이 문제에서 주의할 점은 입출력이 많기 때문에 내가 평소에 애용하는 Scanner/System.out.println을 써 버리면 시간초과가 난다는 점이다.
BufferedReader/BufferedWriter를 써버릇 해야 하는데.. 길고 귀찮아서 굳이 틀려야 바꿔보게 된다... 담엔 입출력 갯수부터 파악하자...ㅠ
import java.util.*;
import java.io.*;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
int n = Integer.parseInt(st.nextToken());
int m = Integer.parseInt(st.nextToken());
String name[] = new String[n];
int power[] = new int[n];
for (int i = 0; i < n; i++) {
st = new StringTokenizer(br.readLine());
name[i] = st.nextToken();
power[i] = Integer.parseInt(st.nextToken());
}
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
for (int i = 0; i < m; i++) {
int characterPower = Integer.parseInt(br.readLine());
bw.write(getName(characterPower, n, power, name) + "\n");
}
bw.flush();
br.close();
}
private static String getName(int characterPower, int length, int[] power, String[] name) {
int start = 0;
int end = length - 1;
int answer = end;
while (start <= end) {
int mid = (start + end) / 2;
if (characterPower <= power[mid]) {
answer = Math.min(mid, answer);
end = mid - 1;
} else {
start = mid + 1;
}
}
return name[answer];
}
}
이때, 적어도 M미터의 나무를 집에 가져가기 위해서 절단기에 설정할 수 있는 높이의 최댓값을 구하는 프로그램을 작성하시오.
=> 최소의 최대를 구하는 문제는 뭐다?? = 이분탐색이다~~
import java.util.*;
public class Main {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
int n = in.nextInt();
long length = in.nextLong();
long tree[] = new long[n];
long start = 0;
long end = 0;
for (int i = 0; i < n; i++) {
tree[i] = in.nextLong();
end = Math.max(end, tree[i]);
}
long answer = 0;
while (start <= end) {
long mid = (start + end) / 2;
// System.out.println(start + " " + answer + ", " + mid + " " + end);
if (sumTree(mid, tree) >= length) {
answer = Math.max(mid, answer);
start = mid + 1;
} else {
end = mid - 1;
}
}
System.out.println(answer);
}
private static long sumTree(long cut, long[] trees) {
long sum = 0;
for (long tree : trees) {
sum += tree >= cut ? tree - cut : 0;
}
return sum;
}
}
첨에 아무 생각 없이 mid*mid를 롱 타입으로 계산했는데 오버 플로우가 발생해서 BigInteger로 계산하도록 했다.
import java.math.BigInteger;
import java.util.*;
public class Main {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
long n = in.nextLong();
long end = n;
long start = 0;
long answer = n;
while (start <= end) {
long mid = (start + end) / 2;
BigInteger bigMid = BigInteger.valueOf(mid);
if (bigMid.multiply(bigMid).compareTo(BigInteger.valueOf(n)) >= 0) {
answer = Math.min(answer, mid);
end = mid - 1;
} else {
start = mid + 1;
}
}
System.out.println(answer);
}
}
java에서 자료형
Long - 64비트(-9223372036854775808 ~ 9223372036854775807)
이분탐색으로 중량을 정해두고 BFS로 다리를 지나갈 수 있는지 확인하면 쉽게 풀리는 문제이다.
이렇게 풀 경우 서로 같은 두 도시 사이에 여러 개의 다리가 있다는 조건을 딱히 생각해 줄 필요가 없다.
import java.util.*;
public class Main {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
int v = in.nextInt();
int e = in.nextInt();
LinkedList<Bridge> bridges[] = new LinkedList[v + 1];
for (int i = 1; i <= v; i++) {
bridges[i] = new LinkedList<Bridge>();
}
int max = 0;
for (int i = 0; i < e; i++) {
int start = in.nextInt();
int end = in.nextInt();
int size = in.nextInt();
max = Math.max(max, size);
bridges[start].add(new Bridge(end, size));
bridges[end].add(new Bridge(start, size));
}
int start = in.nextInt();
int end = in.nextInt();
System.out.println(findMinimumWeight(start, end, bridges, max));
}
public static int findMinimumWeight(int from, int to, LinkedList<Bridge> bridges[], int end) {
boolean[] isVisited = new boolean[bridges.length];
int start = 0;
int max = 0;
while (start <= end) {
int mid = (start + end) / 2;
if (BFS(from, to, bridges, mid, isVisited)) { // 가능하니까 일단 결과 저장 후 중량을 더 늘려보자
max = Math.max(max, mid);
start = mid + 1;
} else {
end = mid - 1;
}
}
return max;
}
public static boolean BFS(int start, int end, LinkedList<Bridge> bridges[], int maxSize, boolean[] isVisited) {
clearVisit(isVisited);
Queue<Integer> queue = new LinkedList<Integer>();
queue.add(start);
isVisited[start] = true;
while (!queue.isEmpty()) {
int now = queue.poll();
if (now == end) {
return true;
}
for (Bridge bridge : bridges[now]) {
if (!isVisited[bridge.destination] && maxSize <= bridge.size) {
queue.add(bridge.destination);
isVisited[bridge.destination] = true;
}
}
}
return false;
}
public static void clearVisit(boolean[] isVisited) {
Arrays.fill(isVisited, false);
}
}
class Bridge {
int destination;
int size;
public Bridge(int destination, int size) {
this.destination = destination;
this.size = size;
}
@Override
public boolean equals(Object o) {
Bridge bridge = (Bridge) o;
return destination == bridge.destination;
}
@Override
public int hashCode() {
return Objects.hash(destination);
}
}
출발지점부터 distance 사이에 바위를 제거했을 때, 제거한 바위의 최솟값 중에 가장 큰 값을 구하는 문제이다.
이 문제는 바위를 제거하는 모든 경우를 구한 후 최솟값을 구한다면,
바위가 N개, R개를 제거할 수 있다면 O(NCR)로 시간초과가 발생하게 된다.
이러한 경우에는 바위를 제거하는 모든 경우의 수를 구하기보다는,
바위간의 최소 거리를 정해두고 이 조건이 가능한지 여부를 보는 쪽으로 생각하면 된다.
바위간의 최소 거리를 정할 때에는 이분 탐색을 사용하도록 했다. 풀이 방식은 아래와 같다.
1. 이분 탐색으로 최대 사잇값 diff를 정한다.
2. 돌을 n개 지웠을 때 최소 거리가 diff인지 확인한다.
=> 즉, 돌 사이의 거리가 diff보다 작으면 돌을 없애고,
최종적으로 없애야 하는 돌의 수가 n보다 크면 diff를 너무 크게 잡은 것이므로 왼쪽을 탐색하도록 한다.
class Solution {
public int solution(int distance, int[] rocks, int n) {
int length = rocks.length;
int start = 0;
int end = distance;
int answer = 0;
Arrays.sort(rocks);
while (start <= end) {
int mid = (start + end) / 2;
if (!isPossible(rocks, n, length, mid, distance)) {
// diff가 너무 크니까 줄이자
end = mid - 1;
} else { // 가능하니까 일단 answer에 저장하고 더 늘려보자
answer = Math.max(answer, mid);
start = mid + 1;
}
}
return answer;
}
public boolean isPossible(int[] rocks, int n, int length, int diff, int distance) {
int remove = 0;
int before = 0;
for (int i = 0; i < length; i++) {
if (rocks[i] - before < diff) { // diff보다 작으니 돌을 없애자
remove++;
} else {
before = rocks[i];
}
if (remove > n) { // 돌을 n개보다 더 없애야 하는 경우
return false;
}
}
if (distance - before < diff) {
remove++;
}
return remove <= n;
}
}
배열의 (1, 1)~(n, n)까지 이동할 때, 이동하기 위해 거쳐 간 수들 중 최댓값과 최솟값의 차이가 가장 작아지는 경우를 구하는 문제이다.
배열에서 이동하는 모든 경우를 완전탐색 할 경우 O(4^N)이 걸릴 것이다.
이런 경우 최댓값과 최솟값을 차이를 무작정 구하는 방법 보다는,
최댓값과 최솟값을 차이를 정해두고 가능한지 여부를 보는 방법이 더 쉬울 수 있다.
1차 시도 - 이분탐색을 사용하자
처음 생각한 문제 풀이 과정은 아래와 같다.
1. 이진 탐색으로 최대-최소 차이를 정한다.
2. (1, 1) -> (n, n)로 차이 내에 갈 수 있는지 bfs로 탐색한다.
이 경우에는 차이를 구하더라도 이에 맞는 쌍을 구해야 하는데,
이때 해당하는 쌍을 구할 때 이중for문을 사용하기보다는 두 포인터를 이용하여 시간을 줄이도록 했다.
import java.util.*;
public class Main {
public static int dr[] = { 0, 0, 1, -1 };
public static int dc[] = { 1, -1, 0, 0 };
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
int n = in.nextInt();
int mat[][] = new int[n][n];
TreeSet<Integer> set = new TreeSet<Integer>();
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
mat[i][j] = in.nextInt();
set.add(mat[i][j]);
}
}
int[] numbers = set.stream().mapToInt(i -> i).toArray();
System.out.println(findDifference(numbers, mat, n));
}
private static int findDifference(int[] numbers, int[][] mat, int n) { // 이분탐색
int length = numbers.length;
int start = 0;
int end = numbers[length - 1] - numbers[0];
int answer = Integer.MAX_VALUE;
while (start <= end) {
int mid = (start + end) / 2;
if (findMaxMinFromDifference(mat, numbers, mid, n)) {
answer = mid; // 경로가 존재하니까 일단 저장
end = mid - 1; // 더 줄여보자
} else {
start = mid + 1;
}
}
return answer;
}
private static boolean findMaxMinFromDifference(int mat[][], int[] numbers, int diff, int n) { // 투 포인터
int length = numbers.length;
int start = 0;
int end = 0;
while (start < length && end < length) {
if (numbers[end] - numbers[start] > diff) {
start++;
} else {
if (bfs(mat, numbers[end], numbers[start], n)) {
return true;
}
end++;
}
}
return false;
}
// 최댓값과 최솟값의 차이가 min 보다 클 경우 false 리턴
public static boolean bfs(int[][] mat, int max, int min, int n) { // bfs
if (!isValuePossible(mat[0][0], max, min)) {
return false;
}
Queue<Route> queue = new LinkedList<Route>();
queue.add(new Route(0, 0));
boolean[][] isVisited = new boolean[n][n];
isVisited[0][0] = true;
while (!queue.isEmpty()) {
Route route = queue.poll();
if (route.row == n - 1 && route.col == n - 1) {
return true;
}
for (int i = 0; i < 4; i++) {
int newRow = route.row + dr[i];
int newCol = route.col + dc[i];
if (isBoundary(newRow, newCol, n) && !isVisited[newRow][newCol]
&& isValuePossible(mat[newRow][newCol], max, min)) {
Route newRoute = new Route(newRow, newCol);
isVisited[newRow][newCol] = true;
queue.add(newRoute);
}
}
}
return false;
}
public static boolean isValuePossible(int value, int max, int min) {
if (value < min) {
return false;
}
if (value > max) {
return false;
}
return true;
}
public static boolean isBoundary(int row, int col, int n) {
if (row < 0) {
return false;
}
if (row >= n) {
return false;
}
if (col < 0) {
return false;
}
if (col >= n) {
return false;
}
return true;
}
}
class Route {
int row;
int col;
public Route(int row, int col) {
this.row = row;
this.col = col;
}
}
생각해보니 굳이 이분탐색으로 범위를 줄여서 또 두 포인터로 각각 최대/최소 원소를 구하는 것은 연산이 중복되는 느낌이 들었다..ㅋㅋㅋ
따라서 이분탐색 부분은 제외하고 두 포인터와 bfs를 이용한 풀이로 다시 고쳐보았다.
추가적으로 isVisited의 경우 함수 내에서 계속 새로 할당할 경우 시간이 더 걸릴 수 있으므로 재사용하는 부분을 추가했다.
import java.util.*;
public class Main {
public static int dr[] = { 0, 0, 1, -1 };
public static int dc[] = { 1, -1, 0, 0 };
public static boolean isVisited[][];
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
int n = in.nextInt();
int mat[][] = new int[n][n];
isVisited = new boolean[n][n];
TreeSet<Integer> set = new TreeSet<Integer>();
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
mat[i][j] = in.nextInt();
set.add(mat[i][j]);
}
}
int[] numbers = set.stream().mapToInt(i -> i).toArray();
System.out.println(findMaxMin(mat, numbers, n));
}
private static int findMaxMin(int mat[][], int[] numbers, int n) { // 투 포인터로 max, min 정하기
int length = numbers.length;
int start = 0;
int end = 0;
int answer = Integer.MAX_VALUE;
while (start < length && end < length) {
int diff = numbers[end] - numbers[start];
if (bfs(mat, numbers[end], numbers[start], n)) {
answer = Math.min(answer, diff); // 가능한 경로이므로 일단 저장
start++; // 더 줄여보자
} else {
end++; // 불가능한 경로이므로 diff 범위를 늘리자
}
}
return answer;
}
public static boolean bfs(int[][] mat, int max, int min, int n) { // bfs 가능한 경로 탐색
if (!isPossible(0, 0, n, max, min, mat)) {
return false;
}
clearMatrix(isVisited, n);
Queue<Route> queue = new LinkedList<Route>();
queue.add(new Route(0, 0));
isVisited[0][0] = true;
while (!queue.isEmpty()) {
Route route = queue.poll();
if (route.row == n - 1 && route.col == n - 1) {
return true;
}
for (int i = 0; i < 4; i++) {
int newRow = route.row + dr[i];
int newCol = route.col + dc[i];
if (isPossible(newRow, newCol, n, max, min, mat) && !isVisited[newRow][newCol]) {
Route newRoute = new Route(newRow, newCol);
isVisited[newRow][newCol] = true;
queue.add(newRoute);
}
}
}
return false;
}
public static void clearMatrix(boolean[][] isVisited, int n) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
isVisited[i][j] = false;
}
}
}
public static boolean isPossible(int row, int col, int n, int max, int min, int[][] mat) {
// 바운더리 안에 존재하며, [min, max]인 값임을 확인
if (row < 0) {
return false;
}
if (row >= n) {
return false;
}
if (col < 0) {
return false;
}
if (col >= n) {
return false;
}
if (mat[row][col] < min) {
return false;
}
if (mat[row][col] > max) {
return false;
}
return true;
}
}
class Route {
int row;
int col;
public Route(int row, int col) {
this.row = row;
this.col = col;
}
@Override
public String toString() {
return "(" + row + ", " + col + ")";
}
}
=> O(N^2), N ≤ 100000이므로 1초안에 통과될 수 없다. 아마 10초정도 걸릴것임...ㅠㅠ
dp[n]: n번째 수를 마지막으로 하는 최장증가부분수열로 정의했다.
import java.util.*;
public class Main {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
while (in.hasNextInt()) {
int n = in.nextInt();
int[] stock = new int[n];
int[] dp = new int[n];
int max = 0;
for (int i = 0; i < n; i++) {
stock[i] = in.nextInt();
}
dp[0] = 1;
for (int i = 1; i < n; i++) {
dp[i] = 1;
for (int j = 0; j < i; j++) {
if (stock[i] > stock[j]) {
dp[i] = Math.max(dp[j], dp[j] + 1);
}
}
max = Math.max(max, dp[i]);
}
System.out.println(max);
}
}
}
2차 시도 - N ≤ 100000이므로 1초안에 통과하려면 시간복잡도가 적어도 NlogN을 되어야 한다. => `이분탐색`을 이용한다
stock 수열을 처음부터 보면서
1. dp의 끝 값과 비교했을 때 마지막 값보다 큰 경우 dp의 마지막에 바로 삽입
2. dp의 끝 값과 비교했을 때 마지막 값보다 작거나 같은 경우 이분탐색을 이용하여 LIS를 유지하기 위한 위치에 수를 삽입하도록 한다.
https://www.acmicpc.net/problem/3745 예제
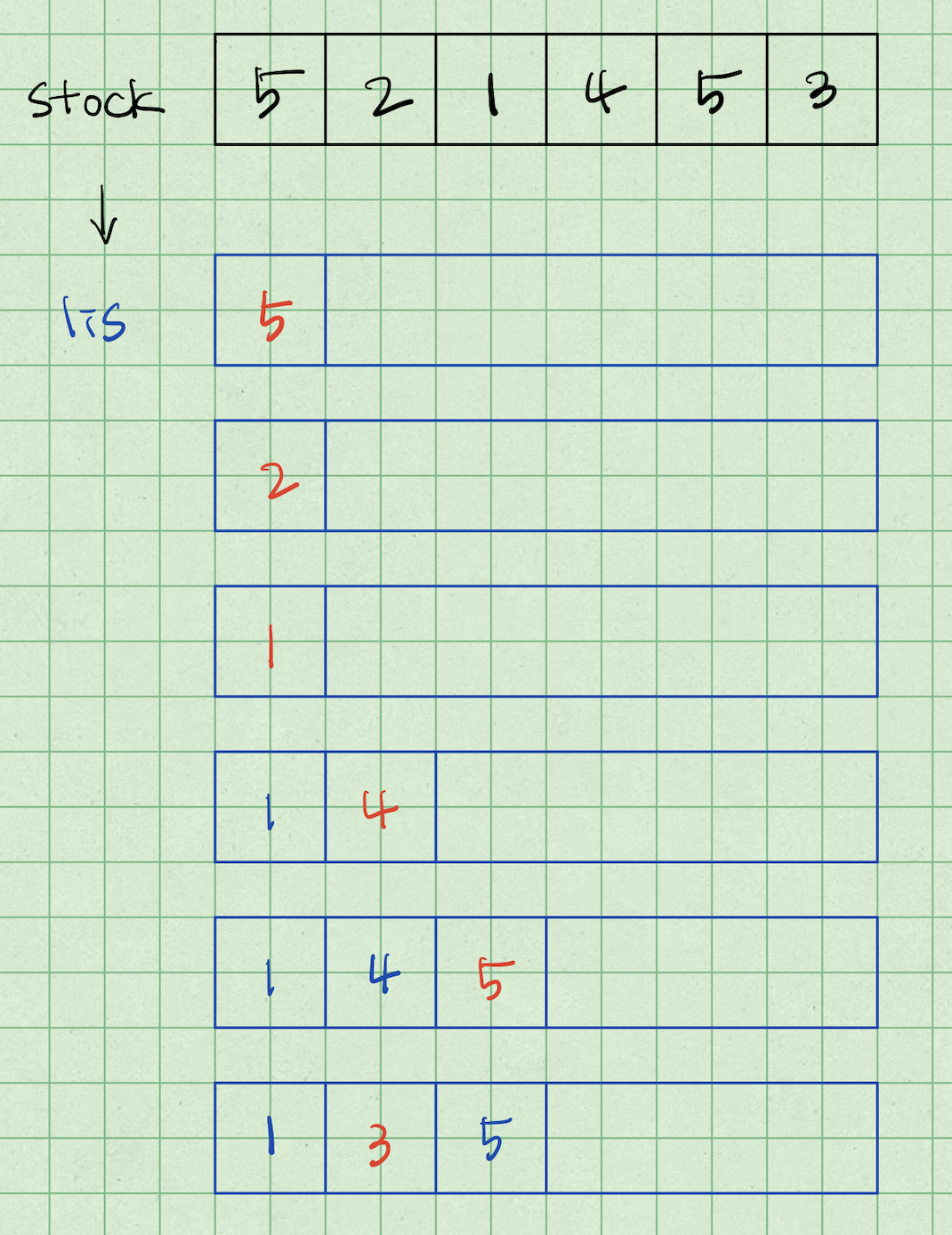
stock[0]을 dp 리스트에 넣는다.
stock[1]이 어디에 삽입될 수 있는지 인덱스를 이분탐색을 이용하여 구한다. (index=0)
stock[2]가 어디에 삽입될 수 있는지 인덱스를 이분탐색을 이용하여 구한다. (index=0)
stock[3]은 1보다 크므로 바로 삽입
stock[4]는 4보다 크므로 바로 삽입
stock[5]가 어디에 삽입될 수 있는지 인덱스를 이분탐색을 이용하여 구한다. (index=1)
예제에서 볼 수 있듯이 최종 dp 수열은 진짜 최장 증가 부분 수열을 이루는 요소와는 상관 없으며, lis의 길이만 연관이 있다는 점이 중요하다
위 알고리즘을 적용하여 코드를 짜 보면 아래와 같다.
import java.util.*;
public class Main {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
while (in.hasNextInt()) {
int n = in.nextInt();
int[] stock = new int[n];
int[] dp = new int[n];
for (int i = 0; i < n; i++) {
stock[i] = in.nextInt();
}
dp[0] = stock[0];
int lastIndex = 0;
for (int i = 1; i < n; i++) {
if (dp[lastIndex] < stock[i]) {
lastIndex++;
dp[lastIndex] = stock[i];
} else {
int index = findIndex(dp, stock[i], lastIndex);
dp[index] = stock[i];
}
}
System.out.println(lastIndex + 1);
}
}
public static int findIndex(int[] dp, int num, int lastIndex) {
int left = 0;
int right = lastIndex;
while (left < right) {
int mid = (left + right) / 2;
if (dp[mid] == num) {
return mid;
}
if (dp[mid] > num) {
right = mid;
} else {
left = mid + 1;
}
}
return right;
}
}
다른 방법으로는 `segment tree`를 사용하는 방법도 있다. segment tree를 사용하여 lis 길이를 구하는 방법은 아래와 같다.
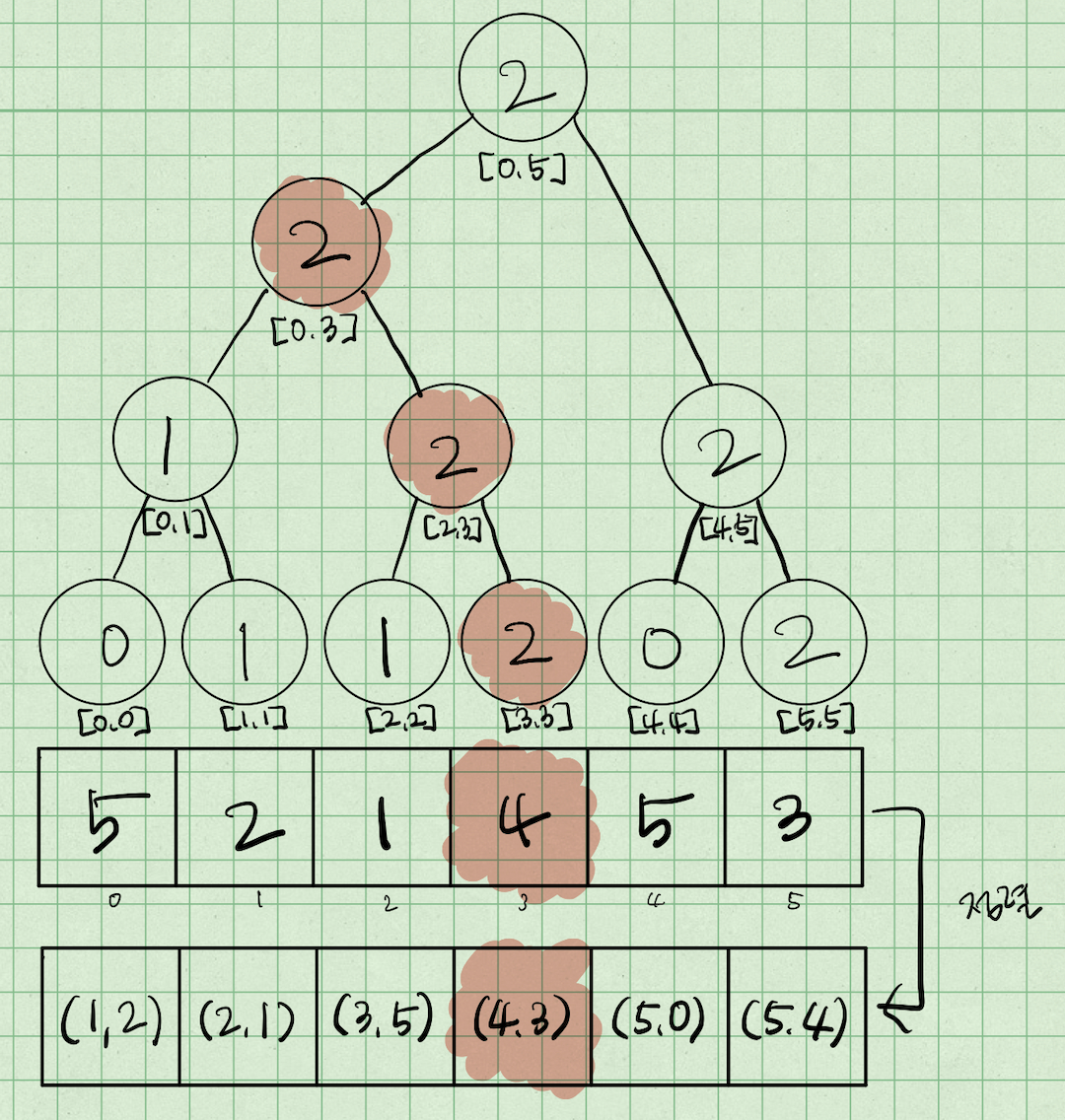
1. 세그먼트 트리를 모두 0으로 초기화한다. , (stock[i], i) 객체를 만든 후 stock[i] 값에 대해 오름차순으로 정렬한다.
2. (stock[i], i)를 순회하면서 stock[i]에 대해구간 [0, i]에서 최댓값을 구하고, 그 최대값+1을 세그먼트 트리의 인덱스 i인 리프 노드 값으로업데이트한다. => i에 대해 구간 [0, i]에 지금까지 존재하는 LIS 길이+1 은 결국 stock[i]으로 끝나는 LIS길이와 같다.
3. 정렬된 객체를 순회하면서 LIS의 max 값을 찾는다.
가장 먼저 stock[i]=1인 i=2를 방문하게 된다.
먼저 구간 [0, 2]의 최댓값은 0이므로 1로 끝나는 LIS 길이는 1이고,
그 1 값을 인덱스 2에 업데이트 해 준다.
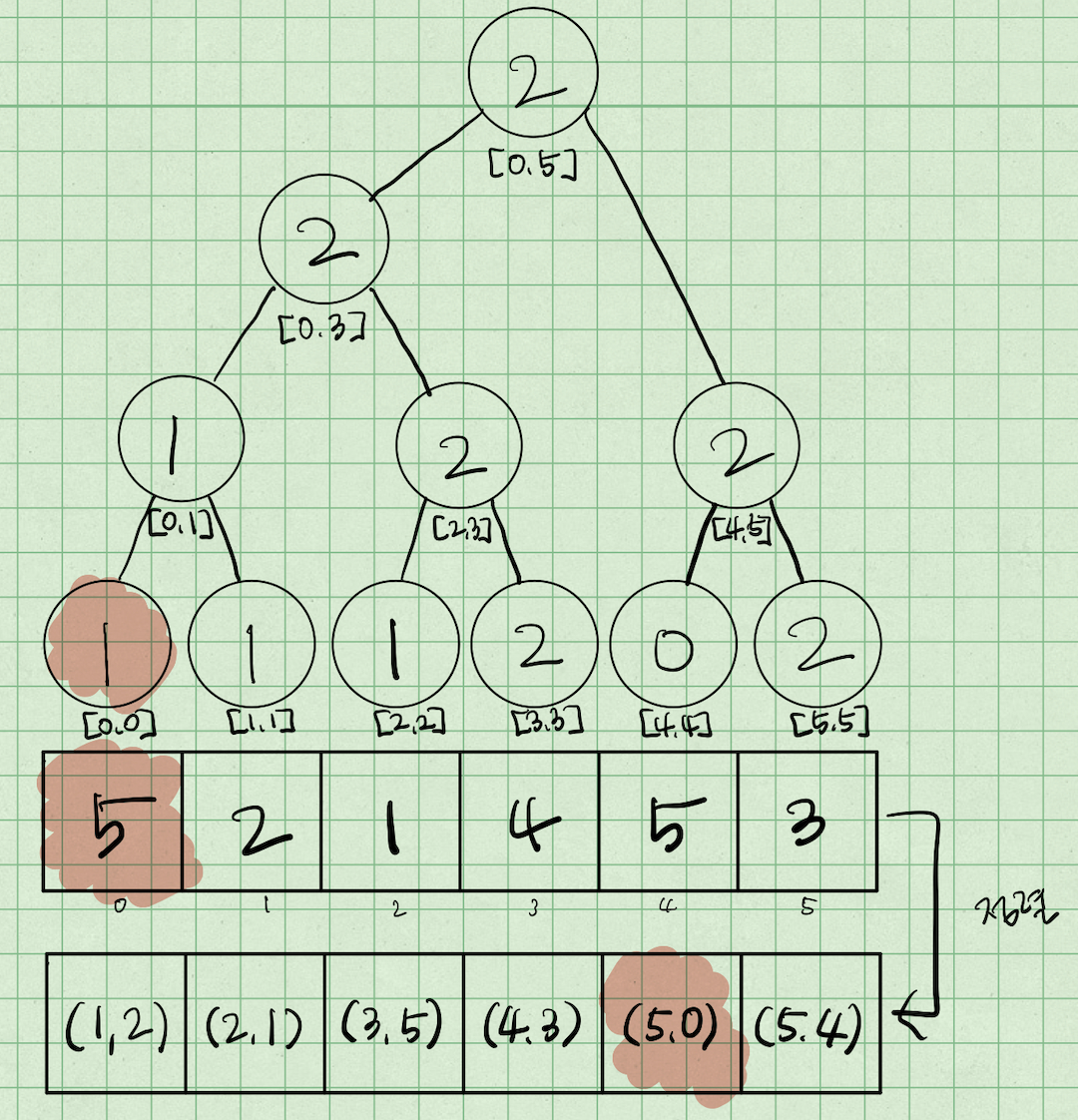
그 다음 stock[i]=2인 i=1를 방문하게 된다.
마찬가지로 [0, 1]의 최댓값은 0이므로 인덱스 1에 업데이트 해준다.
이때, 기존 LIS 결과가 증가하지는 않는다.
일단 이후 값이 언제 증가되는지 좀 더 보기로 하자.
그 다음 stock[i]=3인 i=5를 방문하게 되는데,
[0, 5]의 최댓값은 1이므로 인덱스 5에 2를 업데이트 해준다.
즉, 새로 보는 원소가 기존의 LIS 길이를 증가시키려면
그 원소가 기존의 LIS보다 뒤에 나타나야 한다.
=> 이를 확인하는 것이 결국 구간 [0, i]의 최댓값을 보는 것이다.
이렇게 세그먼트 트리를 이용하여 stock[i]의 위치에 i번째 수를 마지막 원소로 가지는 lis의 길이를 업데이트함으로써 lis의 가장 긴 길이를 구할 수 있다.