💡 요약
- abstract: 대형 딥 뉴럴 네트워크 모델을 효율적으로 모델 병렬화 하는 방법에 관한 연구
- introduction: 큰 용량의 모델은 일반적으로 모델 병렬화하여 학습을 진행하는데, 범용적으로 효율적인 알고리즘을 적용하기 쉽지 않다는 문제가 있다.
- related works: 기존에 모델 병렬처리를 통해 네트워크를 서로 다른 계산 단위로 분할 후 이를 서로 다른 장치에 배치했는데, 낮은 하드웨어 활용률과 통신 병목 현상이 문제가 되었다. 이후, Single Program Multiple Data 및 파이프라인 병렬화가 제안되었는데, 병렬화된 각 행렬 곱셈의 결과값을 결합(AllReduce)하는데 사용되는 연산이 통신 오버헤드의 원인이 되었으며 특정 네트워크 아키텍쳐에 종속적이었다.
- method: Pipeline Model Parallelism(micro-batch) & Rematerialization
- experiment: 이미지 분류(AmoebaNet)과 기계번역(Transformer) 모델로 테스트 해 본 결과, Rematerialization 에 의해 단일 가속기에서도 메모리 요구량을 줄일 수 있었으며 모델 병렬화를 통해 모델을 확장할 수 있었다.
- conclusion & discussion: GPipe는 전체 미니 배치에 대해 단일 동기식 그라데이션 업데이트를 적용하기 전에, 마이크로 배치의 실행을 파이프라인화하는 Rematerialization과 결합한 새로운 파이프라인 병렬 처리를 도입했으며, 추가적인 통신 오버헤드가 없어 가속기 수에 따라 거의 선형적으로 확장할 수 있다. 단, 모델을 분할할 때 레이어의 파라미터가 불균형하게 분포하는 경우 가속기 수에 따라 완벽하게 선형 확장되지 않는다.
Introduction
딥 러닝이 발전하면서 모델의 파라미터 사이즈가 증가함에 따라 정확도가 비례하도록 개선되는 것을 관찰할 수 있었다.

하지만, 하드웨어적인 한계로 인해 큰 모델을 학습하는 것은 상당한 제약을 따른다.
일반적으로 학습의 양이 많을 때, 분산 학습을 하게 되는데 두 가지 처리 방식이 있다.

- Model Parallelism: 모델의 자체의 크기가 커서 메모리가 부족할 때 사용한다. 각 디바이스는 모델의 일부분을 가지며, 결과값을 다른 디바이스에 넘겨주며 학습을 진행한다.
- Data Parallelism: 데이터 셋의 크기가 커서 메모리가 부족할때 주로 사용한다. 각 디바이스는 각각 전체 모델의 사본을 가지고 있으며, 분할된 데이터로 각자 학습 시킨 후 결과를 취합한다.
본 논문에서는 모델 병렬화에서 다루고 있는데 모델 병렬화는 효율적인 알고리즘을 구현하기 어렵고, 만약에 효율적인 알고리즘을 구현하더라도 특정 아키텍쳐나 태스크에 종속된다는 단점을 가진다. 또한, 예시 그림을 살펴보면 모델 병렬화는 데이터가 device1 -> (device2, device3) -> device4 으로 전달된다. 즉, 훈련 시 이전 레이어가 끝날때까지 기다려야 한다.
Method
GPipe는 각 레이어에서 일어나는 계산을 (1)파이프라이닝하여 병렬 처리하며, (2) Rematerialization을 활용하여 메모리 효율을 높인다.
## Pipeline Model Parallelism
모델 학습 시에는 각 레이어에서 forward propagation을 통해 loss를 계산하고, backward propagation에서 loss가 최소가 되도록 gradient를 구한다. 이 레이어를 각 디바이스에 나누면 그림 (b)와 같이 배치되는데, 앞쪽에서 결과값이 업데이트 될 때까지 기다려야하는 bubble time이 존재한다.
이 bubble time을 줄이기 위해서 본 논문에서는 그림 (c)와 같이 N개의 mini batch를 각각 M개의 동일한 micro batch로 나누어 학습을 진행한다. 그림 (c)를 보면 micro batch만 계산 후 결과값을 다음 레이어로 넘기기 때문에 다른 디바이스가 계산을 보다 빨리 시작할 수 있다.
만약 네트워크에서 batch normalization이 이루어지는 경우, 각 계산은 micro-batch에 대한 통계를 사용하지만, evaluation을 위해 mini-batch 통계를 축적한다.. 그리고 장치 간 통신은 모든 micro-batch의 파티션 경계에서만 이루어진다. 이때, 디바이스간 데이터 전송 오버헤드가 있을 수 있지만, activation tensor만 전달하면 되기 때문에 통신 오버헤드는 무시할 수 있을만큼 작음을 관찰할 수 있었다.
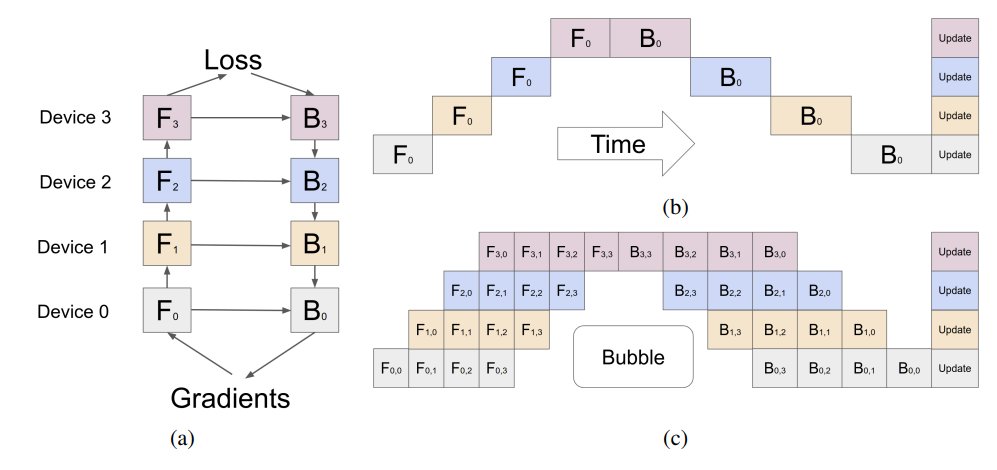
bubble time은 O((K-1)/(M+K-1)) 으로 M>=4K일때 거의 무시할 수 있음을 실험을 통해 관찰할 수 있었다.
- K: partition 개수
- M: device 개수
- 이전 Layer의 계산이 끝날때까지 기다리지 않고도 backward pass 중 재 계산을 더 일찍 스케줄링 할 수 있기 때문
## Rematerialization
sequential layer 입력값을 제외하고 이후 back propagation에서 재사용 될 가능성이 있는 중간 계산 값들을 메모리에 store&load 하는 대신, 값을 일단 버리고 나중에 다시 필요할 때 재계산한다. 그 결과 메모리 요구량은 O(N*L) -> O(N+(L/K)*(N/M)) 으로 줄어든다.
- L: layer 갯수
- K: partition 갯수
- N: mini batch 갯수
- M: 디바이스 갯수
- N/M: micro batch 크기
- L/K: 파티션 당 레이어 수
- 메모리 요구량 = 그래디언트(bi)를 계산하는 데 상위 레이어 그래디언트(bi+1)와 캐시된 activation(fi(x))가 모두 필요
하지만 forward computation을 2번 계산 해야하기 때문에, 약 25% 정도 시간이 더 걸린다. 이 대기 시간을 더욱 줄이기 위해서 아래 그림과 같이 pipeline을 조정할 수 있다.
Experiment

- Naive-1: GPipe가 없는 sequential 한 버전
- Pipeline-k: k개의 가속기에 분할하여 학습
- AmoebaNet-D(L,D): cloud TPUv2s (8GB memory each)
- L: 일반 셀 레이어 갯수
- D: 필터 크기
- 입력 이미지 크기 (224,224), 미니배치 크기 128
- Transformer-L: cloud TPUv3s (16GB memory each)
- L개 layer, 각 레이어의 dimension 2048, feed-forward hidden dimensions 8192, attention heads 32
- 어휘 크기 32k, 시퀀스 길이 1024, 배치 크기 32
Rematerialization의 결과
- AmoebaNet: Gpipe는 back propagation과 batch splitting에 의해 중간에 계산되는 activation memory 요구량을 6.26GB->3.46GB(Peak Activation Memory)로 줄여 단일 가속기에서 318M 파라미터 모델을 구현할 수 있다.
- Transformer: 단일 가속기에서 2.7배 더 큰 모델을 훈련할 수 있다.
Model Parallelism의 결과
- AmoebaNet: 모델 병렬화를 통해 8개의 가속기에서 아메바넷을 18억개의 파라미터로 확장할 수 있었다. (약 25배)
- Transformer: 128개의 파티션으로 구성된 GPipe를 사용하면 839억개의 파라미터까지 확장할 수 있다 (약298배)
* AmoebaNet와 Transformer의 확장이 차이나는 이유는?
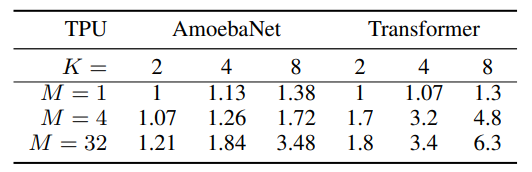
뉴럴 넷 모델의 경우 레이어마다 메모리 요구 사항 및 계산량이 불균형한 경우가 있는데, 이러한 경우에는 불완전한 파티셔닝 알고리즘으로 인해 부하 불균형이 발생할 수 있다. 표에서 살펴볼 수 있듯이, 마이크로 배치 수(K)가 많을수록 성능이 향상하며, 아메바넷은 모델 파라미터의 불균형한 분포로 인해 최대 모델 크기가 완벽하게 선형적으로 확장되지 않았다. 이는 아메바넷의 여러 레이어에 걸쳐 모델 파라미터가 불균형하게 분포되어 있기 때문이다. 트랜스포머 모델의 경우는 각 레이어의 파라미터 수와 입력 크기가 동일하기 때문에, 최대 모델 크기는 Transformer의 가속기 수에 따라 선형적으로 확장될 수 있었다.
이 표에서 관찰할 수 있는 것은, M이 상대적으로 작은 경우 대기 시간을 더 이상 무시할 수 없게 된다는 점이다. M=1이면 사실상 파이프라인 병렬화가 존재하지 않아 사용되는 가속기 수에 관계없이 비교적 일정한 처리량을 관찰할 수 있었다. (주어진 시간에 한 대의 장치만 계산=병렬화X)
Discussion
결론적으로 GPipe의 세 가지 핵심 속성은 아래와 같다
1) 효율성: 새로운 배치 분할 파이프라이닝 알고리즘을 사용하는 GPipe는 장치 수에 따라 거의 선형적인 속도 향상을 달성한다.
2) 유연성: GPipe는 모든 순차적 신경망을 지원한다.
3) 신뢰성: GPipe는 synchronous gradient descent을 활용하며, 파티션 수에 관계없이 일관된 훈련을 보장한다.
stochastic gradient descent - https://light-tree.tistory.com/133
RMSProp - https://box-world.tistory.com/69
카카오에서 TPU 대신 CUDA를 사용하는 pytorch용 gpipe를 구현해둔게 있어서 한번 보면 좋을 것 같음 - https://github.com/kakaobrain/torchgpipe
'논문을 읽자' 카테고리의 다른 글
| An analysis of Facebook photo caching (0) | 2023.04.13 |
|---|---|
| AI4DL: Mining Behaviors of Deep Learning Workloads for Resource Management (0) | 2023.03.24 |
| Joint Task Scheduling and Containerizing for Efficient Edge Computing (0) | 2023.03.20 |
| An Empirical Study of Memory Sharing in Virtual Machines (0) | 2022.05.18 |
| 정보보호론 프로젝트: 커널 취약점과 보호기술에 관한 논문 survey (0) | 2021.06.18 |