위 글에서 볼 수 있듯이 HashMap은 해시코드가 다른 엔트리끼리는 동치성 비교를 시도조차 하지 않도록 최적화되어 있다.
그렇다면 올바른 해시코드를 리턴하기 위한 방법은 무엇일까?
만약 해시코드가 모두 동일한 값을 리턴한다면, HashMap에서는 모든 객체가 해시테이블의 버킷 하나에 담겨 마치 연결 리스트(linked list)처럼 동작한다. 그 결과 평균 수행 시간이 0(1)인 해시테이블이 O(n)으로 느려져서, 객체가 많아지면 도저히 쓸 수 없게 된다. 좋은 해시 함수라면 서로 다른 인스턴스에 다른 해시코드를 반환한다. 아까 보았던 hashCode 규약 3번이다. 이상적인 해시 함수는 주어진 (서로 다른) 인스턴스들을 32비트 정수 범위에 균일하게 분배해야 한다.
int 변수 result를 선언한 후 값 c로 초기화한다. (c는 해당 객체의 첫 번째 핵심 필드를 단계 2번 방식으로 계산한 해시코드)
핵심 필드: equals 비교에 사용되는 필드를 말한다. (아이템 10)
해당 객체의 나머지 핵심 필드 주 각각에 대해 다음 작업을 수행한다.
해당 필드의 해시코드 c를 계산한다.
기본 타입 필드라면, Type.hashCode(f)를 수행한다. 여기서 Type은 해당 기본 타입의 박싱 클래스다.
참조 타입 필드면서 이 클래스의 equals 메서드가 이 필드의 equals 를 재귀적으로 호출해 비교한다면, 이 필드의 hashCode를 재귀적으로 호출한다. 계산이 더 복잡해질 것 같으면, 이 필드의 표준형(canonical representation)을 만들어 그 표준형의 hashCode를 호출한다. 필드의 값이 null이면 0을 사용한다(다른 상수도 괜찮지만 전통적으로 0을 사용)
필드가 배열이라면, 핵심 원소 각각을 별도 필드처럼 다룬다. 규칙을 재귀적으로 적용해 각 핵심 원소의 해시코드를 계산한 다. 배열에 핵심 원소가 하나도 없다면 단순히 상수(일반적으로 0)를 사용한다. 모든 원소가 핵 심 원소라면 Arrays. hashCode 를 사용한다.
단계 2.a에서 계산한 해시코드 c로 result를 갱신한다. 코드로는 다음 과 같다.
result = 31 * result + c;
result를반환한다.
이때, equals 비교에 사용되지 않은 필드는 반드시 제외해야 한다. 그렇지 않으면 hashCode 규약 2번을 어기게 될 수 있다.
아래는 위 규칙에 따라 샘플로 만든 해시 코드이다.
@Override
public int hashCode() {
int result = Short.hashCode(areaCode);
result = 31 * result + Short.hashCode(prefix);
result = 31 * result + Short.hashCode(lineNum);
return result;
}
여기서 왜 31을 곱해야 하는지에 대한 생각은 스터디원이 잘 정리해 주어서 많은 도움이 됐다.
위 방식 외에도 Objects 클래스의 임의의 개수만큼 객체를 받아 해시코드를 계산해주는 정적 메서드인 hash를 사용할 수도 있다.
@Override
public int hashCode() { return Objects.hash(lineNum, prefix, areaCode); }
하지만 성능상 좋진 않다. 여러 입력 인수를 담기 위한 배열이 만들어지고, 입력 중 기본 타입이 있다면 박싱과 언박싱도 거쳐야 하기 때문이다.
클래스가 불변이고, 해시코드를 계산하는 비용이 크다면, 매번 새로 계산하기 보다는 캐싱하는 방식을 고려해야 한다.
이 타입의 객체가 주로 해시의 키로 사용될 것 같다면 인스턴스가 만들어질 때 해시코드를 계산해둬야 한다.
만약 해시의 키로 사용되지 않는 경우라면 hashCode가 처음 불릴 때 계산하는 지연 초기화(lazy initialization) 전략을 사용할 수도 있다. 이 경우에는 클래스를 스레드 안전하게 만들도록 신경 써야 한다(아이템 83).
예시는 아래와 같다. 주의할 점은 hashCode 필드의 초깃값은 흔히 생성되는 객체의 해시코드와는 달라야 한다는 점이다.
private int hashCode; // 자동으로 0으로 초기화된다.
@Override
public int hashCode() {
int result = hashCode;
if (result == 0) {
result = Short.hashCode(areaCode);
result = 31 * result + Short.hashCode(prefix);
result = 31 * result + Short.hashCode(lineNum); hashCode = result;
}
return result;
}
항진 명제: 논리식 혹은 합성명제에 있어 각 명제의 참·거짓의 모든 조합에 대하여 항상 참인 것
즉, 쉽게 말하면 인스턴스들 끼리 equals() 메서드를 사용해서, 논리적으로 같은지 검사할 필요가 없는 경우에는 Object의 기본 equals 로만으로도 해결한다.
상위 클래스에서 재 정의한 equals가 하위 클래스에도 적용되는 경우
HashSet, TreeSet, EnumSet 등 대부분의 Set 구현체 - AbstractSet 에서 정의된 equals 사용
ArrayList, Vector 등 대부분의 List 구현체 - AbstractList 에서 정의된 equals 사용
HashMap, TreeMap, EnumMap 등 대부분의 Map 구현체 - AbstractMap 에서 정의된 equals 사용
클래스가 private이거나 package-private이고, equals 메소드를 호출할 일이 없는 경우
equals 메서드를 오버라이딩해서 호출되지 않도록 막자
@Override
public boolean equals(Object o) {
throw new AssertionError(); // 메서드 호출 방지
}
equals를 재정의해야 하는 경우는 두 객체가 물리적으로 같은지 비교할 때가 아니라, 논리적 동치성을 확인해야 하며, 상위 클래스의 equals가 현재 클래스의 논리적 동치성을 비교하기에 적절하지 않을 경우이다.
주로 값 클래스들이 여기 해당하는데, 값 클래스란 Integer와 String처럼 값을 표현하는 클래스를 말한다.
값 객체의 equals를 재정의 하여 논리적 동치성을 확인하도록 하면, 인스턴스의 값을 비교할 수 있고, Map의 키와 Set의 원소로도 사용할 수 있게 된다.
만약 값 클래스라 하더라도 싱글톤이면 equals를 재정의하지 않아도 된다. Enum(아이템 34)도 여기에 해당한다.
이런 클래스에서는 어차피 논리적으로 같은 인스턴스가 2개 이상 만들어지지 않기 때문에 논리적 동치성과 객체 식별성이 사실상 똑같은 의미가 된다. 따라서 Object의 equals가 논리적 동치성까지 확인 해준다고 볼 수 있다.
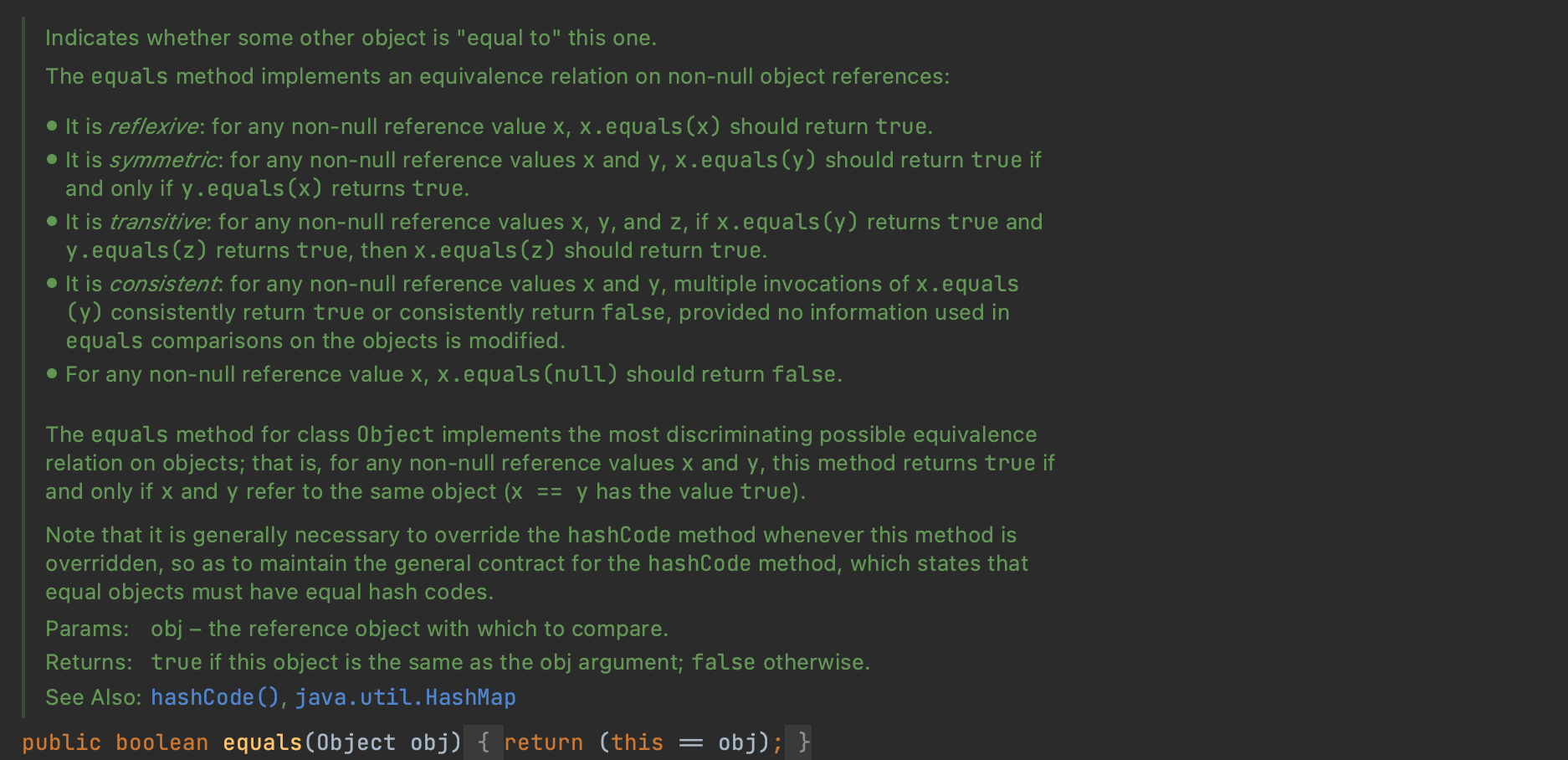
equals 메소드를 재 정의할 때에는 동치관계(equivalence relation)를 만족해야한다.
1. 반사성(reflexivity): null이 아닌 모든 참조 값 x에 대해, x.equals(x) = true
객체는 자기 자신과 같아야 한다는 의미를 가진다.
2. 대칭성(symmetry): null이 아닌 모든 참조 값 x, y에 대해, x.equals(y) = true 이면 y.equals(x) = true
두 객체는 서로에 대한 동치 여부에 똑같이 답해야 한다는 의미이다. 이는 서로 다른 클래스의 객체를 비교할 때 위반될 수 있다.
예를 들어 아래와 같은 CaseInsensitiveString 을 정의 했을 때,
public final class CaseInsensitiveString {
private final String s;
public CaseInsensitiveString(String s) {
this.s = Objects.requireNonNull(s);
}
@Override
public boolean equals(Object o) {
if( o instanceof CaseInsensitiveString) {
return s.equalsIgnoreCase((CaseInsensitiveString) o).s);
}
if ( o instanceof String) {
return s.equalsIgnoreCase((String) o);
}
}
}
실행 결과는 아래와 같이 다른 값을 반환하게 된다. 그 이유는CaseinsensitiveString의 equals는 일반 String을 알고 있지만, String의 equals는 Case InsensitiveString의 존재를 모르기 때문이다.
CaseInsensitiveString cis = new CaseInsensitiveString("Media");
String s = "media";
cis.equals(s); // true
s.equals(cis); // false
3. 추이성(transitivity): null이 아닌 모든 참조 값 x, y, z에 대해, x.equal이(y)=true 이고 y.equals(z)=true 이면 x.equals(z) = true
추이성의 경우 상위 클래스에는 없는 새로운 필드를 하위 클래스에 추가하는 상황에서 위반될 수 있다.
예를 들어 아래와 같이 2차원의 점을 표현하는 Point 클래스와 이를 확장한 ColorPoint 클래스를 정의해 보자.
class Point {
private final int x;
private final int y;
public Point(int x, int y) {
this.x = x;
this.y = y;
}
@Override
public boolean equals(Object o) {
if (!(o instanceof Point)) {
return false;
}
Point p = (Point) o;
return p.x == x && p.y == y;
}
}
public class ColorPoint extends Point {
private final Color color;
public ColorPoint(int x, int y, Color color) {
super(x, y);
this.color = color;
}
@Override
public boolean equals(Object o) {
if (!(o instanceof Point)) {
return false;
}
// o가 일반 Point 이면 색상을 무시하고 비교한다.
if (!(o instanceof ColorPoint)) {
return o.equals(this);
}
// o가 ColorPoint 이면 색상까지 비교한다.
return super.equals(o) && ((ColorPoint) o).color == color;
}
}
이 경우 ColorPoint에서 equals를 재정의 하지 않으면 색상 정보는 무시한 채 비교를 수행하게 된다.
또한, 위와 같이 equals를 재정의 하게 되면 추이성을 위배하게 된다.
p1p2 와 p2p3 비교에서는 색상을 무시했지만, p1p3 비교에서는 색상까지 고려했기 때문이다.
ColorPoint p1 = new ColorPoint(1, 2, Color.RED);
Point p2 = new Point(1, 2);
ColorPoint p3 = new ColorPoint(1, 2, Color.BLUE);
pl.equals(p2); // true
p2.equals(p3); // true
pl.equals(p3); // false
사실객체 지향적 추상화의 이점을 포기하지 않는 한, 구체 클래스를 확장해 새로운 값을 추가하면서 equals 규약을 만족시킬 방법은 존재하지 않는다.
equals 안의 instanceof 검사를 getClass 검사로 바꾸면 가능하다고 생각할 수도 있다. 하지만, 이 경우는 같은 구현 클래스의 객체와 비교할 때만 true를 반환하게 된다.
=> Point의 하위 클래스는 정의상 여전히 Point이므로 어디서든 Point로써 활용될 수 있어야 한다. (리스코프 치환 원칙)
자바 라이브러리에도 구체 클래스를 확장해 값을 추가한 클래스가 종종 있다. java.util.Date와 java.util.Timestamp 관계가 이와 같다. 그래서 Timestamp의 equals는 대칭성을 위배하며 , Date 객체와 한 컬렉션에 넣거나 서로 섞어 사용하면 엉뚱하게 동작할 수 있다. 아래는 javadocs에 기술되어 있는 주의점이다.
The reason that I favor the instanceof approach is that when you use the getClass approach, you have the restriction that objects are only equal to other objects of the same class, the same run time type. If you extend a class and add a couple of innocuous methods to it, then check to see whether some object of the subclass is equal to an object of the super class, even if the objects are equal in all important aspects, you will get the surprising answer that they aren't equal. In fact, this violates a strict interpretation of the Liskov substitution principle, and can lead to very surprising behavior. In Java, it's particularly important because most of the collections (HashTable, etc.) are based on the equals method. If you put a member of the super class in a hash table as the key and then look it up using a subclass instance, you won't find it, because they are not equal. Because of these problems, I didn't even bother discussing the getClass approach. But it turns out that because it does let you add aspects while preserving the equals contract, some people favor it. So I just want to get the information out there that it has disadvantages too. The biggest disadvantage is the fact that you get two objects that appear equal (because they are equal on all the fields) but they are not equal because they are of different classes. This can cause surprising behavior. I'm going to write an essay discussing this in more detail. When it's done, I'll put it up on the book's web site. It will compare the two approaches and discuss the pros and cons.
Bill Venners: The reason I have used getClass in the past is because I don't know what is going to happen in subclasses. I can't predict that when I am writing my class. It seemed risky to me to use instanceof. If I used instanceof and someone passed a subclass instance to my superclass equals method, I would determine semantic equality by comparing only fields that exist in the superclass. I'd be ignoring any fields declared in subclasses, and it seems like they could be important to the notion of semantic equality for the subclass. The other way to look at it I guess is that using instanceof in a superclass equals method makes it harder to write subclasses, because equals is supposed to be symmetric. If you call the subclass's equals method implementation, passing in an instance of the superclass, it must return the same result as if you passed the subclass instance to the superclass's equals method.
Josh Bloch: Yes. You are correct in saying that using getClass in equals makes it much easier to preserve the equals contract, but at what cost? Basically, at the cost of violating the Liskov substitution principle and the principle of least astonishment. You write something that obeys the contract, but whose behavior can be very surprising.
정리하자면, instanceof 접근 방식을 선호하는 이유는 getClass 접근 방식을 사용할 때 객체가 동일한 런타임 유형인 동일한 클래스의 다른 객체와 만 동일하다는 제한이 있기 때문이다. 클래스를 확장하고 몇 가지 메서드를 추가하면 하위 클래스의 일부 객체가 수퍼 클래스의 객체와 동일한 지 확인하게 된다.
Java에서는 대부분의 컬렉션 (HashTable 등)이 equals 메소드를 기반으로하기 때문에 특히 중요한데, getClass 를 사용하게 되면 슈퍼 클래스의 멤버를 키로 해시 테이블에 넣은 다음 하위 클래스 인스턴스를 사용하여 조회하면 같지 않기 때문에 찾을 수 없게 될 수도 있다.
+) 추가적으로 추상클래스에서라면 equals 메소드 재정의로 해결 가능하다
4. 일관성(consistency): nuII이 아닌 모든 참조 값 x, y에 대해, x.equals(y)를 반복해서 호출하면 항상 같은 값을 반환
두 객체가 같다면 (어느 하나 혹은 두 객체 모두가 수정되지 않는 한) 앞으로도 영원히 같아야 한다는 의미이다.
또한, 클래스가 불변이든 가변이든 equals의 판단에 신뢰할 수 없는 자원이 끼어 들게 해서는 안 된다.
ex) java.net.URL의 equals는 URLStreamHandler를 이용하여 주어진 URL과 매핑된 호스트의 IP 주소 를 이용해 비교한다.
호스트 이름을 IP 주소로 바꾸려면 네트워크를 통해야 하 는데, 그 결과가 항상 같다고 보장할 수 없다.
URL.equalsURLStreamHandler.equals
=> 이런 문제를 피하려면 equals는 항시 메모리 에 존재하는 객체만을 사용한 결정적 (deterministic) 계산만 수행해야 한다.
5. null-아님: null이 아닌 모든 참조 값 x에 대해, x.equals(null)은 false다.
이름처럼 모든 객체가 null과 같지 않아야 한다는 의미이다.
특히 NullPointerException을 던지는 방식이 자주 발생할 수 있는데, equals에서는 이런 경우도 허용하지 않는다.
이 때, 명시적 null 검사를 하기 보다는 아래와 같이 건네받은 객체를 적절히 형변환한 후 필수 필드들의 값을 알아내도록 한다.
(이를 위해서는 형변환에 앞서 instanceof 연산자로 입력 매개변수가 올바른 타입 인지 검사해야 한다.)
+ equals가 타입을 확인하지 않으면 잘못된 타입이 인수로 주어졌을 때 Class CastException을 던져서 일반 규약을 위배하게 된다.
=> instanceof는 (두 번째 피 연산자와 무관하게) 첫 번째 피 연산자가 null이면 false를 반환한 다. 따라서 입력이 null이면 타입 확인 단계에서 false를 반환하 기 때문에 null 검사를 명시적으로 하지 않아도 된다.
Object 클래스의 equals를 살펴보면 재 정의 시 위의 동치관계들을 모두 만족해야 함을 알 수 있다.
만약 아래 equals 규약을 어기면 그 객체를 사용하는 다른 객체들이 어떻게 반응할지 알 수 없다.
Object.equals
위의 내용들을 정리하여 equals 메소드에 대한 재정의를 단계별로 알아보자
public final class phoneNumber {
private final short areaCode, prefix, lineNum;
@Override
public boolean equals(Object o) {
if( o == this) { // 1. == 연산자를 사용해 입력이 자기 자신의 참조인지 확인
return true;
}
if( o == null) { // 널 체크
return false;
}
if(!(o instanceof PhoneNumber)) { // 2. instanceof 연산자로 입력이 올바른 타입인지 확인
return false;
}
PhoneNumber pn = (PhoneNumber)o; // 3. 입력을 올바른 타입으로 형변환
return pn.lineNum == lineNum && pn.prefix == prefix
&& pn.areaCode == areaCode; // 4. 입력 객체와 자기 자신의 대응되는 핵심 필드들이 모두 일치하는지 하나씩 검사
}
}
1. == 연산자를 사용해 입력이 자기 자신의 참조인지 확인한다.
자기 자신이 면 true를 반환한다. 이는 단순한 성능 최적화용으로, 비교 작업이 복잡한 상황일 때 값어치를 할 것이다.
2. instanceof 연산자로 입력이 올바른 타입인지 확인한다. 그렇지 않다면 false를 반환한다.
이때의 올바른 타입은 equals가 정의된 클래스인 것이 보통이지만, 가끔은 그 클래스가 구현한 특정 인터페이스가 될 수도 있다. 어떤 인터페이스는 자신을 구현한 (서로 다른) 클래스끼리도 비교할 수 있 도록 equals 규약을 수정하기도 한다. 이런 인터페이스를 구현한 클래스라면 equals에서 (클래스가 아닌) 해당 인터페이스를 사용해야 한다.
ex) Set, List, Map, Map.Entry 등
3. 입력을 올바른 타입으로 형변환한다.
4. 입력 객체와 자기 자신의 대응되는 ‘핵심’ 필드들이 모두 일치하는지 하나씩 검사한다.
모든 필드가 일치하면 true를, 하나라도 다르면 false를 반환
=> 2단계에서 인터페이스를 사용했다면 입력의 필드 값을 가져올 때도 그 인터페이스의 메서드를 사용해야 한다.
타입이 클래스라면 (접근 권한 에 따라) 해당 필드에 직접 접근할 수도 있다.
주의할 점은 float와 double을 제외한 기본 타입 필드는 == 연산자로 비교하고, 참조 타입 필드는 각각의 equals 메서드로,
float와 double 필드는 각각 정적 메서드인 XXX.compare(x1, x2)로 비교한다. (Nan, -0.0f, 특수한 부동소수 값 등을 다뤄야 하기 때문)
=> XXX.equals를 대신 사용할 수 있으나, 이 경우에는 오토박싱을 사용하게 되어서 성능 상 좋지 않다.
+) null도 정상 값으로 취급하는 참조 타입 필드의 경우는 Object.equals를 사용하도록 한다. (NullPointerException 발 생을 예방)
만약 CaselnsensitiveString 처럼 복잡한 필드를 가진 클래스를 비교할 때에는 필드의 표준형(canonical form)을 저장해둔 후, 표준형끼리 비교하면 훨씬 경제적이다. 이 기법은 특히 불변 클래스(아이템 17)에 좋다.
어떤 필드를 먼저 비교하느냐가 equals의 성능을 좌우하므로 다를 가능성이 더 크거나 비교하는 비용이 싼 필드를 먼저 비교하자.
동기화용 락(lock) 필드 같이 객체의 논리적 상태와 관련 없는 필드는 비교하면 안 된다. 핵심 필드로부터 계산해낼 수 있는 파생 필드 역시 굳이 비교할 필요는 없지만, 파생 필드를 비교하는 쪽이 더 빠 를 때도 있다. 파생 필드가 객체 전체의 상태를 대표하는 상황이 그렇다.
ex) 자신의 영역을 캐시해두는 Polygon 클래스의 경우
=> 모든 변과 정점을 일일이 비교할 필요 없이, 캐시해둔 영역만 비교하면 결과를 바로 알 수 있다.
추가적으로 알아둘 점은,
equals를 재정의할 땐 hashCode도 반드시 재정의하자(아이템 11)
너무 복잡하게 해결하려 하지 말자. 필드들의 동치성만 검사해도 된다. alias 등은 무시하자.
Object 외의 타입을 매개변수로 받는 equals 메서드는 선언하지 말자. (입력 타입이 Object가 아니므로 재정의가 아니라 다중정의임)
class MyClass {
public boolean equals(MyClass o) { // 재정의가 아니라 다중정의이다
// -> 따라서 여기에 @Override 애노테이션을 붙이면 컴파일 에러 발생함
}
}
용어
리스코프 치환 원칙 (Liskov substitution principle): 어떤 타입에 있어 중요한 속성이라면 그 하위 타입에서도 마찬가지로 중요하다. 따라서 그 타 입의 모든 메서드가 하위 타입에서도 똑같이 잘 작동해야 한다. => 서브타입은 언제나 자신이 기반타입 (base type)으로 교체할 수 있어야 한다.
list 내의 원소들이 순서를 바꾸어도 같은 객체로 인식해야하기 때문에 정렬을 해서 넣어주도록 했다.
import java.util.*;
import java.util.stream.Collectors;
public class Solution {
public static List<List<Integer>> fourSum(int[] nums, int target) {
int length = nums.length;
HashSet<List<Integer>> answer = new HashSet<List<Integer>>();
for (int i = 0; i < length; i++) {
for (int j = i + 1; j < length; j++) {
if (i == j) {
continue;
}
for (int k = j + 1; k < length; k++) {
if (i == k || j == k) {
continue;
}
for (int l = k + 1; l < length; l++) {
if (i == l || j == l || k == l) {
continue;
}
if (nums[i] + nums[j] + nums[k] + nums[l] == target) {
List<Integer> subAnswer = Arrays.asList(nums[i], nums[j], nums[k], nums[l]);
Collections.sort(subAnswer);
answer.add(subAnswer);
}
}
}
}
}
System.out.println(answer.size());
return answer.stream().collect(Collectors.toList());
}
}
최적화
투 포인터를 이용해서 O(N^4)를 줄여보자
public List<List<Integer>> fourSum(int[] nums, int target) {
Arrays.sort(nums);
return kSum(nums, target, 0, 4);
}
public List<List<Integer>> kSum(int[] nums, int target, int start, int k) {
List<List<Integer>> res = new ArrayList<>();
if (start == nums.length || nums[start] * k > target || target > nums[nums.length - 1] * k)
return res;
if (k == 2)
return twoSum(nums, target, start);
for (int i = start; i < nums.length; ++i)
if (i == start || nums[i - 1] != nums[i])
for (var set : kSum(nums, target - nums[i], i + 1, k - 1)) {
res.add(new ArrayList<>(Arrays.asList(nums[i])));
res.get(res.size() - 1).addAll(set);
}
return res;
}
public List<List<Integer>> twoSum(int[] nums, int target, int start) {
List<List<Integer>> res = new ArrayList<>();
int lo = start, hi = nums.length - 1;
while (lo < hi) {
int sum = nums[lo] + nums[hi];
if (sum < target || (lo > start && nums[lo] == nums[lo - 1]))
++lo;
else if (sum > target || (hi < nums.length - 1 && nums[hi] == nums[hi + 1]))
--hi;
else
res.add(Arrays.asList(nums[lo++], nums[hi--]));
}
return res;
}
배운점
비슷하게 hashset안에 int[]를 넣어서 해봤을 때에는 왜 틀릴까?
import java.util.*;
import java.util.stream.Collectors;
public class Solution {
public static List<List<Integer>> fourSum(int[] nums, int target) {
int length = nums.length;
HashSet<int[]> answer = new HashSet<int[]>();
for (int i = 0; i < length; i++) {
for (int j = i + 1; j < length; j++) {
if (i == j) {
continue;
}
for (int k = j + 1; k < length; k++) {
if (i == k || j == k) {
continue;
}
for (int l = k + 1; l < length; l++) {
if (i == l || j == l || k == l) {
continue;
}
if (nums[i] + nums[j] + nums[k] + nums[l] == target) {
int[] subAnswer = new int[4];
subAnswer[0] = nums[i];
subAnswer[1] = nums[j];
subAnswer[2] = nums[k];
subAnswer[3] = nums[l];
Arrays.sort(subAnswer);
answer.add(subAnswer);
}
}
}
}
}
return answer.stream()
.map(i -> Arrays.stream(i).boxed().collect(Collectors.toList()))
.collect(Collectors.toList());
}
}
결과 - HashSet이 같은 배열임을 인식하지 못한다. (지금 생각해보면 당연한 소리임...)
일단 hashSet 클래스를 보면 결국 HashMap을 이용해서 push하는 것과 같다.
private transient HashMap<E,Object> map;
/**
* Adds the specified element to this set if it is not already present.
* More formally, adds the specified element {@code e} to this set if
* this set contains no element {@code e2} such that
* {@code Objects.equals(e, e2)}.
* If this set already contains the element, the call leaves the set
* unchanged and returns {@code false}.
*
* @param e element to be added to this set
* @return {@code true} if this set did not already contain the specified
* element
*/
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
HashMap의 put 함수는 아래와 같이 구현되는데, 같은 객체인지 판단할 때 hashCode를 사용함을 알 수 있다.
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with {@code key}, or
* {@code null} if there was no mapping for {@code key}.
* (A {@code null} return can also indicate that the map
* previously associated {@code null} with {@code key}.)
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* Implements Map.put and related methods.
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
/**
* Basic hash bin node, used for most entries. (See below for
* TreeNode subclass, and in LinkedHashMap for its Entry subclass.)
*/
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
ArrayList 컬렉션에서는 이 hashCode를 오버라이드 하고 있었기 때문에,
오버라이드 된 해시코드를 사용하여 값이 같으면 동일 객체임을 판별할 수 있었던 것이다.
/**
* {@inheritDoc}
*/
public int hashCode() {
int expectedModCount = modCount;
int hash = hashCodeRange(0, size);
checkForComodification(expectedModCount);
return hash;
}
ArrayList hashCode docs
ArrayList에서는 해시코드를 entity의 해시코드의 합으로 정의하고 있다.
즉, ArrayList<Integer>의 해시코드는 Integer 의 해시코드들을 사용하여 만드는데, Integer에서 정의된 해시코드의 경우
값이 같은 경우 같은 해시코드를 갖게 된다.
/**
* Returns a hash code for an {@code int} value; compatible with
* {@code Integer.hashCode()}.
*
* @param value the value to hash
* @since 1.8
*
* @return a hash code value for an {@code int} value.
*/
public static int hashCode(int value) {
return value;
}
결론적으로, ArrayList<Integer>의 경우 순서가 동일하고, 같은 값을 가진 리스트의 경우 같은 해시코드 값을 갖게 되어 hashSet에 들어갈 때 중복제거가 가능하다.
이와 달리 int[]의 경우 hashCode가 정의되어 있지 않기 때문에 부모 클래스, 즉 Node에 정의되어 있는 hashCode를 사용하게 된다.