💡 요약
- abstract: "단일" 엣지 서버에서 애플리케이션의 실행 효율을 향상시키기 위한 연구
- introduction: 엣지 서버의 경우 리소스가 제한되어 있으며 다양한 물리 환경을 가지기 때문에 가벼운 컨테이너 가상화가 적합한데, 컨테이너 간 통신 및 데몬 프로세스에 의한 컨테이너 관리로 인해 상당한 CPU 리소스가 소모되는 문제가 있다.
- related work: 엣지 서버들과와 클라우드에서의 워크로드 스케줄링을 통해 태스크 실행 효율을 향상시키는 조사 & 베어메탈 기반 머신에서의 시나리오 조사 -> 단일 엣지 서버에서 컨테이너에 대한 효율 향상에 관한 연구는 없었음
- method: 공동 태스크 스케줄링 및 컨테이너화 기법을 제시
- experiment: 광범위한 시뮬레이션을 통해 평가한 결과, 비효율적인 컨테이너 운영을 줄이고 애플리케이션의 실행 효율을 60%까지 향상
- conclusion & discussion: JTSC 체계는 비효율적인 컨테이너 운영을 줄이고 다양한 요구사항을 충족하면서 애플리케이션의 실행 효율성을 향상시키는 것을 보였지만, 더 복잡한 시나리오에서 테스트 할 여지가 있다.
Introduction
엣지 서버의 경우 리소스가 제한되어 있으며 다양한 물리 환경을 가진다. 또한 지능형 교통, 비디오 분석, 증강 현실, 스마트 홈 등 다양한 애플리케이션을 지원하므로 소프트웨어 종속성 충돌을 피하기 위해 가상화가 좋은 방법이 될 수 있다.
컨테이너는 가상화 기술의 한 종류로, 하나의 운영 체제 커널을 공유하면서 독립적인 파일 시스템과 환경을 갖는 프로세스를 격리하여 실행하는 기술이다. 이러한 컨테이너 기술을 엣지 환경에서 사용하는 경우,
- 경량화된 실행 환경: 컨테이너는 가상화 기술 중에서 가장 경량화된 기술이기 때문에, 엣지 디바이스와 같이 자원이 제한된 환경에서도 효율적으로 실행될 수 있다.
- 격리된 실행 환경: 컨테이너는 독립적인 파일 시스템과 환경을 갖기 때문에, 서로 다른 애플리케이션을 격리된 환경에서 실행할 수 있다. 이를 통해 애플리케이션 간의 상호작용을 방지하고, 보안성을 강화할 수 있다.
- 확장성: 컨테이너는 쉽게 생성, 복제, 이동, 삭제 등의 작업을 수행할 수 있기 때문에, 엣지 환경에서 애플리케이션을 확장하거나 축소하는 것이 용이하다.
가벼운 컨테이너 가상화를 통해 소프트웨어 의존성을 피할 수 있는는데, 컨테이너 간 통신 및 데몬 프로세스에 의한 컨테이너 관리로 인해 상당한 CPU 리소스가 소모되는 문제가 있다.

예비 실험을 통해 확인해 본 결과, (a) 컨테이너 간 통신의 경우 컨테이너 내 통신과 비슷한 전송 속도일때, CPU 사용률이 낮다. (b) 더 많은 태스크가 컨테이너에서 시작될 때, 데몬 프로세스가 더 많은 리소스를 소비한다.
컨테이너의 효율성을 개선하기 위해서는 두 가지가 있는데, 이 논문에서는 기존 컨테이너 시스템을 변경할 필요가 없는 후자의 방법을 택한다.
1. 커스터마이징 된 컨테이너를 통해 컨테이너 작업에 소모되는 CPU 리소스를 줄이는 방법
2. 비효율적인 컨테이너 작업의 사용량을 줄이는 방법
비효율적인 컨테이너 작업은 애플리케이션 작업의 스케줄링과 작업-컨테이너 간의 매핑 체계에 따라 달라지므로, 비효율적인 컨테이너 작업을 줄이기 위해서는 스케줄링과 컨테이너화를 함께 고려해야 한다.
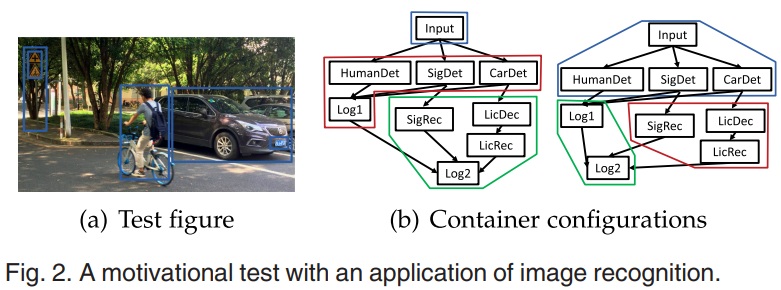
예를 들어, 이미지 인식 애플리케이션 (a)는 (b)와 같은 다양한 작업으로 이루어져 있다. 각 작업을 컨테이너로 나눌 때, 오른쪽 방식이 왼쪽 방식에 비해 컨테이너 간 통신을 74%, 데몬 프로세스에서 사용하는 CPU 리소스를 29% 줄일 수 있다. 또한, 오른쪽 방식이 왼쪽 방식보다 작업 시간이 더 짧게 걸린다.
따라서 본 논문은 컨테이너 작업을 최적화 하기 위해 애플리케이션의 구성(태스크 간의 관계)을 나타내는 애플리케이션 모델을 구축하고, 태스크와 컨테이너에 의한 각각의 CPU 자원 사용률과 태스크의 실행 시간을 보여주는 실행 모델을 구축한다. 그리고 이러한 모델을 기반으로 공동 작업 스케줄링 및 컨테이너화(JTSC) 체계를 설계하고 있다.
논문이 기여한 바는 아래와 같다:
- 단일 엣지 서버에서 컨테이너 작업에 사용되는 CPU 리소스를 정량화하고, 작업 실행에 미치는 영향을 분석한다.
- 컨테이너화 프레임워크 및 알고리즘은 컨테이너화 체계와 작업 스케줄링을 결정함으로써, 컨테이너 작업량 및 애플리케이션의 실행 시간을 낮게 유지하도록 설계했다.
Backgrounds
2.1.1. 컨테이너

컨테이너와 가상 머신은 단일 리소스를 '가상화'하여 여러 리소스로 나타낼 수 있는 프로세스이다.
가상 머신이 전체 머신을 하드웨어 계층까지 가상화하고, 컨테이너는 운영 체제 레벨 위의 소프트웨어 계층만 가상화한다.
따라서 컨테이너는 가상 머신에 비해 호스트와 OS 커널을 공유하기때문에 더 가볍다. 격리된 환경은 namespace와 cgroup이라는 두 가지 OS 매커니즘을 통해 제공된다.
- namespace: 호스트 이름과 도메인 이름, 파일 마운트 지점, 프로세스 간 통신(IPC) 관련 정보, 프로세스 ID(PID), 네트워크 스택, 사용자 등 서로 다른 컨테이너에 대한 리소스를 서로 격리된 상태로 유지한다.
- cgroup: 서로 다른 컨테이너의 프로세스에서 사용하는 시스템 리소스를 제한하고, 프로세스의 일시 중단/재개를 제어한다.
2.1.2. 데몬
데몬은 백그라운드 프로세스로 계속 실행되고, 종종 원격 프로세스에서 오는 주기적인 서비스 요청을 처리하기 위해 깨어나는 프로그램이다. 데몬 프로세스는 컨테이너의 시작 및 중지, 이미지 관리 등과 같은 컨테이너 관리 프레임워크에서 실행된다.
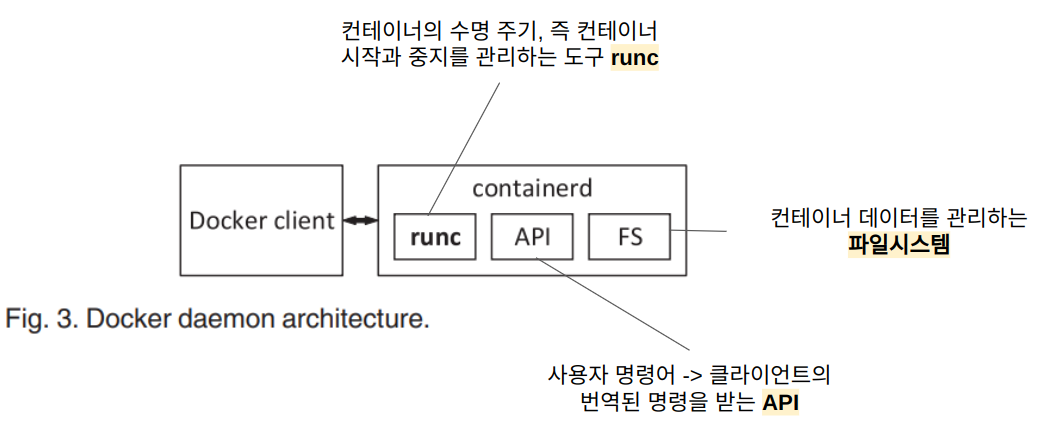
Containerd는 호스트에서 컨테이너의 수명 주기를 관리하는 컨테이너 런타임으로, 컨테이너를 생성, 시작, 중지 및 파괴한다. 또한 컨테이너 레지스트리에서 컨테이너 이미지를 가져오고, 스토리지를 마운트하고, 컨테이너에 대한 네트워킹을 활성화할 수 있다. Containerd 는 아래와 같이 구성되며, 각 구성 요소는 서로 협력하여 컨테이너 작업을 수행한다.
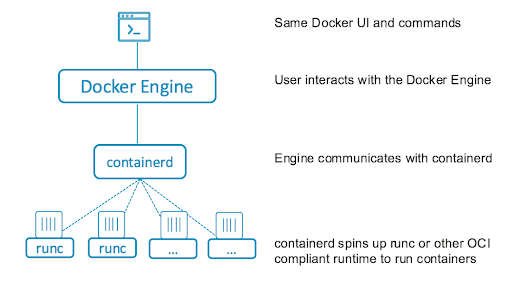
containerd는 대화식 사용자가 직접 제어하지 않고 백그라운드 프로세스로 실행되는 데몬으로, 위와 같은 작동 방식을 가진다.
2.1.3. 네트워크
서로 다른 컨테이너의 네임스페이스가 격리되어 있기 때문에, 공유 메모리를 통한 IPC는 서로 다른 컨테이너의 프로세스 간에 데이터를 전송하는 데 직접 사용할 수 없다. 따라서 Docker는 컨테이너 간 데이터 전송을 위해 서로 다른 네트워크 세그먼트를 연결하는 가상 스위치, 브리지를 사용한다.

데몬 프로세스가 초기화되면, 브리지 인스턴스가 시작되며, Veth(가상 이더넷)는 네임스페이스 사이의 터널 역할을 한다. Veth는 일반적으로 컨테이너에 하나, 브리지에 다른 하나 등 쌍으로 생성되는데, 그 결과 브리지와 연결된 Veth 디바이스가 있는 모든 컨테이너는 동일한 서브넷 내에 있게 되어 서로 데이터를 전송할 수 있게 된다. 이러한 브리지를 통한 데이터 전송은 데이터 패킹 및 언패킹 등의 절차가 필요하기 때문에 IPC에 비해 비효율적이라는 단점이 있다.
Preliminary Experiments
EXPERIMENTS ABOUT CONTAINER OPERATIONS
최신 컨테이너 관리 프레임워크 Docker와 일반적인 컴퓨팅 플랫폼인 X86 및 ARM 상에서 실험이 이루어졌다.
3.1. 컨테이너 간 통신

Netperf의 클라이언트와 서버를 두 개의 컨테이너(브리지를 통한 통신) 또는 동일한 컨테이너(IPC와 통신)에 배치하여 두 호스트간에 네트워크 대역폭을 측정한다. 클라이언트는 다양한 CPU 사용률(10~100%)을 가지며, 180초 동안 서버로 데이터 패킷을 계속 보낸다. 위 그래프에서 볼 수 있듯이, 브릿지 네트워크 또는 IPC의 전송 속도는 할당된 CPU 리소스에 따라 선형적으로 증가하며, 이는 전송 속도가 소모된 CPU 리소스의 양과 밀접하게 연관되어 있음을 나타낸다.

그리고 그림 5에 따르면, 네트워크 가상화 방식에 관계 없이, 데이터 전송 속도가 거의 동일한 것으로 나타났다.
3.2. 데몬 프로세스에 의한 컨테이너 관리
컨테이너 작업이 수행될 때 데몬 프로세스의 CPU 리소스 사용량을 기록하며 실험을 진행한다.

그림 6에서 볼 수 있듯이, 컨테이너 20개를 시작하기 위해 데몬 프로세스가 사용하는 CPU 리소스가 컨테이너 모니터링에 사용되는 리소스보다 훨씬 많다. 그 이유는 아래와 같다.
- 컨테이너 시작: 리소스 제한 설정, 네트워크 구성, 볼륨 마운트 등 많은 작업이 포함된다.
- 모니터링: 주기적으로 컨테이너의 상태만 확인하면 된다.
위 예비 실험을 통해 컨테이너 간 통신이 컨테이너 내 통신보다 효율성이 떨어진다는 것을 알 수 있었다. 하지만, 서로 다른 컨테이너에 할당된 태스크 간의 데이터 전송을 위해서는 컨테이너 간 통신이 불가피하기 때문에 이러한 작업을 실행하는 경우, 데이터 전송 속도가 느려서 컨테이너가 없는 경우보다 실행 시간이 더 길어진다. 따라서 컨테이너화 방식을 신중하게 결정하여 컨테이너 간 통신량과 그에 따른 애플리케이션 실행 시간에 미치는 영향을 줄일 수 있도록 해야 한다.
컨테이너를 시작할 때 데몬 프로세스는 작업 실행을 위한 리소스를 선점하는 데 상당한 CPU 리소스를 소비하며, 애플리케이션의 총 컨테이너 시작 시간은 총 컨테이너 수와 각 컨테이너 시작 횟수라는 두 가지 요소에 따라 달라진다. 컨테이너 수는 컨테이너화 체계에 따라 결정되며, 컨테이너를 시작하는 횟수는 컨테이너에 있는 작업의 일정에 따라 달라진다. 따라서 컨테이너 애플리케이션을 최적화하기 위해서는 작업 스케줄링과 컨테이너화를 함께 고려하는 것이 필수적임을 알 수 있었다.
Methods
실험에 사용된 애플리케이션은 너무 단순하여 실제 애플리케이션을 대표하기에는 부족하기 때문에, 본 논문에서는 실험 결과를 일반적인 애플리케이션으로 확장하기 위해 애플리케이션 모델과 실행 모델이라는 두 가지 시스템 모델을 구축한다.
- 애플리케이션 모델: 일반적인 엣지 컴퓨팅 애플리케이션의 구성을 설명한다.
- 일반적으로 애플리케이션은 표준 API로 연결된 여러 모듈로 구성되며, 이 모듈이 입력 데이터를 처리한 후 출력 데이터를 생성하는 과정을 태스크라고 한다. 태스크 간에는 종속성이 있으며, 고려해야 할 태스크 종속성에는 소프트웨어 종속성, 데이터 종속성, 커플링의 세 가지 유형이 있다.
- 소프트웨어 종속성: 소프트웨어 구성 요소에 의존
- 데이터 종속성: 한 작업이 다른 작업의 출력에 의존
- 커플링: 전역 변수와 같은 공유 처리 구성 요소 등에 두 태스크가 상호 의존
- 위 의존성에 기반하여, 결합 수준이 낮은 태스크는 태스크 오류의 영향 범위를 줄이기 위해 다른 컨테이너에 분산하는것이 좋으며, 의존성이 높은 태스크는 동일한 컨테이너에 실행하도록 한다.
- 일반적으로 애플리케이션은 표준 API로 연결된 여러 모듈로 구성되며, 이 모듈이 입력 데이터를 처리한 후 출력 데이터를 생성하는 과정을 태스크라고 한다. 태스크 간에는 종속성이 있으며, 고려해야 할 태스크 종속성에는 소프트웨어 종속성, 데이터 종속성, 커플링의 세 가지 유형이 있다.
- 실행 모델: 애플리케이션(태스크와 컨테이너 작업 모두 포함)의 CPU 리소스 사용률과 엣지 서버에서 태스크의 실행 시간을 나타낸다.
- 실행중인 태스크의 라이프사이클은 크게 세 단계로 나눌 수 있다. 태스크가 blocked되면, 입력 데이터를 메모리에 캐싱하고 CPU 리소스를 사용하지 않는다. 태스크가 모든 데이터를 입력받고 난 후에는, 태스크는 다음에 실행될 수 있도록 스케줄링된다. 태스크가 완료되면, 출력 데이터는 즉시 하위 태스크로 전송되며, 데이터 전송 기간동안 CPU 리소스를 사용하게 된다.
- blocked: 일부 입력 데이터를 사용할 수 없거나 예약되지 않은 경우
- running
- transmitting: 출력 데이터를 전송
- 실행중인 태스크의 라이프사이클은 크게 세 단계로 나눌 수 있다. 태스크가 blocked되면, 입력 데이터를 메모리에 캐싱하고 CPU 리소스를 사용하지 않는다. 태스크가 모든 데이터를 입력받고 난 후에는, 태스크는 다음에 실행될 수 있도록 스케줄링된다. 태스크가 완료되면, 출력 데이터는 즉시 하위 태스크로 전송되며, 데이터 전송 기간동안 CPU 리소스를 사용하게 된다.
즉, 비효율적인 작업의 양(상호 의존적인 작업)을 줄이고, 애플리케이션 실행 시간을 낮게 유지하기 위해 규칙을 설정한다.
- 컨테이너 간 통신은 비효율적이므로, 데이터 전송량이 많은 작업을 동일 컨테이너에 할당한다.
- 적절한 작업 스케줄링을 통해 컨테이너의 수를 줄임으로써, 컨테이너의 시작 횟수를 줄인다.
- 컨테이너 간 통신을 위해 두 태스크 사이에 CPU idle time을 활용한다.
- idle time: 병렬 컴퓨팅에서는 1) 모든 상위 작업과 2) 동일한 프로세서에서 예약된 이전 작업이 완료되기 전에는 작업을 시작할 수 없기 때문에, 이 원칙에 따라 프로세서의 idle time이 존재한다. 이 idle time 동안 컨테이너 간 통신이 제대로 수행될 수 있다면 동일한 프로세서에서 후속 작업이 지연되지 않을 수 있다.
- 실행 기간에 큰 영향을 미치는 작업 중에는 컨테이너 간 통신을 피한다.
그리고 위 규칙을 따르는 공동 스케줄링 및 컨테이너화 체계를 제안한다.
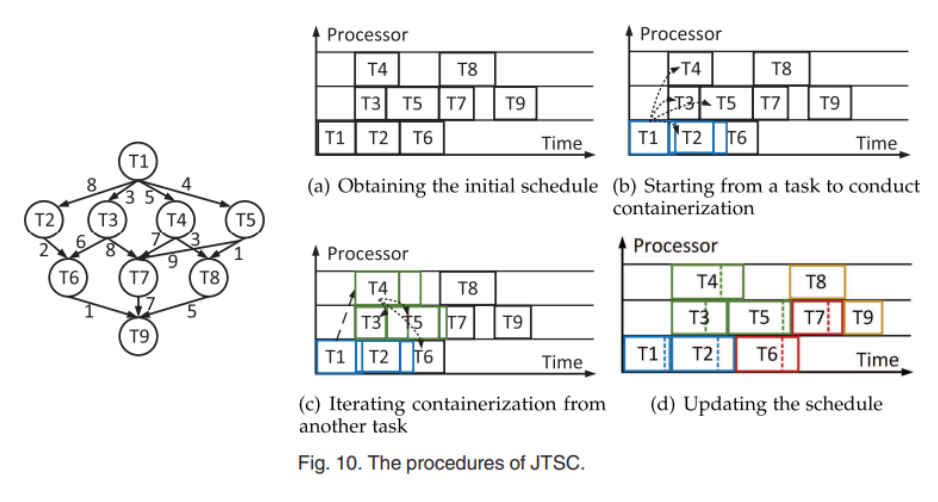
- 먼저 할당된 프로세서에서 작업을 스케줄링하여 '초기 스케줄'을 얻는다.
- 이 작업에서는 컨테이너 작업이 고려되지 않는다.
- 비효율적인 작업을 줄이기 위해, 초기 스케줄을 기반으로 태스크를 컨테이너에 매핑한다.
- 이 작업에서 컨테이너화 체계(태스크-컨테이너 간의 매핑)가 결정된다.
- 컨테이너 간 통신으로 인해 작업의 실행 시간이 변경될 수 있으므로 초기 스케줄을 적용할 수 없다. 따라서 컨테이너화 체계에서 얻은 새로운 작업 실행 기간을 기반으로 작업 스케줄이 업데이트 된다.
Evaluation
본 논문에서는 실제 워크플로우를 사용하여 작업과 작업 간의 종속성으로 구성된 JTSC를 평가했다. 각 태스크는 데이터 처리를 위한 일정량의 CPU 리소스 계산량 대 컨테이너 간 통신 비율(0.1, 0.5, 1, 5, 10)을 가진다. 작업 간의 종속성은 행렬로 표현되었으며, 일부 요소는 종속성 충돌을 나타내기 위해 무한대로 설정되었다.
JTSC의 성능은 컨테이너 간 전송량, 컨테이너 시작 횟수, 특정 애플리케이션의 실행 기간, JTSC의 실행 시간 등 특정 메트릭을 기반으로 평가된다.
- CPF: critical path first algorithm
- STO: start timestamp order
- ICRO: Idle-time-to-communication ratio order algorithm
- Rand: randomly search for a feasible containerization scheme
- SFD: smallest ICP
- SFC: smallest CST
- SFE: smallest NED
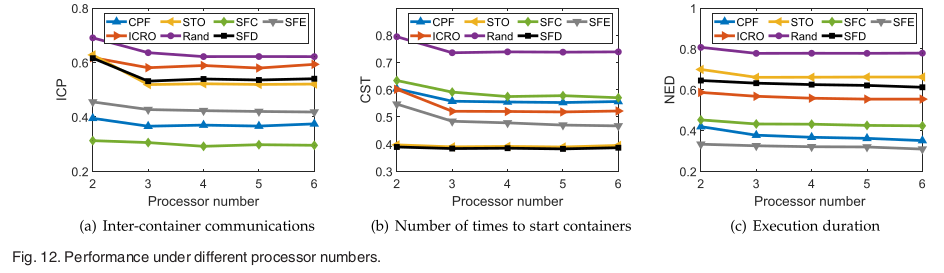
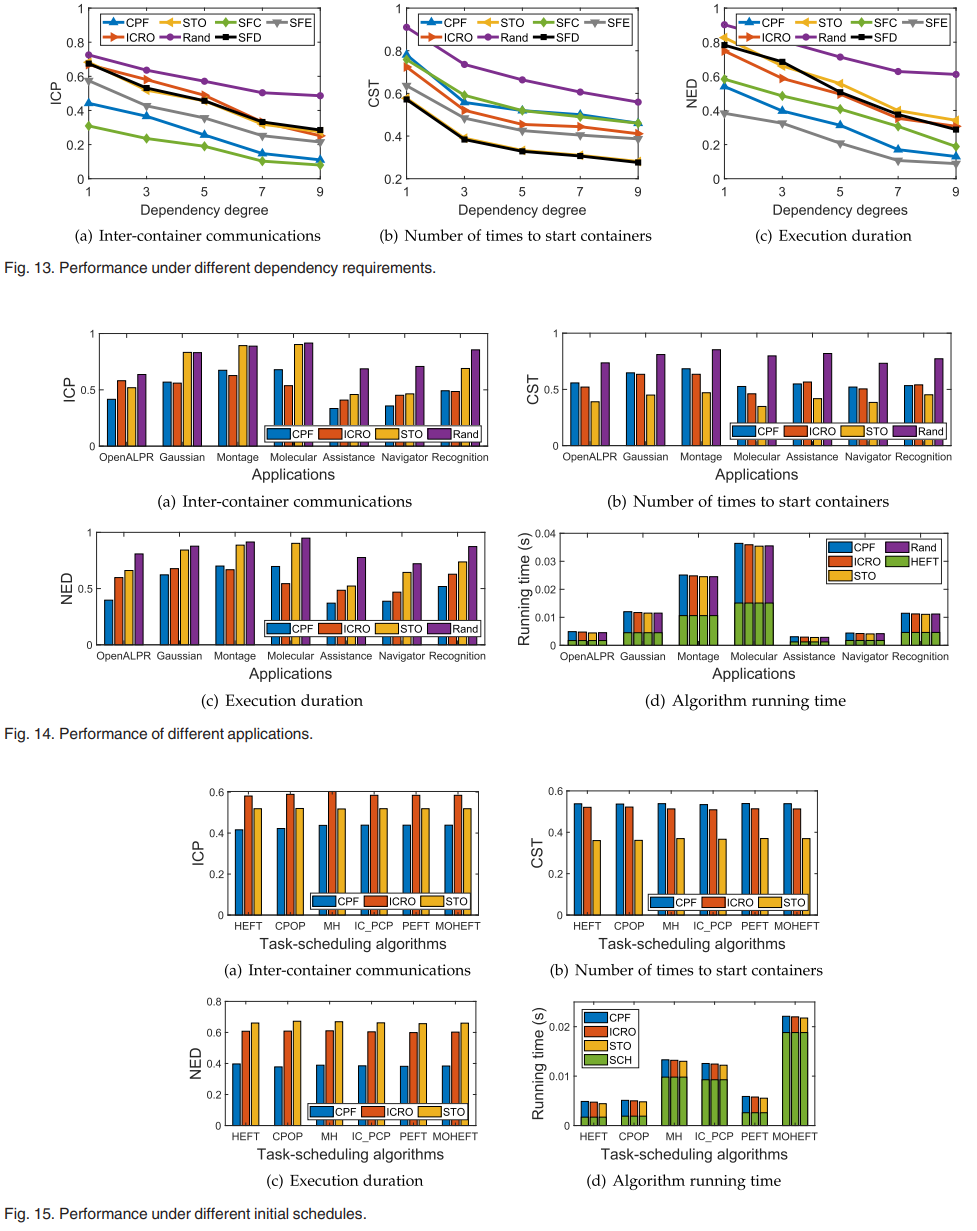
본 논문에 따르면 컨테이너화 알고리즘마다 컨테이너 간 통신과 컨테이너 시작 횟수를 줄이는 측면에서 장단점이 있는 것으로 나타났다.
- 통신 집약적인 작업에는 CPF와 ICRO가 더 나은 성능을 발휘한다.
- 컨테이너를 자주 시작하고 중지해야 하는 작업에는 STO가 더 나은 성능을 발휘한다.
서로 다른 성능을 강조하는 세 가지 컨테이너화 알고리즘이 포함된 JTSC 체계를 설계하여 애플리케이션의 작업 스케줄과 컨테이너화 체계를 결정했다. 그 결과 시뮬레이션을 통해 엣지 서버의 CPU 자원, 의존도 요구사항, 다양한 스케일의 애플리케이션, 다양한 초기 스케줄 등 다양한 조건에서 비효율적인 컨테이너 운영을 줄이고 애플리케이션의 실행 효율을 지속적으로 향상시킨다는 목표를 달성했다.
단, 본 논문에서 고려한 시나리오는 단일 엣지 서버에서 FaaS 애플리케이션만을 고려한 것이므로, 보다 복잡한 환경의 시나리오를 추가하는 것이 좋을 것으로 보인다. 예를 들어,
1) 이기종 연산 능력을 갖추고 무선 네트워크를 통해 연결된 여러 엣지 서버가 있는 엣지 컴퓨팅 시스템
2) 여러 애플리케이션을 동시에 고려
3) 작업의 워크플로우로 설명할 수 없는 애플리케이션 등
Discussion
애플리케이션의 워크플로우를 생성하는 것을 내가 직접 해서 연구에 적용해보기는 어려울 것 같다.
실험 방법 등이 좀 더 자세히 나왔으면 좋았을 것 같은데 조금 아쉽다.
'논문을 읽자' 카테고리의 다른 글
| An analysis of Facebook photo caching (0) | 2023.04.13 |
|---|---|
| AI4DL: Mining Behaviors of Deep Learning Workloads for Resource Management (0) | 2023.03.24 |
| Gpipe: Efficient training of giant neural networks using pipeline parallelism (0) | 2023.03.22 |
| An Empirical Study of Memory Sharing in Virtual Machines (0) | 2022.05.18 |
| 정보보호론 프로젝트: 커널 취약점과 보호기술에 관한 논문 survey (0) | 2021.06.18 |