- python3
항공 규정 등에 대한 내용은 특정한 단어들 때문에 기존의 번역기의 성능이 좋지 못한 경향이 있다.
항공 규정에 대한 올바른 번역 쌍을 데이터베이스에 저장하고, 가변 데이터나 오탈자가 들어가더라도 90%이상 데이터베이스에 유사한 cell이 있는 경우 이를 활용하도록 하고, 새로운 내용에 대한 input이 들어올 경우 머신 러닝을 활용하여 번역하도록 한다.

데이터베이스에는 또한 문장에서 추출한 키워드 10개가 (문장, 키워드들)의 쌍으로 저장되어 있다.
유사도를 계산할 때에는 이 키워드를 가지고 계산한다.

input data의 경우 구두점이 존재하지 않거나 줄 바꿈이 일어나지 않는 경우도 많아 머신 러닝 번역의 경우 정확도가 낮게 나오는 문제점이 있으므로, 기존 데이터베이스를 활용하여 특정한 단어가 문장의 처음에 나올 확률/문장의 마지막에 나올 확률 등을 계산하여 문장 segmentation을 진행한다.
문장 segmentation 이후 seq2seq를 적용한 모델을 활용하여 번역한다. (seq2seq with attention model)
성능을 높이기 위해 추가적으로 정규표현식 및 기존의 seq2seq with attention 모델에 domain adaption과 fine-tuning을 적용했다.
항공 corpus는 양이 매우 적기 때문에 overfitting이 발생했고, 주어진 corpus와 다른 형식의 문장은 전혀 번역하지 못하는 문제점이 있었다. 따라서 대량의 일반 corpus와 항공 corpus로 seq2seq 모델을 학습시켰다. 그리고 결과 모델을 항공 corpus 만으로 fine-tuning하여 번역 가능한 문장을 일반화 시켰다.
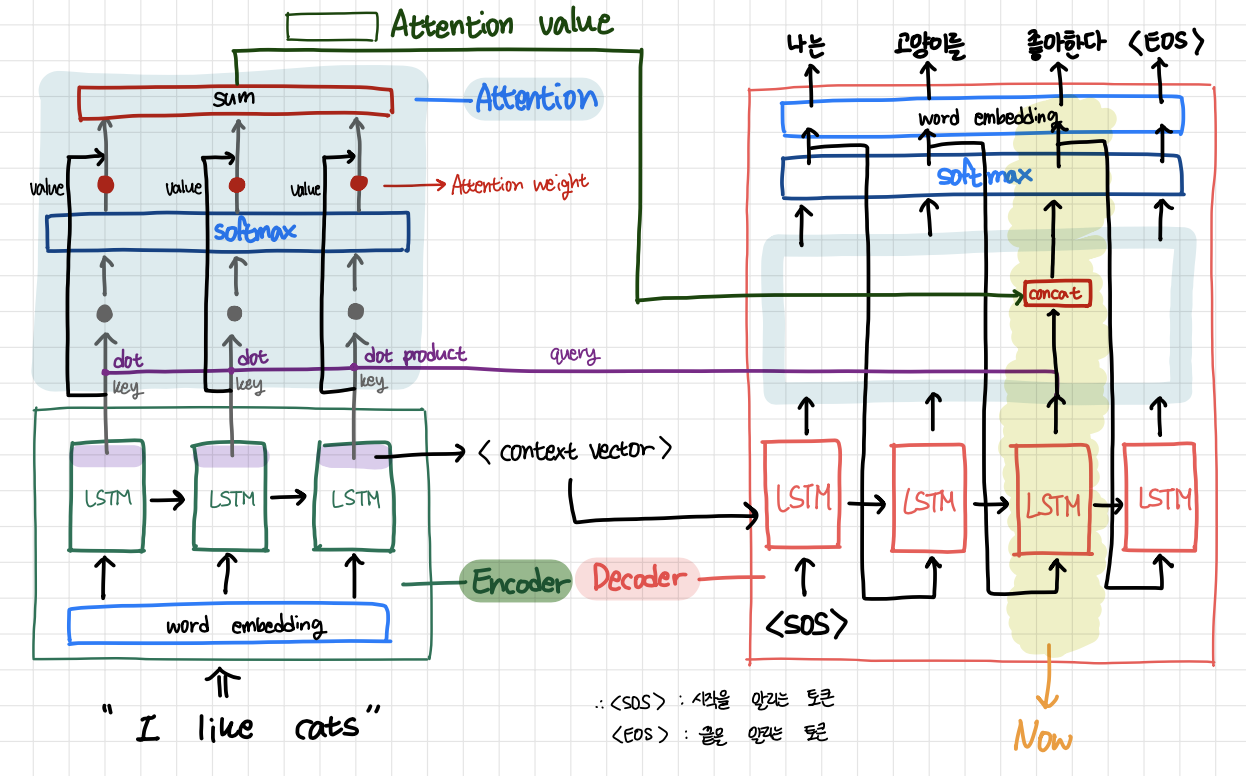
seq2seq는 시계열 데이터(sequence data)를 다른 종류의 시계열 데이터로 바꿔주는 모델로 기계 번역에 자주 사용된다.
- encoder: 입력 시계열 데이터를 LSTM에서 순차적으로 처리하여 하나의 벡터 형태로 정보를 압축한다. 마지막 단어를 입력받은 LSTM의 last hidden laer vector는 context vector로 decoder에 전달된다.
- decoder: 이전 단계의 LSTM hidden layer vector와 이전 단계의 예측 단어 vector를 입력으로 받는다. LSTM에서 반환된 전체 단어 수에 대응되는 shape으로 바뀐다. softmax를 통과하면 각 단어에 대한 확률값을 저장하는 vector로 바뀐다. 가장 높은 값을 갖는 인덱스에 대응되는 단어가 번역된 단어이다.
즉, 인코더는 번역할 문장의 정보를 압축하여 디코더로 보내고, 디코더는 인코더에서 받은 정보와 각 단계에서 예측한 단어들로 다음 단어를 예측한다고 할 수 있다.
attention seq2seq 모델은 seq2seq의 디코더에서 인코더의 hidden layer vector들을 참고하여 단어를 예측하는 모델이다.
- 디코더의 현재 단계의 LSTM이 반환한 vector가 query가 된다.
- 입력 데이터의 각 단어별로 LSTM 마지막 hidden layer vector들이 key 값이자 value 값이 된다.
- query를 각 key 값들을 dot product 하여 vector 쌍들의 유사도를 얻는다.
- 유사도 값들이 softmax를 거치면 어텐션 가중치(attention weight)가 된다. 이들은 각 입력 단어들과 디코더가 예측할 단어의 유사도를 의미한다.
- 어텐션 가중치를 value 값들에 곱하고 모두 더하면 예측할 단어와 유사도가 높을 수록 값이 더 많이 반영된 attention value가 된다.
- 디코더로 돌아와 attention value와 LSTM가 반환한 벡터를 concat한다.
즉, attention이란 인코더의 입력 데이터드로가 현재 예측해야 할 단어의 유사도를 구하여 유사도가 높은 입력 데이터들에 큰 비중을 두어 참고하는 방법이다.
이 프로젝트에서 어려웠던 점은 input이 문장단위로 들어오는 것이 아니라 1줄 당 64바이트로 이루어진 스트림으로 들어오기 때문에 문장의 단위를 나누고 이를 번역기에 넣는 것이 가장 어려웠다. 또한, 일반적인 문서에서 찾아볼 수 없는, 문장의 구두점이 없는데도 문장의 의미가 나누어져서 문장 segmentation을 어떻게 해야할 것인지 많은 고민을 해야 했다.
뿐만 아니라, regular expression을 이용한 가변 데이터를 처리할 때, 화폐, 퍼센트, 기간, 날짜, 서수 등에 대한 내용에 대해 가변 데이터 전처리를 하는데 그 모양이 너무 다양하여 예외 케이스가 많은 점이 어려웠다.
keyword matching을 알아보기 위해 데이터베이스에서 유사한 번역 쌍을 찾을 때에도 데이터베이스 전체 조회에 대한 시간이 오래 걸려서 문제가 됐다. 이는 처음에 데이터베이스 전체를 조회하여 캐싱해두고 input cell 이 들어올 때마다 캐싱 된 데이터베이스 테이블의 키워드와 인풋 cell의 키워드를 각각 full-scanning하며 비교하도록 함으로써 해결했다.
'프로젝트' 카테고리의 다른 글
| 토이 프로젝트: 이화이언 따라 만들어 보기 (2) | 2020.07.26 |
|---|---|
| Emotion Analyze Speaker (0) | 2020.07.10 |