Comparable 인터페이스에는 compareTo 메서드가 있는데, Object의 equals와 유사하기 때문에 어떤 점이 다른지를 중점으로 보면 되겠다.
compareTo는 단순 동치성 비교에 더해 순서까지 비교할 수 있으며, 제네릭하다.
=> Comparable을 구현했다는 것은 그 클래스의 인스턴스들에는 자연적인 순서 (natural order)가 있음을 뜻한다.
Comparable을 구현하게 되면 검색, 극단값 계산,자동 정렬되는 컬렉션 관리 등을 쉽게 할 수 있기 때문에, 자바 플랫픔 라이브러리의 모든 값 클래스와 열거 타입(아이템 34)이 Comparable을 구현하고 있다.
비교를 활용하는 클래스의 예로는 정렬된 컬렉션인 TreeSet과 TreeMap,
검색과 정렬 알고리즘을 활용하는 유틸리티 클래스인 Collections와 Arrays가 있다.
Comparable.compare
compareTo 메서드의 일반 규약은 equals의 규약과 비슷하다.
이 객체와 주어진 객체의 순서를 비교한다. 이 객체가 주어진 객체보다 작으면 음의 정수를, 같으면 0을, 크면 양의 정수를 반환한다. 이 객체와 비교할 수 없는 타입의 객체가 주어지면 ClassCastException을 던진다.
다음 설명에서 sgn(표현식) 표기는 수학에서 말하는 부호 함수(signum function)를 뜻하며, 표현식의 값이 음수, 0, 양수일 때 -1, 0, 1을 반환하도록 정의했다.
- Comparable을 구현한 클래스는 모든 x, y에 대해 sgn(x.compareTo(y)) =- -sgn(y. compareTo(x))여야 한다 (따라서 x.compareTo(y)는 y.compareTo(x)가 예외를 던질 때에 한해 예외를 던져야 한다).
- Comparable을 구현한 클래스는 추이성을 보장해야 한다. 즉, (x.compareTo(y) > 0 g y.compareTo(z) > 0)이면 x.compareTo(z) > 0이다.
- Comparable을 구현한 클래스는 모든 z에 대해 x.compareTo(y) == 0이면 sgn(x. compareTo(z)) == sgn(y.compareTo(z)) 다.
- (x.compareTo(y) == 0) == (x. equals(y))여야 한다. => 필수는 아니지만 꼭 지키는 게 좋다 Comparable을 구현하고 이 권고를 지키지 않는 모든 클래스는 그 사실을 명시해야 한다.
다음과 같이 명시하면 적당할 것이다. “주의: 이 클래스의 순서는 equals 메서드와 일관되지 않다.”
모든 객체에 대해 전역 동치관계를 부여하는 equals 메서드와 달리, compareTo 는 타입이 다른 객체를 신경 쓰지 않아도 된다.
(타입이 다른 객체가 주어지면 간단히 ClassCastException을 던져도 된다. 또는 다른 타입 사이의 비교할 때에는 공통 인터페이스 사용)
compareTo 규약을 좀 더 자세히 살펴보자.
1) Comparable을 구현한 클래스는 모든 x, y에 대해 sgn(x.compareTo(y)) =- -sgn(y. compareTo(x))여야 한다 - 반사성
두 객체 참조 의 순서를 바꿔 비교해도 예상한 결과가 나와야 한다는 의미이다.
2) Comparable을 구현한 클래스는 추이성을 보장해야 한다 - 추이성
추이성은 equals 에서도 살펴봤던 개념인데, 쉽게 말하면 첫 번째가 두 번째보다 크고 두 번째가 세 번째보다 크면, 첫 번째는 세 번째보다 커야 한다는 뜻이다.
3) Comparable을 구현한 클래스는 모든 z에 대해 x.compareTo(y) == 0이면 sgn(x. compareTo(z)) == sgn(y.compareTo(z)) - 반사성
크기가 같은 객체들끼리는 어떤 객체와 비교하더라도 항상 같아야 한다는 의미이다.
위 세 규약은 equals 규약에서 봤던 반사성, 대칭성, 추이성에 대한 내용이다. 그래서 주의사항도 똑같다.
기존 클래스를 확장한 구체 클래스에서 새로운 값 컴포넌트를 추가 했다면 compareTo 규약을 지킬 방법이 없다.
우회법도 같다. Comparable을 구현 한 클래스를 확장해 값 컴포넌트를 추가하고 싶다면, 컴포지션을 이용한다.
4) (x.compareTo(y) == 0) == (x. equals(y))여야 한다.
compareTo 메서드로 수행한 동치성 테스트의 결과가 equals와 같아야 한다는 의미이다.
compareTo의 순서와 equals의 결과가 일과되지 않은 클래스도 여전히 동작은 하기 때문에 꼭 지켜야 하는 것은 아니지만,
지키지 않을 경우 이 클래스의 객체를 정렬된 컬렉션에 넣으면 해당 컬렉션이 구현한 인터페이스(Collection, Set, 혹은 Map)에 정의된 동 작과 엇박자를 낼 것이다.
(이 인터페이스들은 equals 메서드의 규약을 따르지만, 정렬된 컬렉션들은 동치성을 비교할 때 equals 대신 compareTo를 사용)
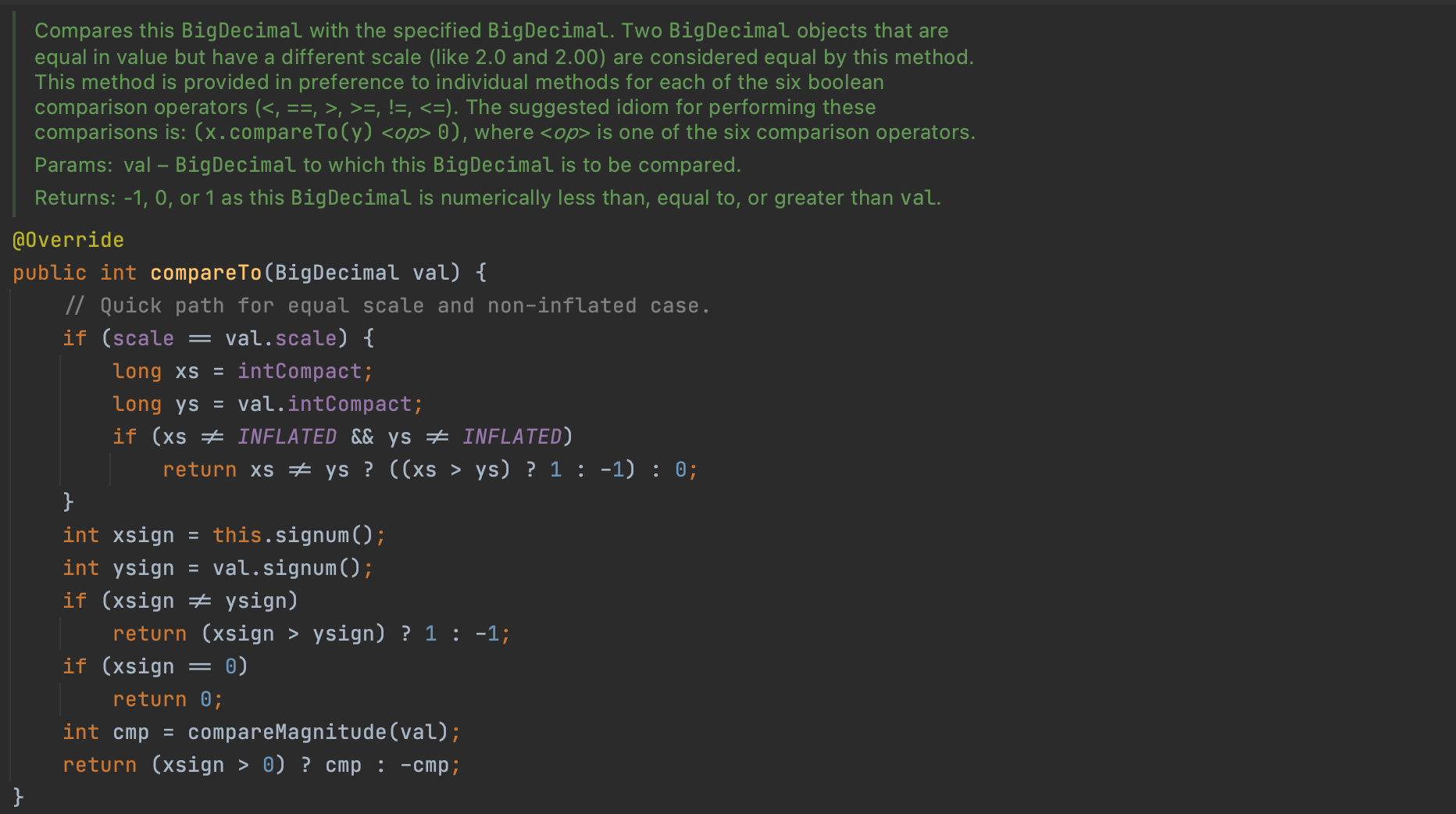
compareTo와 equals가 일관되지 않는 BigDecimal 클래스를 예로 생각해보자.
BigDecimal.equalsBigDecimal.compareTo
HashSet은 equals로 비교하고, TreeSet은 compareTo를 사용한다.
따라서 아래와 같이 동작하게 된다.
package com.example.sypark9646.item14;
import java.math.BigDecimal;
import java.util.HashSet;
import java.util.TreeSet;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.DisplayName;
import org.junit.jupiter.api.Test;
public class EqualsAndCompareToCollectionTest {
@Test
@DisplayName("HashSet와 TreeSet의 동작 방식을 비교한다")
void equalsAndCompareToCollectionTest(){
HashSet<BigDecimal> hashSet = new HashSet<>();
TreeSet<BigDecimal> treeSet = new TreeSet<>();
hashSet.add(new BigDecimal("1.0"));
hashSet.add(new BigDecimal("1.00"));
treeSet.add(new BigDecimal("1.0"));
treeSet.add(new BigDecimal("1.00"));
Assertions.assertEquals(2, hashSet.size()); // true
Assertions.assertEquals(1, treeSet.size()); // true
}
}
위 BigDecimal 1.0과 1.00은 equals 메서드로 비교 하면 서로 다르기 때문에 HashSet은 원소를 2개 갖게 된다.
하지만 compareTo 메서드로 비교하 면 두 BigDecimal 인스턴스가 똑같기 때문에 TreeSet의 원소는 1개이다.
Comparable은 타입을 인수로 받는 제네릭 인터페이스이므로 compareTo 메서드의 인수 타입은 컴파일타임에 정해진다.
입력 인수의 타입을 확인하거나 형변환 필요X
인수의 타입이 잘못됐다면 컴파일 자체가 X
null을 인수로 넣어 호출하면 NullPointerException을 던지도록 한다.
compareTo 메서드는 각 필드가 동치인지 비교하는 게 아니라 그 순서를 비교한다.
객체 참조 필드를 비교하려면 compareTo 메서드를 재귀적으로 호출한다. Comparable을 구현하지 않은 필드나 표준이 아닌 순서로 비교해 야 한다면 비교자(Comparator)를 대신 사용한다.
compareTo를 구현할 때에는 자바 7의 일반적으로 박싱된 기본 타입 클래스들에 새로 추가된 정적 메서드 compare를 이용하자.
(<와 > 를 사용하는 이전 방식은 헷갈리고 오류를 유발한다.)
자바 8부터는 Comparator 인터페이스가 일련의 비교자 생성 메서드(comparator construction method)의 팀을 꾸려 메서드 연쇄 방식으로 비교자를 생성할 수 있게 되었다. 그리고 이 비교자들을 compareTo 메서드를 구현하는 데 활용할 수 있다. (약간의 성능 저하는 있다)
class PhoneNumber {
private int areaCode, prefix, lineNum;
public int compareToWithCompare(PhoneNumber pn) {
int result = Integer.compare(areaCode, pn.areaCode); // 가장 중요한 필드
if (result == 0) {
result = Integer.compare(prefix, pn.prefix); // 두 번째로 중요한 필드
if (result == 0) {
result = Integer.compare(lineNum, pn.lineNum); // 세 번째로 중요한 필드
}
}
return result;
}
// comparinglnt는 람다 (lambda)를 인수로 받는다 - 입력 인수의 타입(PhoneNumber pn)을 명시함 주의
private static final Comparator<PhoneNumber> COMPARATOR = Comparator.comparingInt((PhoneNumber pn) -> pn.areaCode) // 가장 중요한 필드
.thenComparingInt(pn -> pn.prefix) // 두 번째로 중요한 필드
.thenComparingInt(pn -> pn.lineNum); // 세 번째로 중요한 필드
public int compareToWithComparator(PhoneNumber pn) {
return COMPARATOR.compare(this, pn);
}
}
이 때 주의할 점은, Comparator의 compare을 정의할 때 `값의 차`를 기준으로 사용하곤 하는데, 사용하지 않도록 하자.
왜냐하면 정수 오버플로우를 일으키거나 IEEE 754 부동소수점 계산 방식에 따른 오류를 낼 수 있다. 따라서 위에서 정의했듯이, Integer.compare 또는 Comparator.comparingInt 를 사용하도록 하자.
static Comparator<Object> hashCodeOrder = new Comparator() {
public int compare(Object o1, Object o2) {
return o1.hashCode() - o2.hashCode(); // 오버플로우 발생 가능
}
};
여기서 super.clone 호출을 try-catch 블록으로 감싼 이유는 Object의 clone 메서드가 검사 예외(checked exception)인 CloneNotSupportedException을 던지도록 선언되었기 때문이다. (CloneNotSupported Exception이 사실은 비 검사 예외 (unchecked exception) 였어야 했다. 아이템71)
만약 가변 객체에 대한 clone을 만들고 싶다면 어떻게 될까?
참조변수의 경우 동일한 값을 가지기 때문에 한 쪽이 바뀌면 다른쪽도 바뀌게 된다.
따라서 clone 메소드가 원본 객체에 영향을 끼치지 않기 위해서는 참조 변수 내부 정보를 재귀적으로 복사해야 한다.
아이템7에 나왔던 Stack 예제를 살펴보자.
elements를 복제할 때 elements.clone을 호출하게 되는데, 이때 elements 필드가 final이라면 복제할 수 없다. (final에는 새로운 값 할당 불가)
package com.example.sypark9646.item13;
import java.util.Arrays;
import java.util.EmptyStackException;
public class StackExample implements Cloneable {
private Object[] elements;
private int size = 0;
private static final int DEFAULT_INITIAL_CAPACITY = 16;
public StackExample() {
this.elements = new Object[DEFAULT_INITIAL_CAPACITY];
}
public void push(Object e) {
ensureCapacity();
elements[size++] = e;
}
public Object pop() {
if (size == 0) {
throw new EmptyStackException();
}
Object result = elements[--size];
elements[size] = null; // 다 쓴 참조 해제 return result;
return result;
}
// 원소를 위한 공간을 적어도 하나 이상 확보한다.
private void ensureCapacity() {
if (elements.length == size) {
elements = Arrays.copyOf(elements, 2 * size + 1);
}
}
@Override
public StackExample clone() {
try {
StackExample result = (StackExample) super.clone();
result.elements = elements.clone(); // elements 배열의 clone을 재귀적으로 호출
return result;
} catch (CloneNotSupportedException e) {
throw new AssertionError();
}
}
}
이 경우에는 element가 Object[]이기 때문에 제대로 복사가 됐다면, clone을 재귀적으로 호출하는 것만으로 충분하지 않은 경우도 있다.
package com.example.sypark9646.item13;
public class HashTableExample {
private Entry[] buckets = new Entry[100];
private static class Entry {
final Object key;
Object value;
Entry next;
Entry(Object key, Object value, Entry next) {
this.key = key;
this.value = value;
this.next = next;
}
// Entry deepCopy() { // 재귀 방식은 스택 오버플로를 일으킬 위험이 있다
// return new Entry(key, value, next == null ? null : next.deepCopy());
// }
Entry deepCopy() { // 반복자를 써서 순회하자
Entry result = new Entry(key, value, next);
for (Entry p = result; p.next != null; p = p.next) {
p.next = new Entry(p.next.key, p.next.value, p.next.next);
}
return result;
}
}
@Override
public HashTableExample clone() {
try {
HashTableExample result = (HashTableExample) super.clone();
result.buckets = new Entry[buckets.length];
for (int i = 0; i < buckets.length; i++) {
if (buckets[i] != null) {
result.buckets[i] = buckets[i].deepCopy();
}
}
return result;
} catch (CloneNotSupportedException e) {
throw new AssertionError();
}
}
}
이 때에는 Entry의 deepCopy를 만들어 연결 리스트를 복사하게 되는데,
주의 할 점은 재귀적으로 들어가게 되면 연결 리스트의 크기가 클 경우 재귀 스택이 너무 많아져서 스택 오버플로우를 일으킬 수 있기 때문에
반복자로 deepCopy를 만들도록 하자
Object의 clone 메서드는 CloneNotSupportedExceptioin을 던지지만 재정의한 메서드는 throws 절을 없애는 편이 좋다.
검사 예외를 던지지 않아야 그 메서드를 사용하기 편하기 때문이다(아이템 71).
Parent-Child 클래스들에서 본 것과 같이, 상속해서 쓰기 위한 클래스 설계 방식 두 가지(아이템 19) 중 어느 쪽에서든, 상속용 클래스는 Cloneable을 구현해서는 안 된다.
대신 Object의 방식을 모방하여 제대로 작동하는 clone 메서드를 구현해 protected로 두고 CloneNotSupportedException도 던질 수 있다. 이 방식은 Object를 바로 상속할 때처럼 Cloneable 구현 여부를 하위 클래스에서 선택하도록 해준다.
다른 방법으로는, clone을 동작하지 않게 구현해놓고 하위 클 래스에서 재정의하지 못하게 할 수도 있다.
아래와 같이 clone을 쓰지 못하도록 Exception을 걸어두면 된다.
@Override
protected final Object clone() throws CloneNotSupportedException {
throw new CloneNotSupportedException();
}
마지막으로 주의할 점은 Cloneable을 구현한 스레드 안전 클래스를 작성할 때는 clone 메서드 역시 적절히 동기화해줘야 한다.(아이템 78)
Object의 clone 메서드는 동기화를 신경 쓰지 않았다!!
따라서 호출외에 다른 할 일이 없더라도 clone을 재정의하고 동기화해줘야 한다.
이를 위해서는 Cloneable을 구현하는 모든 클래스는 clone을 재정의해야 하며, 접근 제한자는 public으로, 반환 타입은 클래스 자신으로 변경한다.
이 메소드는 가장 먼저 super.clone을 호출한 후 필요한 필드를 전부 적절히 수정하게 된다. (객체의 deepCopy 실행)
휴... 넘 복잡하다. 그러니까 Cloneable을 이미 구현한 클래스를 확장하는 경우 외에는 복사 생성자와 복사 팩터리라는 더 나은 객체 복사 방식을 제공하도록 하는 것이 좋겠다.
복사 생성자: 단순히 자신과 같은 클래스의 인스턴스를 인수로 받는 생성자
복사 팩터리: 복사 생성자를 모방한 정적 팩터리 메서드
public Parent(Parent parent) { // 복사 생성자
this.parentField = parent.getParentField();
}
public static Parent newInstance(Parent parent) { // 복사 팩터리
return new Parent(parent.getParentField());
}
위와 같은 방식이 Cloneable/clone 방식보다 나은 이유는,
생성자를 쓰지 않는 방식이 아니기 때문에 엉성한 clone 규약에 기대지 않고, 정상적인 final 필드 용법과도 충돌하지 않으며, 불필요한 검사 예외를 던지지 않고, 형변환도 필요치 않다.
또 다른 장점은 해당 클래스가 구현한 `인터페이스` 타입의 인스턴스를 인수로 받을 수 있다. 이를 변환 생성자 (conversion constructor)와 변환 팩터리 (conversion factory) 라고 한다. 이들을 이용 하게 되면 클라이언트는 원본의 구현 타입에 얽매이지 않고 복제본의 타입을 직접 선택할 수 있다.
ex. HashSet 객체를 TreeSet 타입으로 복제할 수 있다.
용어
공변 반환 타이핑 (covariant return typing): 자바 5에 추가된 개념으로, 메소드가 오버라이딩 될 때 더 좁은 타입으로 대체될 수 있다는 것이다.
Object의 기본 toString 메서드는 단순히 클래스이름@16진수해시코드를 반환한다.
Object.toString
toString의 일반 규약에 따르면 `간결하면서 사람이 읽기 쉬운 형태의 유익한 정보`를 반환해야 한다.
또한 toString의 규약에서는 `모든 하위 클래스에서 이 메서드를 재정의하라`고 한다.
toString을 잘 구현한 클래스는 디버깅하기 쉽다.
toString 메서드는 객체를 println, printf, 문자열 연결 연산자(+), assert 구문에 넘길 때, 혹은 디버거가 객체를 출력할 때 자동으로 불린다.
오류 메시지 등을 로깅할 때도 자동으로 호출될 수 있다.
따라서 실전에서 toString은 그 객체가 가진 주요 정보 모두를 반환하는 게 좋다.
하지만 객체가 거대하거나 객체의 상태가 문자열 로 표현하기에 적합하지 않다면 요약 정보를 담아야 한다. (사이즈나 id 등)
toString을 구현할 때면 반환값의 포맷을 문서화할지 정해야 한다. (값 클래스라면 문서화하는 것이 좋다)
포맷을 명시하기로 했다면, 명시한 포맷에 맞는 문자열과 객체를 상호 전환할 수 있는 정적 팩터리나 생성자를 함께 제공해주면 좋다.
자바 플랫폼의 많은 값 클래스가 따르는 방식이기도 하다. BigInteger, BigDecimal과 대부분의 기본 타입 클래스가 여기 해당한다.
BigInteger.toStringBigInteger String 생성자
toString을 제공할 때에는 포맷 명시를 해 두는 것이 좋고, toString이 반환한 값에 포함된 정보를 얻어올 수 있는 API를 제공하도록 하자.
그렇지 않으면 이 정보가 필요한 프로그래머는 toString의 반환값을 파싱할 수밖에 없다. 이 경우 성능이 나빠지고, 작업량이 늘어나며, 향후 포맷을 바꾸면 시스템이 망가질 수 있다.
정적 유틸리티 클래스(아이템 4)는 toString을 제공할 이유가 없다. 또한, 대 부분의 열거 타입(아이템 34)도 자바가 이미 완벽한 toString을 제공하니 따로 재정의하지 않아도 된다. 하지만 하위 클래스들이 공유해야 할 문자열 표현이 있는 추상 클래스라면 toString을 재정의해줘야 한다. (대다수의 컬렉션 구현체는 추상 컬렉션 클래스들의 toString 메서드를 상속)
위 글에서 볼 수 있듯이 HashMap은 해시코드가 다른 엔트리끼리는 동치성 비교를 시도조차 하지 않도록 최적화되어 있다.
그렇다면 올바른 해시코드를 리턴하기 위한 방법은 무엇일까?
만약 해시코드가 모두 동일한 값을 리턴한다면, HashMap에서는 모든 객체가 해시테이블의 버킷 하나에 담겨 마치 연결 리스트(linked list)처럼 동작한다. 그 결과 평균 수행 시간이 0(1)인 해시테이블이 O(n)으로 느려져서, 객체가 많아지면 도저히 쓸 수 없게 된다. 좋은 해시 함수라면 서로 다른 인스턴스에 다른 해시코드를 반환한다. 아까 보았던 hashCode 규약 3번이다. 이상적인 해시 함수는 주어진 (서로 다른) 인스턴스들을 32비트 정수 범위에 균일하게 분배해야 한다.
int 변수 result를 선언한 후 값 c로 초기화한다. (c는 해당 객체의 첫 번째 핵심 필드를 단계 2번 방식으로 계산한 해시코드)
핵심 필드: equals 비교에 사용되는 필드를 말한다. (아이템 10)
해당 객체의 나머지 핵심 필드 주 각각에 대해 다음 작업을 수행한다.
해당 필드의 해시코드 c를 계산한다.
기본 타입 필드라면, Type.hashCode(f)를 수행한다. 여기서 Type은 해당 기본 타입의 박싱 클래스다.
참조 타입 필드면서 이 클래스의 equals 메서드가 이 필드의 equals 를 재귀적으로 호출해 비교한다면, 이 필드의 hashCode를 재귀적으로 호출한다. 계산이 더 복잡해질 것 같으면, 이 필드의 표준형(canonical representation)을 만들어 그 표준형의 hashCode를 호출한다. 필드의 값이 null이면 0을 사용한다(다른 상수도 괜찮지만 전통적으로 0을 사용)
필드가 배열이라면, 핵심 원소 각각을 별도 필드처럼 다룬다. 규칙을 재귀적으로 적용해 각 핵심 원소의 해시코드를 계산한 다. 배열에 핵심 원소가 하나도 없다면 단순히 상수(일반적으로 0)를 사용한다. 모든 원소가 핵 심 원소라면 Arrays. hashCode 를 사용한다.
단계 2.a에서 계산한 해시코드 c로 result를 갱신한다. 코드로는 다음 과 같다.
result = 31 * result + c;
result를반환한다.
이때, equals 비교에 사용되지 않은 필드는 반드시 제외해야 한다. 그렇지 않으면 hashCode 규약 2번을 어기게 될 수 있다.
아래는 위 규칙에 따라 샘플로 만든 해시 코드이다.
@Override
public int hashCode() {
int result = Short.hashCode(areaCode);
result = 31 * result + Short.hashCode(prefix);
result = 31 * result + Short.hashCode(lineNum);
return result;
}
여기서 왜 31을 곱해야 하는지에 대한 생각은 스터디원이 잘 정리해 주어서 많은 도움이 됐다.
위 방식 외에도 Objects 클래스의 임의의 개수만큼 객체를 받아 해시코드를 계산해주는 정적 메서드인 hash를 사용할 수도 있다.
@Override
public int hashCode() { return Objects.hash(lineNum, prefix, areaCode); }
하지만 성능상 좋진 않다. 여러 입력 인수를 담기 위한 배열이 만들어지고, 입력 중 기본 타입이 있다면 박싱과 언박싱도 거쳐야 하기 때문이다.
클래스가 불변이고, 해시코드를 계산하는 비용이 크다면, 매번 새로 계산하기 보다는 캐싱하는 방식을 고려해야 한다.
이 타입의 객체가 주로 해시의 키로 사용될 것 같다면 인스턴스가 만들어질 때 해시코드를 계산해둬야 한다.
만약 해시의 키로 사용되지 않는 경우라면 hashCode가 처음 불릴 때 계산하는 지연 초기화(lazy initialization) 전략을 사용할 수도 있다. 이 경우에는 클래스를 스레드 안전하게 만들도록 신경 써야 한다(아이템 83).
예시는 아래와 같다. 주의할 점은 hashCode 필드의 초깃값은 흔히 생성되는 객체의 해시코드와는 달라야 한다는 점이다.
private int hashCode; // 자동으로 0으로 초기화된다.
@Override
public int hashCode() {
int result = hashCode;
if (result == 0) {
result = Short.hashCode(areaCode);
result = 31 * result + Short.hashCode(prefix);
result = 31 * result + Short.hashCode(lineNum); hashCode = result;
}
return result;
}
항진 명제: 논리식 혹은 합성명제에 있어 각 명제의 참·거짓의 모든 조합에 대하여 항상 참인 것
즉, 쉽게 말하면 인스턴스들 끼리 equals() 메서드를 사용해서, 논리적으로 같은지 검사할 필요가 없는 경우에는 Object의 기본 equals 로만으로도 해결한다.
상위 클래스에서 재 정의한 equals가 하위 클래스에도 적용되는 경우
HashSet, TreeSet, EnumSet 등 대부분의 Set 구현체 - AbstractSet 에서 정의된 equals 사용
ArrayList, Vector 등 대부분의 List 구현체 - AbstractList 에서 정의된 equals 사용
HashMap, TreeMap, EnumMap 등 대부분의 Map 구현체 - AbstractMap 에서 정의된 equals 사용
클래스가 private이거나 package-private이고, equals 메소드를 호출할 일이 없는 경우
equals 메서드를 오버라이딩해서 호출되지 않도록 막자
@Override
public boolean equals(Object o) {
throw new AssertionError(); // 메서드 호출 방지
}
equals를 재정의해야 하는 경우는 두 객체가 물리적으로 같은지 비교할 때가 아니라, 논리적 동치성을 확인해야 하며, 상위 클래스의 equals가 현재 클래스의 논리적 동치성을 비교하기에 적절하지 않을 경우이다.
주로 값 클래스들이 여기 해당하는데, 값 클래스란 Integer와 String처럼 값을 표현하는 클래스를 말한다.
값 객체의 equals를 재정의 하여 논리적 동치성을 확인하도록 하면, 인스턴스의 값을 비교할 수 있고, Map의 키와 Set의 원소로도 사용할 수 있게 된다.
만약 값 클래스라 하더라도 싱글톤이면 equals를 재정의하지 않아도 된다. Enum(아이템 34)도 여기에 해당한다.
이런 클래스에서는 어차피 논리적으로 같은 인스턴스가 2개 이상 만들어지지 않기 때문에 논리적 동치성과 객체 식별성이 사실상 똑같은 의미가 된다. 따라서 Object의 equals가 논리적 동치성까지 확인 해준다고 볼 수 있다.
equals 메소드를 재 정의할 때에는 동치관계(equivalence relation)를 만족해야한다.
1. 반사성(reflexivity): null이 아닌 모든 참조 값 x에 대해, x.equals(x) = true
객체는 자기 자신과 같아야 한다는 의미를 가진다.
2. 대칭성(symmetry): null이 아닌 모든 참조 값 x, y에 대해, x.equals(y) = true 이면 y.equals(x) = true
두 객체는 서로에 대한 동치 여부에 똑같이 답해야 한다는 의미이다. 이는 서로 다른 클래스의 객체를 비교할 때 위반될 수 있다.
예를 들어 아래와 같은 CaseInsensitiveString 을 정의 했을 때,
public final class CaseInsensitiveString {
private final String s;
public CaseInsensitiveString(String s) {
this.s = Objects.requireNonNull(s);
}
@Override
public boolean equals(Object o) {
if( o instanceof CaseInsensitiveString) {
return s.equalsIgnoreCase((CaseInsensitiveString) o).s);
}
if ( o instanceof String) {
return s.equalsIgnoreCase((String) o);
}
}
}
실행 결과는 아래와 같이 다른 값을 반환하게 된다. 그 이유는CaseinsensitiveString의 equals는 일반 String을 알고 있지만, String의 equals는 Case InsensitiveString의 존재를 모르기 때문이다.
CaseInsensitiveString cis = new CaseInsensitiveString("Media");
String s = "media";
cis.equals(s); // true
s.equals(cis); // false
3. 추이성(transitivity): null이 아닌 모든 참조 값 x, y, z에 대해, x.equal이(y)=true 이고 y.equals(z)=true 이면 x.equals(z) = true
추이성의 경우 상위 클래스에는 없는 새로운 필드를 하위 클래스에 추가하는 상황에서 위반될 수 있다.
예를 들어 아래와 같이 2차원의 점을 표현하는 Point 클래스와 이를 확장한 ColorPoint 클래스를 정의해 보자.
class Point {
private final int x;
private final int y;
public Point(int x, int y) {
this.x = x;
this.y = y;
}
@Override
public boolean equals(Object o) {
if (!(o instanceof Point)) {
return false;
}
Point p = (Point) o;
return p.x == x && p.y == y;
}
}
public class ColorPoint extends Point {
private final Color color;
public ColorPoint(int x, int y, Color color) {
super(x, y);
this.color = color;
}
@Override
public boolean equals(Object o) {
if (!(o instanceof Point)) {
return false;
}
// o가 일반 Point 이면 색상을 무시하고 비교한다.
if (!(o instanceof ColorPoint)) {
return o.equals(this);
}
// o가 ColorPoint 이면 색상까지 비교한다.
return super.equals(o) && ((ColorPoint) o).color == color;
}
}
이 경우 ColorPoint에서 equals를 재정의 하지 않으면 색상 정보는 무시한 채 비교를 수행하게 된다.
또한, 위와 같이 equals를 재정의 하게 되면 추이성을 위배하게 된다.
p1p2 와 p2p3 비교에서는 색상을 무시했지만, p1p3 비교에서는 색상까지 고려했기 때문이다.
ColorPoint p1 = new ColorPoint(1, 2, Color.RED);
Point p2 = new Point(1, 2);
ColorPoint p3 = new ColorPoint(1, 2, Color.BLUE);
pl.equals(p2); // true
p2.equals(p3); // true
pl.equals(p3); // false
사실객체 지향적 추상화의 이점을 포기하지 않는 한, 구체 클래스를 확장해 새로운 값을 추가하면서 equals 규약을 만족시킬 방법은 존재하지 않는다.
equals 안의 instanceof 검사를 getClass 검사로 바꾸면 가능하다고 생각할 수도 있다. 하지만, 이 경우는 같은 구현 클래스의 객체와 비교할 때만 true를 반환하게 된다.
=> Point의 하위 클래스는 정의상 여전히 Point이므로 어디서든 Point로써 활용될 수 있어야 한다. (리스코프 치환 원칙)
자바 라이브러리에도 구체 클래스를 확장해 값을 추가한 클래스가 종종 있다. java.util.Date와 java.util.Timestamp 관계가 이와 같다. 그래서 Timestamp의 equals는 대칭성을 위배하며 , Date 객체와 한 컬렉션에 넣거나 서로 섞어 사용하면 엉뚱하게 동작할 수 있다. 아래는 javadocs에 기술되어 있는 주의점이다.
The reason that I favor the instanceof approach is that when you use the getClass approach, you have the restriction that objects are only equal to other objects of the same class, the same run time type. If you extend a class and add a couple of innocuous methods to it, then check to see whether some object of the subclass is equal to an object of the super class, even if the objects are equal in all important aspects, you will get the surprising answer that they aren't equal. In fact, this violates a strict interpretation of the Liskov substitution principle, and can lead to very surprising behavior. In Java, it's particularly important because most of the collections (HashTable, etc.) are based on the equals method. If you put a member of the super class in a hash table as the key and then look it up using a subclass instance, you won't find it, because they are not equal. Because of these problems, I didn't even bother discussing the getClass approach. But it turns out that because it does let you add aspects while preserving the equals contract, some people favor it. So I just want to get the information out there that it has disadvantages too. The biggest disadvantage is the fact that you get two objects that appear equal (because they are equal on all the fields) but they are not equal because they are of different classes. This can cause surprising behavior. I'm going to write an essay discussing this in more detail. When it's done, I'll put it up on the book's web site. It will compare the two approaches and discuss the pros and cons.
Bill Venners: The reason I have used getClass in the past is because I don't know what is going to happen in subclasses. I can't predict that when I am writing my class. It seemed risky to me to use instanceof. If I used instanceof and someone passed a subclass instance to my superclass equals method, I would determine semantic equality by comparing only fields that exist in the superclass. I'd be ignoring any fields declared in subclasses, and it seems like they could be important to the notion of semantic equality for the subclass. The other way to look at it I guess is that using instanceof in a superclass equals method makes it harder to write subclasses, because equals is supposed to be symmetric. If you call the subclass's equals method implementation, passing in an instance of the superclass, it must return the same result as if you passed the subclass instance to the superclass's equals method.
Josh Bloch: Yes. You are correct in saying that using getClass in equals makes it much easier to preserve the equals contract, but at what cost? Basically, at the cost of violating the Liskov substitution principle and the principle of least astonishment. You write something that obeys the contract, but whose behavior can be very surprising.
정리하자면, instanceof 접근 방식을 선호하는 이유는 getClass 접근 방식을 사용할 때 객체가 동일한 런타임 유형인 동일한 클래스의 다른 객체와 만 동일하다는 제한이 있기 때문이다. 클래스를 확장하고 몇 가지 메서드를 추가하면 하위 클래스의 일부 객체가 수퍼 클래스의 객체와 동일한 지 확인하게 된다.
Java에서는 대부분의 컬렉션 (HashTable 등)이 equals 메소드를 기반으로하기 때문에 특히 중요한데, getClass 를 사용하게 되면 슈퍼 클래스의 멤버를 키로 해시 테이블에 넣은 다음 하위 클래스 인스턴스를 사용하여 조회하면 같지 않기 때문에 찾을 수 없게 될 수도 있다.
+) 추가적으로 추상클래스에서라면 equals 메소드 재정의로 해결 가능하다
4. 일관성(consistency): nuII이 아닌 모든 참조 값 x, y에 대해, x.equals(y)를 반복해서 호출하면 항상 같은 값을 반환
두 객체가 같다면 (어느 하나 혹은 두 객체 모두가 수정되지 않는 한) 앞으로도 영원히 같아야 한다는 의미이다.
또한, 클래스가 불변이든 가변이든 equals의 판단에 신뢰할 수 없는 자원이 끼어 들게 해서는 안 된다.
ex) java.net.URL의 equals는 URLStreamHandler를 이용하여 주어진 URL과 매핑된 호스트의 IP 주소 를 이용해 비교한다.
호스트 이름을 IP 주소로 바꾸려면 네트워크를 통해야 하 는데, 그 결과가 항상 같다고 보장할 수 없다.
URL.equalsURLStreamHandler.equals
=> 이런 문제를 피하려면 equals는 항시 메모리 에 존재하는 객체만을 사용한 결정적 (deterministic) 계산만 수행해야 한다.
5. null-아님: null이 아닌 모든 참조 값 x에 대해, x.equals(null)은 false다.
이름처럼 모든 객체가 null과 같지 않아야 한다는 의미이다.
특히 NullPointerException을 던지는 방식이 자주 발생할 수 있는데, equals에서는 이런 경우도 허용하지 않는다.
이 때, 명시적 null 검사를 하기 보다는 아래와 같이 건네받은 객체를 적절히 형변환한 후 필수 필드들의 값을 알아내도록 한다.
(이를 위해서는 형변환에 앞서 instanceof 연산자로 입력 매개변수가 올바른 타입 인지 검사해야 한다.)
+ equals가 타입을 확인하지 않으면 잘못된 타입이 인수로 주어졌을 때 Class CastException을 던져서 일반 규약을 위배하게 된다.
=> instanceof는 (두 번째 피 연산자와 무관하게) 첫 번째 피 연산자가 null이면 false를 반환한 다. 따라서 입력이 null이면 타입 확인 단계에서 false를 반환하 기 때문에 null 검사를 명시적으로 하지 않아도 된다.
Object 클래스의 equals를 살펴보면 재 정의 시 위의 동치관계들을 모두 만족해야 함을 알 수 있다.
만약 아래 equals 규약을 어기면 그 객체를 사용하는 다른 객체들이 어떻게 반응할지 알 수 없다.
Object.equals
위의 내용들을 정리하여 equals 메소드에 대한 재정의를 단계별로 알아보자
public final class phoneNumber {
private final short areaCode, prefix, lineNum;
@Override
public boolean equals(Object o) {
if( o == this) { // 1. == 연산자를 사용해 입력이 자기 자신의 참조인지 확인
return true;
}
if( o == null) { // 널 체크
return false;
}
if(!(o instanceof PhoneNumber)) { // 2. instanceof 연산자로 입력이 올바른 타입인지 확인
return false;
}
PhoneNumber pn = (PhoneNumber)o; // 3. 입력을 올바른 타입으로 형변환
return pn.lineNum == lineNum && pn.prefix == prefix
&& pn.areaCode == areaCode; // 4. 입력 객체와 자기 자신의 대응되는 핵심 필드들이 모두 일치하는지 하나씩 검사
}
}
1. == 연산자를 사용해 입력이 자기 자신의 참조인지 확인한다.
자기 자신이 면 true를 반환한다. 이는 단순한 성능 최적화용으로, 비교 작업이 복잡한 상황일 때 값어치를 할 것이다.
2. instanceof 연산자로 입력이 올바른 타입인지 확인한다. 그렇지 않다면 false를 반환한다.
이때의 올바른 타입은 equals가 정의된 클래스인 것이 보통이지만, 가끔은 그 클래스가 구현한 특정 인터페이스가 될 수도 있다. 어떤 인터페이스는 자신을 구현한 (서로 다른) 클래스끼리도 비교할 수 있 도록 equals 규약을 수정하기도 한다. 이런 인터페이스를 구현한 클래스라면 equals에서 (클래스가 아닌) 해당 인터페이스를 사용해야 한다.
ex) Set, List, Map, Map.Entry 등
3. 입력을 올바른 타입으로 형변환한다.
4. 입력 객체와 자기 자신의 대응되는 ‘핵심’ 필드들이 모두 일치하는지 하나씩 검사한다.
모든 필드가 일치하면 true를, 하나라도 다르면 false를 반환
=> 2단계에서 인터페이스를 사용했다면 입력의 필드 값을 가져올 때도 그 인터페이스의 메서드를 사용해야 한다.
타입이 클래스라면 (접근 권한 에 따라) 해당 필드에 직접 접근할 수도 있다.
주의할 점은 float와 double을 제외한 기본 타입 필드는 == 연산자로 비교하고, 참조 타입 필드는 각각의 equals 메서드로,
float와 double 필드는 각각 정적 메서드인 XXX.compare(x1, x2)로 비교한다. (Nan, -0.0f, 특수한 부동소수 값 등을 다뤄야 하기 때문)
=> XXX.equals를 대신 사용할 수 있으나, 이 경우에는 오토박싱을 사용하게 되어서 성능 상 좋지 않다.
+) null도 정상 값으로 취급하는 참조 타입 필드의 경우는 Object.equals를 사용하도록 한다. (NullPointerException 발 생을 예방)
만약 CaselnsensitiveString 처럼 복잡한 필드를 가진 클래스를 비교할 때에는 필드의 표준형(canonical form)을 저장해둔 후, 표준형끼리 비교하면 훨씬 경제적이다. 이 기법은 특히 불변 클래스(아이템 17)에 좋다.
어떤 필드를 먼저 비교하느냐가 equals의 성능을 좌우하므로 다를 가능성이 더 크거나 비교하는 비용이 싼 필드를 먼저 비교하자.
동기화용 락(lock) 필드 같이 객체의 논리적 상태와 관련 없는 필드는 비교하면 안 된다. 핵심 필드로부터 계산해낼 수 있는 파생 필드 역시 굳이 비교할 필요는 없지만, 파생 필드를 비교하는 쪽이 더 빠 를 때도 있다. 파생 필드가 객체 전체의 상태를 대표하는 상황이 그렇다.
ex) 자신의 영역을 캐시해두는 Polygon 클래스의 경우
=> 모든 변과 정점을 일일이 비교할 필요 없이, 캐시해둔 영역만 비교하면 결과를 바로 알 수 있다.
추가적으로 알아둘 점은,
equals를 재정의할 땐 hashCode도 반드시 재정의하자(아이템 11)
너무 복잡하게 해결하려 하지 말자. 필드들의 동치성만 검사해도 된다. alias 등은 무시하자.
Object 외의 타입을 매개변수로 받는 equals 메서드는 선언하지 말자. (입력 타입이 Object가 아니므로 재정의가 아니라 다중정의임)
class MyClass {
public boolean equals(MyClass o) { // 재정의가 아니라 다중정의이다
// -> 따라서 여기에 @Override 애노테이션을 붙이면 컴파일 에러 발생함
}
}
용어
리스코프 치환 원칙 (Liskov substitution principle): 어떤 타입에 있어 중요한 속성이라면 그 하위 타입에서도 마찬가지로 중요하다. 따라서 그 타 입의 모든 메서드가 하위 타입에서도 똑같이 잘 작동해야 한다. => 서브타입은 언제나 자신이 기반타입 (base type)으로 교체할 수 있어야 한다.
자바 라이브러리에는 close 메서드를 호출해 직접 닫아줘야 하는 자원이 많다. ex) InputStream, OutputStream, DB Connection ...
item8에서 알 수 있듯이 안전망으로 finalizer를 활용할 수 있으나, finalizer는 확실하게 믿을 순 없다
이를 보완하기 위해 try-with-resources를 사용하도록 하자
// 둘 이상의 자원에서 try-finally: 중첩 되어 지저분해 보이고, exception이 일어난 경우 디버깅이 어렵다
static void copy(String src, String dst) throws IOException {
InputStream in = new FileInputStream(src);
try{
OutputStream out = new FileOutputStream(dst);
try{
byte[] buf = new byte[BUFFER_SIZE];
int n;
while((n=in.read(buf))>=0){
out.write(buf, 0, n);
}
} finally {
out.close();
}
} finally {
in.close();
}
}
위 예시에서 예외는 try 블록과 finally 블록 모두에서 발생할 수 있다.
예를 들어 FileOutputStream 메서드가 예외를 던지고, 같은 이유로 close 메서드도 실패할 때,
두 번째 예외가 첫 번째 예외를 완전히 집어삼켜 버린다. => 스택 추적 내역에 첫 번째 예외에 관한 정보X
// try-with-resources: 자원을 회수하는 올바른 선택, 코드는 더 짧고 분명해지며, 예외 케이스도 유용하게 볼 수 있다.
static void copy(String src, String dst) throws IOException {
try(
InputStream in = new FileInputStream(src);
OutputStream out = new FileOutputStream(dst);
){
byte[] buf = new byte[BUFFER_SIZE];
int n;
while((n=in.read(buf))>=0){
out.write(buf, 0, n);
}
}
}
Java7부터Closeable리소스와 관련하여 아래와 같이 키워드뒤의 괄호 안에 리소스를 만들 수 있다.
try (initialize resources here) {
...
}
그리고코드 블록이 완료되면자동으로닫히기 때문에finally가필요 없다.
이 구조를 사용하려면 해당 자원이 AutoCloseable 인터페이스를 구현해야 한다.
AutoCloseable은 단순히 void를 반환하는 close 메서드 하나만 덩그러니 정의한 인터페이스다.
이 경우는 try-finally와는 다르게 양쪽에서 예외가 발생하면, close에서 발생한 예외는 숨겨지고 맨 처음에 발생한 예외가 기록된다.
단, 이렇게 숨겨진 예외들도 그냥 버려지지는 않고, 스택 추적 내역에 ‘숨겨졌다 (suppressed)’는 꼬리표를 달고 출력된다.
또한, 자바 7에서 Throwable에 추가 된 getSuppressed 메서드를 이용하면 프로그램 코드에서 가져올 수도 있다.
catch (Throwable e) {
Throwable[] suppExe = e.getSuppressed();
for (int i = 0; i < suppExe.length; i++) {
System.out.println("Suppressed Exceptions:");
System.out.println(suppExe[i]);
}
}
보통의 try-finally에서처 럼 try-with-resources에서도 catch 절을 쓸 수 있다. catch 절 덕분에 try 문을 더 중첩하지 않고도 다수의 예외를 처리할 수 있다.
참고로, 스트림을 닫을 때에는 IOUtils를 쓰는 방법도 있다. (대신 이 방법을 사용할 경우 Exception이 제대로 나오지 않음)
2) finalizer 동작 중 발생한 예외는 무시되고, 처리할 작업이 남았더라도 그 순간 종료된다
=> 만약 다른 스레드가 이처럼 훼손된 객체를 사용하려 한다면 어떻게 동작할지 예측할 수 없다.
일반적으로는 잡지 못한 예외가 스레드를 중단시키고 스택 추적 내역을 출력하겠지만, finalizer에서는 경고조차 출력하지 않는다.
c.f.) cleaner는 자신의 스레드를 통제하기 때문에 이 문제에 대해서는 괜찮다.
3) finalizer와 cleaner는 심각한 성능 문제도 동반한다
=> finalizer가 가비지 컬렉터의 효율을 떨어뜨리기 때문이다
4) finalizer를 사용한 클래스는 finalizer 공격에 노출되어 심각한 보안 문제를 일으킬 수도 있다.
finalizer 공격 원리는 생성자나 직렬화 과정 (readObject와 readResolve 메서드)에서 예외가 발생하면,
이 생성이 되다 만 객체에서 악의적인 하위 클래스의 finalizer가 수행될 수 있게 된다.
=> 이 경우 finalizer는 정적 필드에 자신의 참조를 할당하여 가비 지 컬렉터가 수집하지 못하게 막을 수 있다.
해결 방법1 : 클래스를 final로 만들자(final 클래스들은 그 누구도 하위 클래스를 만들 수 없기 때문) 해결 방법2: final이 아닌 클래스를 finalizer 공격으로부터 방어하려면 아무 일도 하지 않는 finalize 메서드를 만들고 final로 선언
finalizer나 cleaner를 대신 할 수 있는 방법은 무엇이 있을까?
AutoCloseable 을 구현해주고, 클라이언트에서 인스턴스를 다 쓰고 나면 close 메서드를 호출하면 된다
(일반적으로 예외가 발생해도 제대로 종료되도록 try-withresources를 사용해야 한다. 아이템 9 참조).
추가적으로 각 인스턴스는 자신이 닫혔는지 추적하는 것이 좋다. 즉, close 메서드에서 이 객체는 더 이상 유효하지 않음을 필드에 기록하고, 다른 메서드는 이 필드를 검사해서 객체가 닫힌 후에 불렸다면 IllegalStateException을 던지록 하자.
그렇다면 finalizer이나 cleaner를 써야하는 경우는 언제일까?
1) 자원의 소유자가 close 메서드를 호출하지 않는 것에 대비한 안전망 역할로서 사용할 때
cleaner나 finalizer가 즉시 (혹은 끝까지) 호출되리라는 보장은 없지만, 클라이언트가 하지 않은 자원 회수를 늦게라도 해주는 것이 아예 안 하는 것보다는 낫기 때문이다. 그래도 이런 안전망 역할 의 finalizer를 작성할 때는 그럴만한 값어치가 있는지 생각해 보아야 한다.
c.f. finalizer 와 달리 cleaner는 클래스의 public API에 나타나지 않는다
// 코드 8-1 cleaner를 안전망으로 활용하는 AutoCloseable 클래스
public class Room implements AutoCloseable {
private static final Cleaner cleaner = Cleaner.create();
/* static으로 선언된 중첩 클래스인 State는 cleaner가 방을 청소할 때 수거할 자 원들을 담고 있다. */
// 청소가 필요한 자원.절대 Room을 참조해서는 안 된다! 만약 참조한다면 순환참조가 생김
private static class State implements Runnable {
int numJunkPiles; // 방(Room) 안의 쓰레기 수 => 수거할 자원
State(int numJunkPiles) {
this.numJunkPiles = numJunkPiles;
}
// close 메서드나 cleaner가 호출한다. => cleanable에 의해 딱 한 번만 호출된다
@Override
public void run() {
System.out.println("방 청소");
numJunkPiles = 0;
}
}
// 방의 상태. cleanable과 공유한다.
private final State state;
// cleanable 객체. 수거 대상이 되면 방을 청소한다. => Room 생성자에서 cleaner에 Room과 State를 등록할 때
private final Cleaner.Cleanable cleanable;
public Room(int numJunkPiles) {
state = new State(numJunkPiles);
cleanable = cleaner.register(this, state);
}
@Override
public void close() {
cleanable.clean();
}
}
run 메서드가 호출되는 상황은 둘 중 하나다.
1 - 보통은 Room의 close 메서드를 호출할 때이다. close 메서드에서 Cleanable의 clean을 호출하면 이 메서드 안에서 run을 호출
2 - 가비지 컬렉터가 Room을 회수할 때 까지 클라이언트가 close를 호출하지 않는다면, cleaner가 State.run 메서드를 호출
이 때, State가 정적 중첩 클래스인 이유는, 정적이 아닌 중첩 클래스는 자동으로 바깥 객체의 참조를 갖게 되기 때문에 GC가 회수할 수 없다.
이와 유사하게 람다 역시 바깥 객체의 참조를 갖기 쉬우니 사용하지 않는 것이 좋다.
/* 올바른 예제 */
class Adult {
public static void main(String[] args) {
try (Room myRoom = new Room(7)) { // "안녕" "방청소" 순서대로 출력
System.out.println("안녕〜");
}
}
}
/* 틀린 예제 - System.exit을 호출할 때의 cleaner 동작은 구현하기 나름이다. 청소가 이뤄질지는 보장 하지 않는다 */
public class Teenager {
public static void main(String[] args) {
new Room(99);
System.out.println("아무렴"); // "아무렴" 출력 이후 아무 일도 일어나지 않는다 => 예측할 수 없는 상황
}
}
2) 네이티브 피어와 연결된 객체에서 사용할 때(단, 성능 저하를 감당할 수 있고 네이티브 피어가 심각한 자원을 가지고 있지 않은 경우)
네이티브 피어(native peer)
일반 자바 객체가 네이티브 메서드를 통해 기능을 위임한 네이티브 객체
네이티브 피어는 자바 객체 가 아니니 가비지 컬렉터슨 그 존재를 알지 못한다. 그 결과 자바 피어를 회수 할 때 네이티브 객체까지 회수하지 못한다.
=> 성능 저하를 감당할 수 없거나 네이티브 피어가 사용하는 자원을 즉시 회수해야 한다면 `close` 메서드를 사용해야 한다.
메모리 누수를 주의 깊게 보아야 하는 경우 아래 3가지 정도가 있다. = 객체들이 다 쓴 참조(obsolete reference)를 여전히 가지고 있는 경우
1) 아래 코드는 스택을 구현한 코드인데, pop()을 보면 스택에서 꺼내진 객체를 더 이상 사용하지 않는데도 회수하지 않고 있다.
public class Stack {
private Object[] elements;
private int size = 0;
private static final int DEFAULT_INITIAL_CAPACITY = 16;
...
public Object pop() {
if(size == 0){
throw new EmpthStackException();
}
return elements[--size]; // 메모리 누수: elements[size] = null을 해 주어야
}
}
가비지 컬렉터는 객체 참조 하나 뿐만 아니라, 이 객체가 참조하는/참조되는 모든 객체들을 회수하지 못하게 된다.
그래서 elements[size] = null 을 해 주는 부분이 필요하다. (이 부분을 추가할 경우 외부 영역 접근 시 NullPointerException을 던지게 됨으로써 오류를 조기에 발견할 수 있게 된다)
하지만, 모든 곳에 이 것을 해 줄 필요는 없다.
객체 참조를 꼭 null 처리 해 주어야 하는 경우는 위 스택 예제와 같이 자기 메모리를 직접 관리하는 클래스를 구현할 때이다.
위 스택 예제에서는 객체 자체가 아닌 객체 참조를 담는 elements 배열로 저장소 pool을 만들어 원소들을 관리한다.
2) 객체 참조를 캐시에 두고 계속 캐시에 두는 것 또한 메모리 누수를 일으키는 주범이다. 해결 방법은 아래와 같다.
- WeakHashMap을 사용하여 캐시를 만들면 다 쓴 엔트리는 그 즉시 자동으로 제거될 것이다.
package com.example.sypark9646.item07;
import java.util.Map;
import java.util.WeakHashMap;
public class WeakHashMapTest {
public static void main(String[] args) {
MyKey k1 = new MyKey("Hello");
MyKey k2 = new MyKey("World");
MyKey k3 = new MyKey("Java");
MyKey k4 = new MyKey("Programming");
Map<MyKey, String> wm = new WeakHashMap<>();
wm.put(k1, "Hello");
wm.put(k2, "World");
wm.put(k3, "Java");
wm.put(k4, "Programming");
k1 = null;
k2 = null;
k3 = null;
k4 = null;
System.gc(); // 강제로 GC 발생
System.out.println("Weak Hash Map :" + wm.toString()); //Weak Hash Map :{}
}
}
- 캐시를 만들 때 ScheduledThreadPoolExecuter 등을 이용하여 시간이 지날수록 엔트리의 가치를 떨어뜨리는 방식을 사용한다.
- LinkedHashMap을 사용할 경우에는 removeEldestEntry 메소드를 사용해서 시간이 지날수록 엔트리의 가치를 떨어뜨리는 방식을 사용한다.
- java.lang.ref 패키지를 활용하여 만드는 방법
java.lang.ref 패키지는 전형적인 객체 참조인 strong reference 외에도 soft, weak, phantom 3가지의 새로운 참조 방식을 각각의 Reference 클래스로 제공합니다. 이 3가지 Reference 클래스를 애플리케이션에 사용하면 앞서 설명하였듯이 GC에 일정 부분 관여할 수 있고, LRU(Least Recently Used) 캐시 같이 특별한 작업을 하는 애플리케이션을 더 쉽게 작성할 수 있습니다. 이를 위해서는 GC에 대해서도 잘 이해해야 할 뿐 아니라, 이들 참조 방식의 동작도 잘 이해할 필요가 있습니다.
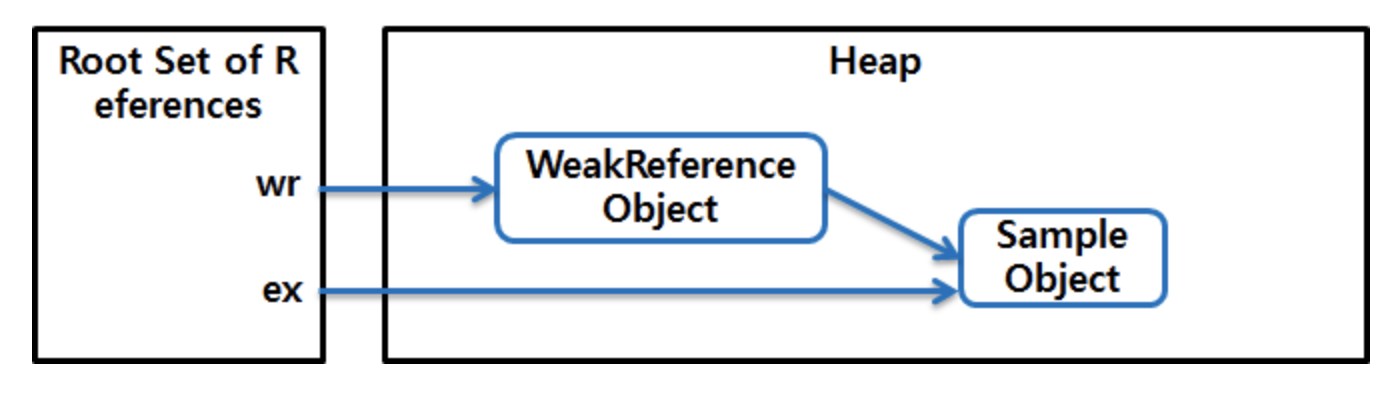
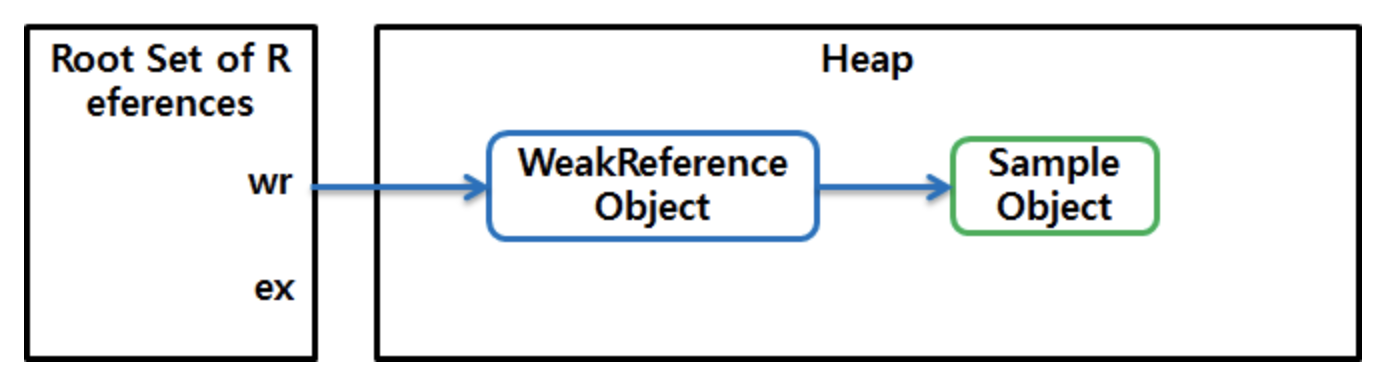
WeakReference<Sample> wr = new WeakReference<Sample>(new Sample());
Sample ex = wr.get(); // 그림 1
// ...
ex = null; // 그림 2
https://d2.naver.com/helloworld/329631 그림 1https://d2.naver.com/helloworld/329631 그림 2
Strong 레퍼런스를 Weak 레퍼런스로 감싸면 Weak 레퍼런스가 된다.
Garbage Collection 대상이 되려면 해당 객체를 가리키는 레퍼런스가 전부 없어져야 한다.
Weak 레퍼런스는 Strong한 레퍼런스가 없어지면 Weak 레퍼런스도 GC의 대상이 될 수가 있다.
즉, 정리하자면, 원래 GC 대상 여부는 reachable/unreachable인가로만 구분하였고 이를 사용자 코드에서는 관여할 수 없었다.
그러나 java.lang.ref 패키지를 이용하여 reachable 객체들을 strongly reachable, softly reachable, weakly reachable, phantomly reachable로 더 자세히 구별하여 GC 때의 동작을 다르게 지정할 수 있게 되었다. = GC 대상 여부를 판별하는 부분에 사용자 코드가 개입할 수 있다
녹색으로 표시한 중간의 두 객체는 WeakReference로만 참조된 weakly reachable 객체이고, 파란색 객체는 strongly reachable 객체이다. GC가 동작할 때, unreachable 객체뿐만 아니라 weakly reachable 객체도 가비지 객체로 간주되어 메모리에서 회수된다.
root set으로부터 시작된 참조 사슬에 포함되어 있음에도 불구하고 GC가 동작할 때 회수되므로, 참조는 가능하지만 반드시 항상 유효할 필요는 없는 LRU 캐시와 같은 임시 객체들을 저장하는 구조를 쉽게 만들 수 있다.
위 그림에서 WeakReference 객체 자체는 weakly reachable 객체가 아니라 strongly reachable 객체이다. 또한, 그림에서 A로 표시한 객체와 같이 WeakReference에 의해 참조되고 있으면서 동시에 root set에서 시작한 참조 사슬에 포함되어 있는 경우에는 weakly reachable 객체가 아니라 strongly reachable 객체이다.
GC가 동작하여 어떤 객체를 weakly reachable 객체로 판명하면, GC는 WeakReference 객체에 있는 weakly reachable 객체에 대한 참조를 null로 설정한다. 이에 따라 weakly reachable 객체는 unreachable 객체와 마찬가지 상태가 되고, 가비지로 판명된 다른 객체들과 함께 메모리 회수 대상이 된다.
참고) Strengths of Reachability
strongly reachable: root set으로부터 시작해서 어떤 reference object도 중간에 끼지 않은 상태로 참조 가능한 객체, 다시 말해, 객체까지 도달하는 여러 참조 사슬 중 reference object가 없는 사슬이 하나라도 있는 객체
softly reachable: strongly reachable 객체가 아닌 객체 중에서 weak reference, phantom reference 없이 soft reference만 통과하는 참조 사슬이 하나라도 있는 객체
weakly reachable: strongly reachable 객체도 softly reachable 객체도 아닌 객체 중에서, phantom reference 없이 weak reference만 통과하는 참조 사슬이 하나라도 있는 객체
phantomly reachable: strongly reachable 객체, softly reachable 객체, weakly reachable 객체 모두 해당되지 않는 객체. 이 객체는 파이널라이즈(finalize)되었지만 아직 메모리가 회수되지 않은 상태이다.
unreachable: root set으로부터 시작되는 참조 사슬로 참조되지 않는 객체
3) Listener와 Callback 등록 후 해지 하지 않는 것도 메모리 누수의 주범이 될 수 있다.
이 경우 마찬가지로 콜백을 약한 참조로(WeakHashMap에) 저장하면 가비지 컬렉터가 즉시 수거해 갈 수 있다.