 복제 마이그레이션
가상 머신에 비해 컨테이너 라이브 마이그레이션에 대한 연구는 상대적으로 적다.
- Virtuozzo: 컨테이너에서 라이브 마이그레이션을 지원한다. 마이그레이션을 수행하는 데 필요한 주요 프로세스와 기능을 커널에 통합하여 구현하기 때문에 Virtuozzo 커널은 고도로 커스터마이징된 커널로, 메인스트림 Linux 커널에서 동일한 기능을 구현하기 위해 Virtuozzo는 CRIU 프로젝트를 설립했다.
- CRIU: Linux에서 실행되는 오픈 소스 소프트웨어 도구로, 사용자 공간에서 프로세스를 체크포인트 및 복원할 수 있다. 즉, 체크포인트 메커니즘을 사용하여 실행 중인 애플리케이션을 동결하고 해당 상태 정보를 디스크에 이미지 파일로 덤프한 다음, 이 이미지 파일을 사용하여 복원 작업을 수행하여 동결된 지점에서 복구하고 프로그램을 다시 실행할 수 있다.
- => 현재 Docker에는 컨테이너 마이그레이션 작업을 지원하는 통합 CRIU 도구가 있지만, 이 접근 방식은 상태 저장 컨테이너 마이그레이션을 지원할 수 없으며 과도한 다운타임을 초래한다.
- P.Haul: Docker 컨테이너의 외부 마이그레이션을 가능하게 하는 OpenVZ에서 시작한 프로젝트로, 외부 마이그레이션은 P.Haul이 CRIU를 통해 Docker 컨테이너 내 프로세스의 실시간 마이그레이션만 구현하기 때문에, 이 방식은 destination 단의 Docker 엔진이 컨테이너를 관리할 수 있는 기능을 상실하게 된다.
- 중첩 가상화와 컨테이너 마이그레이션을 통해 메모리 공간을 리매핑하여 동일한 호스트에서 컨테이너 메모리 마이그레이션을 최적화 => 호스트 간 컨테이너 마이그레이션을 지원하지 않는다.
- NFS를 사용하여 데이터 전송을 용이하게 하는 방법도 있는데, 이는 메모리 집약적인 워크로드를 마이그레이션할 때 긴 다운타임을 유발한다.
- 파일 시스템 공유 방식을 사용하여 포스트카피와 파일 시스템 유니온을 기반으로 실시간 마이그레이션을 하는 방법도 있다.
Method

- original pre-copy algorithm:
- 반복 마이그레이션 단계: 첫 번째 라운드에서 모든 메모리 페이지를 대상 호스트로 전송하고, 이후 각 라운드에서는 이전 라운드 반복 후 수정된 메모리 페이지(더티 페이지)만 전송한다. 셧다운 마이그레이션 조건이 충족될 때까지 이 반복 프로세스를 반복한다.
- 셧다운 마이그레이션 단계: source 호스트는 컨테이너를 잠시 중지하고, 더티 메모리 페이지의 마지막 라운드와 CPU 등의 기타 상태 정보를 대상 호스트에 전송한 후, 이러한 정보에 따라 destination 호스트에서 컨테이너를 재시작한다.
- => 메모리 집약적인 쓰기 부하에서는 반복적인 마이그레이션 단계에서 일부 메모리 페이지가 자주 쓰기 되어 페이지 전송이 반복됨
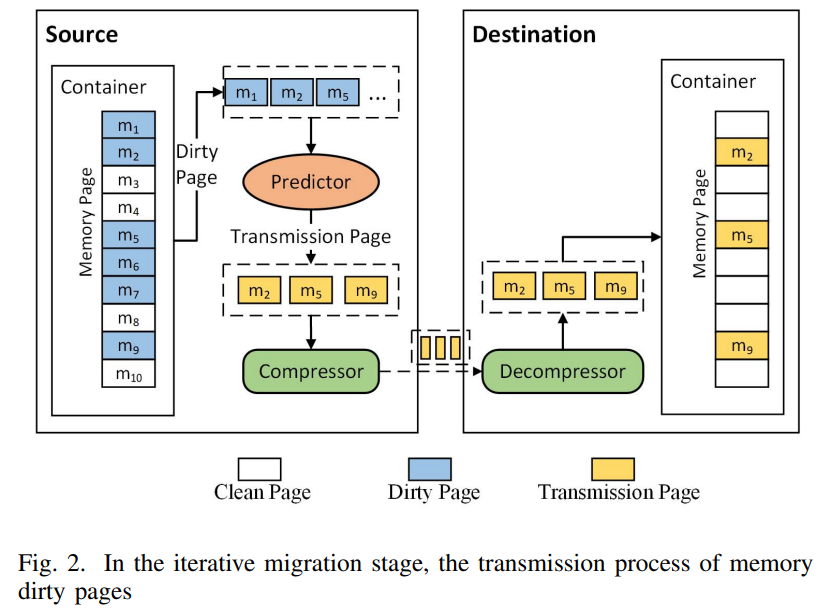
- 일정 기간 동안 컨테이너 메모리의 변경 사항을 수집
- 수집한 메모리 더티 데이터를 사용하여 생성된 더티 페이지를 예측 => 더티 페이지가 많은 페이지의 전송을 생략하고 페이지 압축을 사용하여 데이터 전송을 줄인다.
- (반복적인 복사본 마이그레이션 단계) 페이지 예측과 페이지 압축을 사용하여 더티 페이지의 전송을 최적화한다. 최대 반복 횟수에 도달하거나 더티 페이지 데이터 크기가 수렴하는 등 셧다운 마이그레이션 조건이 충족되면 셧다운 마이그레이션 단계로 진입
- 셧다운 마이그레이션 단계로, source 호스트는 컨테이너 실행을 중지하고 컨테이너의 남은 더티 페이지를 압축한 후 CPU 및 기타 상태 정보와 함께 대상 호스트에 전송
- 컨테이너 복구 단계로, destination 호스트는 수신한 메모리 데이터 정보에 따라 컨테이너의 동작을 재개
더티 페이지의 반복 전송 문제를 해결하기 위해
- 더티 페이지 예측: 일정 기간 동안 컨테이너 메모리의 변경 사항을 수집하여 더티 페이지가 향후에도 계속 더티 페이지가 될 확률을 예측하여 더티 비율이 낮은 페이지를 전송할 페이지 세트에 추가하고 더티 비율이 높은 페이지의 전송을 건너 뛴다.
- 기존의 더티 페이지 예측 방법은 대부분 시계열 예측 방법을 사용하는데, 본 논문에서는 기존 방식과 달리 머신러닝 방식을 사용한다.
- 특징 추출 방법: 지역성 원리에 기반한 특징 선택
- 시간적 지역성: 현재 더럽혀진 페이지가 가까운 미래에 다시 더럽혀질 가능성이 높다는 것을 의미
- 공간적 지역성: 현재 더럽혀진 페이지에 인접한 주소 페이지가 가까운 미래에 더럽혀질 가능성이 높다는 것을 의미
- 오프라인에서 모델을 학습하는 데 사용하여 컨테이너의 온라인 마이그레이션에 적용한다.
- 랜덤 포레스트: 과적합이 쉽지 않고 일반화 능력이 높기 때문에 예측 모델로 선택했으며, 특징 윈도우 m*n이 증가함에 따라 모델 예측 정확도가 증가하는 것을 확인함
- 실제 컨테이너 마이그레이션에서는 피처 윈도우가 커질수록 예측 시간 오버헤드가 발생하게 되므로, 본 논문에서는 예측 효과와 예측 시간의 균형을 맞추기 위해 피처 윈도우 m=5, n=5로 고정
- 특징 추출 방법: 지역성 원리에 기반한 특징 선택
- 기존의 더티 페이지 예측 방법은 대부분 시계열 예측 방법을 사용하는데, 본 논문에서는 기존 방식과 달리 머신러닝 방식을 사용한다.

- PageList: 컨테이너 메모리에 있는 모든 페이지의 집합 => 각 반복 후 관련 페이지 정보를 업데이트해야 한다.
- Dirty: 이번 라운드의 더티 페이지 집합
- ToTransmit: 이번 반복에서 최종적으로 전송할 페이지의 집합
- ToSkip: 반복 중에 전송을 건너뛰는 페이지의 집합
- RFModel: 랜덤 포레스트 예측 모델로, 예측이 1이면 향후에도 페이지가 dirty 할 것을 의미한다.
각 반복 라운드에서 랜덤 포레스트 모델을 사용하여 현재 더티 페이지가 1로 예측되면 현재 라운드에서 해당 페이지의 전송을 건너뛰고 ToSkip에 추가하고, 예측이 0이면 이번 라운드에서 페이지가 destination에 전송된다.
이번 라운드의 클린 페이지의 경우 이전 반복에서 전송을 건너뛰고 ToSkip에 저장한 경우 이번 라운드에서 제 시간에 대상에 전송해야 한다.

- 전송되는 메모리 페이지 압축: 전송할 페이지를 압축하여 네트워크에서 전송되는 데이터의 양을 더욱 줄인다.
- 페이지를 전송할 때 페이지 단위가 아닌 바이트 단위로 전송한다. 한 반복 내에서 전송할 더티 메모리 페이지가 처음 전송되는지 여부를 확인하고, 처음 전송되는 페이지가 아니면 지난번에 destination으로 전송한 페이지 데이터와 XOR하여 페이지 증분값을 구한 뒤 페이지 증분값을 압축하여 전송한다.
- 증분 압축의 장점은 페이지 증분에는 반복되는 0이 많이 포함되어 페이지의 압축률을 향상시키는 데 도움이 된다는 것이다.
- 압축 알고리즘은 LZ4 압축 알고리즘을 선택했으며, 이는 무손실 압축 알고리즘으로 압축 속도가 빨라 메모리 데이터 압축 장면에 적합하고 압축 비율과 압축 속도를 넓은 범위에서 조정할 수 있다.
- 데이터를 수신한 destination에서는 압축을 풀고 다시 XOR하여 이번 라운드의 실제 메모리 페이지 데이터를 얻는다.
- 페이지를 전송할 때 페이지 단위가 아닌 바이트 단위로 전송한다. 한 반복 내에서 전송할 더티 메모리 페이지가 처음 전송되는지 여부를 확인하고, 처음 전송되는 페이지가 아니면 지난번에 destination으로 전송한 페이지 데이터와 XOR하여 페이지 증분값을 구한 뒤 페이지 증분값을 압축하여 전송한다.
Experiment
실험 환경: 두 개의 가상 머신에서 Docker 컨테이너의 라이브 마이그레이션을 테스트
- Ubuntu 18.04 LTS, CPU 코어 2개, 8GB RAM 및 50GB 디스크
- 두 가상 머신 간의 네트워크 대역폭은 100Mbps
컨테이너가 실행 중일 때 다양한 메모리 쓰기 부하를 시뮬레이션하기 위해 모든 크기의 연속 메모리를 신청하고 연속 쓰기 작업을 수행할 수 있는 MemChange 프로그램을 작성하고 이를 컨테이너화했다.
사전 복사 알고리즘은 메모리 더티율이 전송 대역폭을 초과할 수 없어야 하며, 그렇지 않으면 반복 프로세스가 수렴하지 않거나 심지어 중지되므로 실험 환경의 네트워크 대역폭 100Mbps에 따라 두 가지 메모리 더티 레이트 부하를 설계했다.
- 메모리 저속 부하: 메모리 더티율 1-2M/s
- 메모리 고속 부하: 메모리 더티율 11~12M/s
본 논문에서 제안한 마이그레이션 방법 = MBDPC
예측 알고리즘의 성능을 객관적으로 비교하기 위해 MBDPC에서 압축 알고리즘을 제거한 알고리즘 = MBDP
1. 더티 페이지 예측 비교
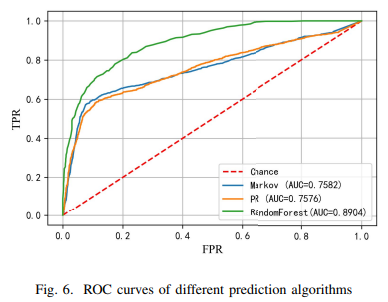
마르코프, PR 예측 알고리즘과 비교했을 때, 본 논문에서 제안하는 더티페이지 예측 알고리즘의 AUC 값이 약 17% 증가하여 더티 페이지 예측 효과가 더 우수하다는 것을 알 수 있다.
- x축: FPR(오탐률)
- y축: TPR(진탐률)
- AUC: 곡선 아래 영역으로, 모델의 전반적인 랭킹 능력을 반영한다. 넓을수록 좋음
2. 다운 타임: 컨테이너가 중지된 후 서비스 복구까지 걸리는 시간 = T stop + T restore
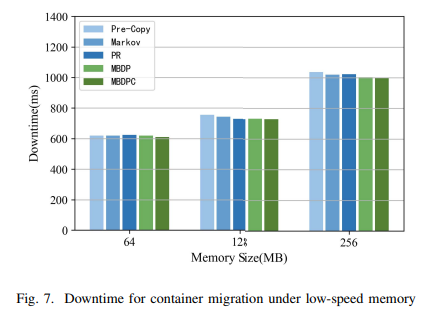
그림은 다양한 메모리 크기일 때, 저속부하에서의 다운 타임을 보여주는데, 기존 사전 복사 알고리즘과 비교했을 때, 마르코프와 PR은 평균 1.1%, 1.3% 감소한 반면, MBDP와 MBDPC는 평균 2.1%, 2.8% 감소했다.
즉, 컨테이너 메모리가 작을 경우 마르코프, PR, MBDP, MBDPC는 최적화 효과가 거의 없는데, = 저속 시나리오에서는 컨테이너 메모리의 수정 속도가 낮기 때문에 1~2회 반복하면 더티 페이지 수가 즉시 종료 조건을 충족하고 종료 마이그레이션 단계로 들어감 (메모리 크기와 메모리 더티율이 낮은 경우 예측 알고리즘에는 일정한 한계가 있다)
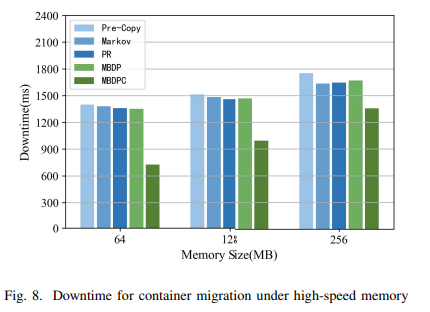
다양한 메모리 크기에서 메모리 고속 부하의 다운타임을 살펴보면, 메모리 더티율이 높을 때 마르코프와 PR은 원본 사전 복사본에 비해 평균 3.3%와 4.1% 감소한 반면, MBDP와 MBDPC는 평균 3.7%와 34.9% 감소했다.
페이지 예측은 반복 프로세스의 속도를 높이고 셧다운 마이그레이션 단계에서 더티 페이지의 수를 줄일 수 있음을 알 수 있으며, MBDPC는 반복 프로세스의 속도를 더 빠르게 할 뿐만 아니라 페이지 압축을 통해 종료 단계에서 전송 시간 Tstop을 크게 단축할 수 있었다.
3. Total Migration Time: 첫 번째 iteration 부터 대상 컨테이너가 컨테이너를 재시작할 때까지의 시간 = ∑T iterative(i) + T stop + T restore
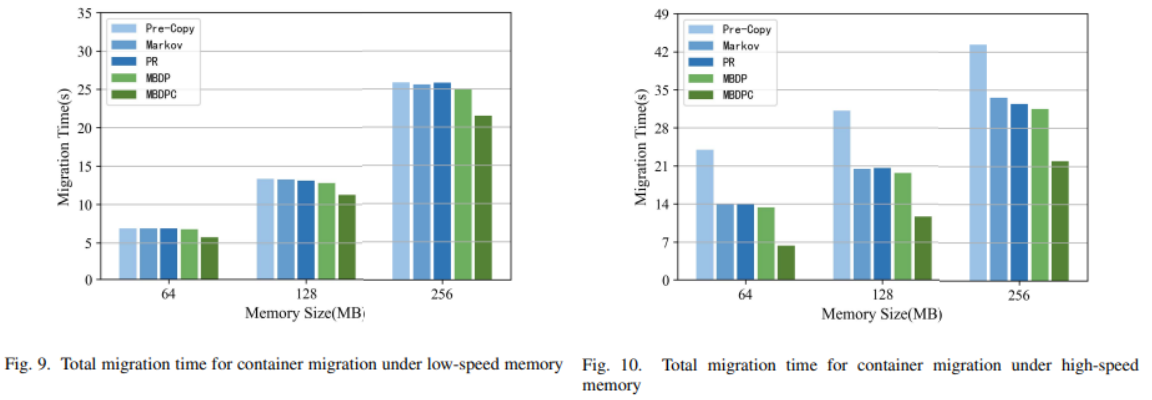
- 저속 부하에서는 페이지 더티율이 낮음
- 마코프와 PR이 원본 프리카피에 비해 총 마이그레이션 시간을 단축하는 효과가 적다
- MBDP와 MBDPC는 평균 3%, 16.5% 단축하여 최적화 효과가 더 높다
- 고속 로드에서는 페이지 더티율이 높다
- 원래의 사전 복사 알고리즘은 높은 더티 페이지를 반복적으로 전송하여 라운드당 더티 페이지 수가 종료 임계값보다 낮아질 수 없다. 따라서 반복 시간 n i=1 Titerative(i)가 길어지고 총 마이그레이션 시간이 증가한다.
- 원본 사전 복사본과 비교하여 예측 알고리즘은 매우 더티한 페이지의 반복 전송을 피함으로써 반복 시간을 줄일 수 있다.
=> 메모리 더티율이 높을 경우 MBDPC가 총 마이그레이션 시간을 더 잘 줄일 수 있다.
4. 총 전송 데이터: 전체 마이그레이션 과정에서 전송된 데이터의 총량 = ∑TD iterative(i) + TD stop
- 앞선 내용들과 마찬가지로 메모리 더티율이 낮으면 iteration 프로세스가 빠르게 멈추기 때문에 마르코프, PR, MBDP 알고리즘의 최적화 효과는 상대적으로 적다.
- 고속 워크로드에서(메모리 더티율이 높으면) 예측 알고리즘은 원본 사전 복사본과 비교하여 반복 과정에서 매우 더티한 메모리 페이지의 반복 전송을 피함으로써 전송되는 데이터의 양을 줄일 수 있다. MBDPC는 페이지 압축을 사용하기 때문에 전송되는 데이터의 총량을 더 줄일 수 있다.
5. iteration 당 전송되는 데이터의 양:
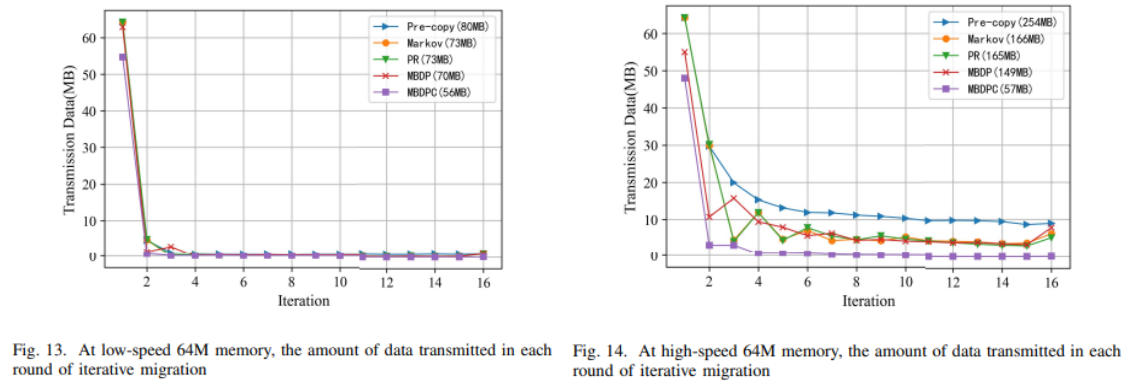
제안한 MBDPC 방식은 각 라운드의 데이터 양과 마지막에 전송되는 총 데이터 양이 다른 알고리즘에 비해 낮다.
메모리 데이터를 미리 수집하고 첫 번째 라운드에서 예측을 하기 때문에 첫 번째 라운드에서 불필요한 페이지 전송을 피할 수 있다.
Discussion
본 논문에서는 머신러닝 기법의 더티 페이지 예측을 기반으로 하는 컨테이너 사전 복사 마이그레이션 방법인 MBDPC를 제안했다.
MBDPC는 프로그램 로컬리티 원리를 이용해 메모리 더티 페이지를 예측하여 페이지가 반복 전송되는 것을 방지했다.
본 논문은 단일 컨테이너의 마이그레이션에 대한 연구이며, 향후 쿠버네티스와 같이 널리 사용되는 컨테이너 오케스트레이션 도구와 결합하여 여러 컨테이너 간의 마이그레이션 문제를 해결하는 방법을 고려하면 좋을 것 같다.
메모리 접근 특성을 분석하여 시스템 내에서 메모리 관리에 사용하는 쪽만 생각했었는데, 이렇게 라이브 마이그레이션에도 사용할 수 있다는 것을 알 수 있었다. 라이브 마이그레이션에서는 아무래도 전송량이 중요하기 때문에 더티페이지 예측 뿐만 아니라 메모리 압축 기술을 사용했나보다