Linux와 같은 상용 커널은 제한된 유형 및 메모리 안전 보장 만 제공하는 저수준 프로그래밍 언어로 작성되어
공격자가 메모리 손상 취약성을 악용하여 커널에 대해 정교한 런타임 공격을 시작할 수 있다.
아래 논문을 읽고, 리눅스 커널 취약점과 각 도구의 특징 및 구조를 비교해 보았다.
[ACM 2011] Linux kernel vulnerabilities: State-of-the-art defenses and open problems
[CCS 2016] UniSan: Proactive Kernel Memory Initialization to Eliminate Data Leakages
[NDSS 2018] K-Miner: Uncovering Memory Corruption in Linux
[USENIX 2019] PeX: A permission check analysis framework for Linux kernel
[NDSS 2021] KUBO: Precise and Scalable Detection of User-triggerable Undefined Behavior Bugs in OS Kernel
커널은 종종 신뢰할 수있는 컴퓨팅 기반의 일부이기 때문에 커널 취약성을 방지하는 것은 많은 시스템의 보안을 달성하는 데 중요하다. Linux 커널 취약성에 대한 두 가지 사례 연구를 제시하여 커널 보호 기술과 관련하여 현재의 최신 기술을 평가하고 있다.
Linux에는 10 가지 일반적인 커널 취약점 클래스가 있으며,이 취약점은 임의의 메모리 수정에서 정보 유출, 서비스 거부 공격에 이르는 다양한 공격으로 이어질 수 있다. 취약점의 약 2/3가 커널 모듈이나 드라이버에 있고, 반대로 1/3의 버그가 코어 커널에서 발견되며, 단일 기술이 모든 커널 취약점을 막을 수는 없다.

- Missing Pointer Check - 커널은 access_ok 검사를 생략하거나 __get_user와 같은 더 빠른 작업을 오용한다. 이 작업은 사용자가 제공한 포인터 또는 인덱스 변수의 값을 확인하지 않고 사용자 공간 메모리만 가리키도록 함. ⇒ 권한이없는 프로세스가 임의의 커널 메모리 위치에서 읽거나 쓸 수 있도록하여 메모리 손상 (CVE-2010-4258), 정보 공개 (CVE-2010-0003), DoS (CVE-2010-2248) 또는 권한 에스컬레이션(CVE-2010-3904 및 CVE-2010-3081)으로 이어진다.
- Missing Permission Check - 커널은 호출 프로세스에 권한이 있는지 여부를 확인하지 않고 권한있는 작업을 수행한다. 이 범주의 취약점은 커널 보안 정책을 위반하게 된다. ⇒ 임의 코드 실행 (CVE-2010-4347), 권한 상승 (CVE-2010-2071 및 CVE-2010-1146), append-only 파일 덮어 쓰기(CVE2010-2066 및 CVE-2010-2537)
- Buffer Overflow - 커널이 버퍼에 액세스 할 때 상한 또는 하한을 잘못 확인하고 (CVE-2011-1010), 예상보다 작은 버퍼를 할당하고 (CVE-2010-2492), 안전하지 않은 문자열 조작 함수를 사용한다(CVE-2010-1084). 또는 커널 스택에 비해 너무 큰 지역 변수를 정의한다(CVE-2010-3848). ⇒ 메모리 손상 (쓰기 용) 또는 정보 공개 (읽기 용) 공격을 하며 공격자는 근처의 함수 포인터를 덮어 쓰고 커널의 제어 흐름 무결성을 파괴하여 권한 상승 공격을 수행 할 수 있다.
- Integer Overflow - 커널이 정수 연산을 잘못 수행하여 정수 오버플로, 언더 플로 또는 부호 오류가 발생하면, 공격자는 메모리를 할당하거나 액세스하는 데 잘못된 값을 사용하도록 커널을 속여 <버퍼 오버플로> 취약점이 허용하는 것과 유사한 공격을 허용 할 수 있다. ⇒ 곱셈 후 overflow가 발생하면 커널이 필요보다 작은 버퍼를 할당 할 수 있다(CVE-2010-3442). 빼기 후 underflow은 버퍼 끝을 넘어서 메모리 손상을 일으킬 수 있다(CVE-2010-3873). 비교 중 부호 오류는 경계 검사를 우회하고 정보 공개를 유발할 수 있다(CVE-2010-3437).
- Uninitialized data - 커널은 사용하지 않는 필드를 제로화하지 않고 커널 버퍼의 내용을 사용자 공간에 복사하므로 커널 스택의 변수와 같은 잠재적으로 민감한 정보가 사용자 프로세스에 유출된다 (CVE-2010-3876). ⇒ 이 범주에는 모든 범주 중 가장 높은 29 개의 취약점이 있고, 의도하지 않은 정보 공개를 초래한다. 또한 일부 커널 데이터 구조의 정확한 주소, 개인 커널 키 또는 기타 커널 임의성을 알아야하는 공격과 같은 다른 공격을 가능하게 할 수 있다.
- Memory mismanagement - 외부 메모리 소비 (CVE-2011-0999), 메모리 누수 (CVE-2010-4249), 이중 사용 가능 (CVE-2010-3080) 및 사용 후 사용 오류 (CVE-2010-3080)와 같은 커널 메모리 관리의 취약성이 포함된다. (CVE-20104169 및 CVE-2010-1188). ⇒ 일반적으로 임의의 메모리 손상이 가능하며, 공격자는이를 악용하여 DoS 공격을 수행 할 수 있다.
- Miscellaneous - 널 포인터 역 참조, 0으로 나누기 (CVE-2011-1012 및 CVE2010-4165), 무한 루프 (CVE-2011-1083 및 Null 포인터 역 참조)와 같이 일반적으로 프로세스 충돌, 커널 패닉 또는 중단을 초래할 수 있다(CVE-2010-1086) 교착 상태 (CVE-2010-4161), 데이터 경합 (CVE-2010-4526 및 CVE-2010-4248).
- 해결 방안
- Runtime Tools
- Software fault isolation (BGI Tool) - 커널과 모듈 간의 제어 된 공유를 지원하여 커널 모듈을 분리하는 도구이며, BGI는 각 모듈에 대한 메모리 액세스 제어 목록(ACL)을 제공한다. BGI를 사용하는 프로그래머는 ACL을 설정하고, 핵심 커널에서 다양한 기능을 호출 할 때 모듈의 권한을 부여하거나 취소할 수 있다 (예 : 메모리 할당시 액세스 권한 부여, 메모리 해제시 액세스 취소).
- 장점 - BGI는 취약한 모듈이 이중없는 버그 및 일부 버퍼 오버 플로우와 같이 액세스 권한이 없어야하는 커널 메모리를 덮어 쓰는 것을 방지 할 수 있다.
- 단점 - 액세스 권한이 있어야하는 커널 메모리에 대한 액세스는 허용한다. 즉, 모듈 내부의 취약점과 버그가있는 모듈의 경계를 넘으려는 특정 공격만 처리한다.
- ex) 파일 시스템 모듈에 버퍼 오버플로 취약점이있는 경우 공격자는 모듈의 내부 데이터를 변조하고 모듈이 setuid 바이너리에만 적용되는 코드를 실행하도록 속여 루트 권한을 얻을 수 있음
- Code integrity (SecVisor) - 커널에 코드 무결성을 적용한다. 얇은 하이퍼 바이저 계층은 해당 코드가 커널 모드에서 실행되도록 허용되기 전에 모든 코드를 인증한다.
- 장점 - SecVisor는 코드 삽입 공격을 방지하는 데 효과적이다.
- 단점 - SecVisor의 존재를 인식하지 못하는 일반적인 공격을 방어 할 수는 있지만 지속적인 공격자는 중요한 커널 데이터를 손상 시키거나 기존 커널 코드에 대한 제어 흐름을 가로 채어 공격을 가할 수 있다. 즉, SecVisor는 공격을 작성하기 어렵게 만들지만 공격자가 취약성을 악용하는 것을 막지는 못한다.
- User-level drivers (SUD)
- 장점 - 사용자 수준에서 장치 드라이버를 실행하고 드라이버의 취약점이 커널의 나머지 부분에 영향을 미치지 않도록 한다. (드라이버 자체를 충돌시켜 서비스 거부 공격으로 전환) DoS 영향을 완화하려면 섀도우 드라이버와 같은 별도의 복구 메커니즘이 필요하다.
- 한계점 - 커널 보안 취약성의 극히 일부만이 장치 드라이버에서 발생하며, 사용자 수준 드라이버가 다른 취약성은 해결하지 못한다.
- Memory tagging (Raksha)
- 장점 - 커널 코드가 신뢰할 수 없는 입력 (사용자 프로세스 또는 네트워크에서)을 오용하는 경우, 이를 감지하여 공격자가 코드 삽입 공격을 수행하거나 제어 흐름을 장악하는 것을 방지 할 수 있다.
- 단점 - SecVisor와 마찬가지로 이는 커널 제어 흐름에 의존하지만 다른 많은 취약점을 해결하지 못하며 특정 유형의 악용만 방지한다.
- Uninitialized memory tracking
- Kmemcheck - 주어진 워크로드에 대해 초기화되지 않은 메모리 취약성을 감지하는 Linux 커널의 런타임 도구로, 커널 메모리 할당 자의 도움으로 각 메모리 바이트의 초기화 상태를 추적한다.
- 장점 - 커널 코드가 초기화되지 않은 메모리를 통해 민감한 데이터를 유출하는 문제를 구체적으로 해결할 수 있다.
- 단점 - 스택에서 초기화되지 않은 데이터 읽기를 감지 할 수 없다.
- SD (Secure Delocation)
- 장점 - 주기적으로 커널 스택을 제로화하여 초기화되지 않은 스택 변수의 정보 누출을 줄인다.
- 단점 - 동적으로 할당 된 객체를 처리하지는 않는다.
- 단점 - 버그를 악용하기 더 어렵게 만들지만 모든 정보 공개 버그를 찾아 예방할 수는 없다.
- Kmemcheck - 주어진 워크로드에 대해 초기화되지 않은 메모리 취약성을 감지하는 Linux 커널의 런타임 도구로, 커널 메모리 할당 자의 도움으로 각 메모리 바이트의 초기화 상태를 추적한다.
- Software fault isolation (BGI Tool) - 커널과 모듈 간의 제어 된 공유를 지원하여 커널 모듈을 분리하는 도구이며, BGI는 각 모듈에 대한 메모리 액세스 제어 목록(ACL)을 제공한다. BGI를 사용하는 프로그래머는 ACL을 설정하고, 핵심 커널에서 다양한 기능을 호출 할 때 모듈의 권한을 부여하거나 취소할 수 있다 (예 : 메모리 할당시 액세스 권한 부여, 메모리 해제시 액세스 취소).
- Runtime Tools
- 한계점
- 취약점은 장치 드라이버, 커널 모듈 및 핵심 커널 코드를 포함하여 커널의 거의 모든 부분에 존재하므로, 커널 모듈과 같이 커널의 한 부분에만 집중하는 솔루션은 그 자체로는 충분하지 않다.
- 많은 런타임 도구는 특정 종류의 취약성에 대한 악용을 방지하는 대신 특정 종류의 악용을 방지하는 데 중점을 두기 때문에, 주어진 취약점을 알고있는 공격자는 대상 시스템에서 작동하는 모든 악용을 자유롭게 선택할 수 있으므로 차이점이 중요하다. 따라서 어떤 방식 으로든 취약성을 악용 할 수있는 방어 메커니즘은 제한적으로 사용된다.
- Linux가 안전하지 않은 언어로 모놀리식하게 작성되었다는 사실에서 많은 취약점이 계속해서 발생한다.
UniSan: Proactive Kernel Memory Initialization to Eliminate Data Leakages
운영 체제 커널은 대부분의 컴퓨터 시스템에서 사실상 신뢰할 수있는 컴퓨팅 기반이다.
OS 커널을 보호하기 위해 공격 (예 : 코드 재사용 공격)을 방어하기 위해 kASLR 및 StackGuard와 같은 많은 보안 메커니즘이 점점 더 많이 배포되었지만, 이러한 보호의 효과는 아직 부족하다. 커널에는 무작위 포인터 또는 canary를 유출하여 kASLR 및 StackGuard를 우회하는 많은 정보 유출 취약성이 있다. 암호화 키 및 파일 캐시와 같은 커널의 다른 민감한 데이터도 유출 될 수 있다. 대부분의 커널 정보 누출은 초기화되지 않은 데이터 읽기로 인해 발생한다. 안타깝게도 메모리 안전 시행 및 동적 액세스 추적 도구와 같은 기존 기술은이 위협을 완화하기에 충분하거나 효율적이지 않다.
UniSan - OS 커널에서 초기화되지 않은 읽기로 인한 모든 정보 유출을 제거하기위한 새로운 컴파일러 기반 접근 방식으로, 할당이 커널 공간을 떠날 때 완전히 초기화되었는지 여부를 확인하기 위해 바이트 수준, 흐름 민감, 컨텍스트 민감 및 필드 민감 초기화 분석 및 도달 가능성 분석을 사용한다. 그렇지 않은 경우 커널을 자동으로 계측하여 이 할당을 초기화한다. UniSan의 분석은 오탐을 방지하기 위해 보수적이며 OS 커널의 의미를 보존하여 강력하다. UniSan을 LLVM 패스로 구현했고, 43 개의 알려진 데이터 및 많은 새로운 초기화되지 않은 데이터 유출 취약점을 성공적으로 예방할 수 있다. 또한 최신 커널의 19 가지 새로운 취약점이 Linux와 Google에 의해 확인되었다. LMBench, ApacheBench, Android 벤치 마크 및 SPEC 벤치 마크를 사용한 광범위한 성능 평가에서도 UniSan이 무시할 수있는 성능 오버 헤드를 부과하는 것으로 나타났다.
<특징>
- 초기화되지 않은 데이터 읽기로 인한 커널 정보 누출을 방지하는 데 중점을 둔다.
- 정적 분석에 의해 안전하지 않은 것으로 감지 된 할당 된 메모리를 선택적으로 제로화
- 자동화 된 컴파일러 기반 접근 방식 ⇒ 소스 코드를 수동으로 수정할 필요가 없으며 데이터 구조 패딩 또는 부적절한 초기화로 인한 누출을 투명하게 제거 할 수 있다.
- 절차 간 정적 분석을 활용하여 1) 할당이 커널 공간을 벗어나는지 여부와 2) 할당이 누출 지점까지 가능한 모든 실행 경로를 따라 완전히 초기화되었는지 확인 ⇒ 이전의 강제 초기화 접근 방식의 모든 한계를 극복
- 커널 공간을 떠나기 전에 가능한 실행 경로에서 초기화 된 것으로 입증 될 수없는 할당의 1 바이트가있는 한 안전하지 않은 것으로 간주된다.(보수적인 판단) ⇒ 거짓 음성이 없다.
- 스택 및 힙 할당을 모두 처리하며, 정밀도를 향상시켜 오탐을 최소화하기 위해 UniSan의 분석은 세분화되어 할당의 각 바이트를 흐름과 상황에 맞는 방식으로 추적 ⇒ 안전하지 않은 할당을 감지하면 할당의 초기화되지 않은 부분을 0으로 설정하도록 커널을 계측
<구조>
Unisan(Uninitialized Data Leak Sanitizer): 정적 분석에 의해 안전하지 않은 것으로 감지 된 할당 된 메모리를 선택적으로 제로화
UniSan은 분석 및 계측이 수행되는 커널 소스 코드에서 컴파일 된 LLVM IR (즉, 비트 코드 파일)을 입력으로 사용하고, 출력으로 보안 IR을 자동으로 생성한다.

- 할당 감지기
- 커널을 분석하고 완전히 초기화되지 않은 채 커널 공간을 벗어날 수있는 모든 잠재적 안전하지 않은 개체를 보수적으로 식별
- 도달 가능성 분석 및 초기화 분석을 통합하여 커널 공간을 떠날 때 할당 바이트가 초기화되지 않았는지 확인한다.
- 스택 또는 힙 할당이 주어지면 UniSan은 정적 데이터 흐름 (taint) 분석을 활용하여이 할당이 copy_to_usr 및 sock_sendmsg와 같은 사전 정의 된 싱크에 도달 할 수 있는지 확인한다. ⇒ 전파 경로를 따라 UniSan은 할당의 각 바이트에 대한 초기화 상태도 추적한다. 할당의 바이트가 가능한 실행 경로에서 초기화되지 않은 채 싱크에 도달하면 UniSan은이를 안전하지 않은 것으로 간주한다.
- 할당 initializer
- memset를 삽입하거나 할당 플래그를 변경하여 초기화되지 않은 메모리를 제로화, 즉 감지 된 안전하지 않은 할당을 자동으로 초기화
- 모든 안전하지 않은 할당을 수집 한 후 UniSan은 바로 뒤에 초기화 코드를 사용하여 IR을 계측한다.
- 스택 할당의 경우 UniSan은 memset 또는 zero-initiailzation을 삽입하여 초기화한다.
- 힙 할당의 경우 UniSan은 할당 함수 (예 : kmalloc)에 __GFP_ZERO 플래그를 추가한다.
- 계측 된 비트 코드 파일을 조립하고 연결하여 UniSan은 보안 커널 이미지를 생성한다.
<평가>
- 약 2000개의 모듈
- 약 1,500 개의 안전하지 않은 스택 할당과 300 개의 안전하지 않은 힙 할당을 감지
- 최신 Linux 커널 및 Android 커널에서 19 개의 새로운 초기화되지 않은 데이터 유출을 확인
- I / O 집약적 인 서버 프로그램에 미치는 성능 영향을 측정하기 위해 ApacheBench를 사용하여 Apache 웹 서버의 성능을 테스트

<장단점>
- 장점
- 바이트 수준 감지를 수행하므로 정적으로 할당 된 총 바이트 수와 감지 된 안전하지 않은 바이트도 보고할 수 있다
- 초기화 횟수를 최소화하여 성능 오버 헤드를 제어 할 수 있다. ⇒ 최대 오버 헤드는 7.1 %입니다. 또한 UniSan의 성능 오버 헤드는 대부분의 경우 무시할 수있는 수준 (<1 %)임을 알 수 있다.
- 한계점
- 커널 소스 코드가 필요하다
- 제로 초기화의 보안적 영향 - 일부 시스템은 초기화되지 않은 메모리를 임의의 소스로 사용하는데, (ex. OpenSSL의 SSLeay 구현은 초기화되지 않은 버퍼를 엔트로피 소스로 사용하여 난수를 생성 - ssleay_rand_bytes () 참조) 제로 초기화는 이러한 임의성 소스의 엔트로피를 감소시킨다.
- false positive - UniSan은 정확도를 희생하여 거짓 음성을 제거하고 있다. (즉, 거짓 양성 비율을 높임).
- 기본 커널 구성에서 활성화 된 모듈만 포함되고 있다. 현재 Linux 커널에는 총 20,000 개의 모듈이 있으므로 대부분은 평가에 포함되지 않았고, LLVM에서 컴파일 할 수 없는 모듈도 많기 때문에 패치를 위해 추가적인 노력이 필요하다.
- user space 프로그램을 지원하기 위해서는 라이브러리의 IR도 포함하고 소스 (힙용)와 싱크를 재정의 해야 한다.
K-Miner: Uncovering Memory Corruption in Linux
<특징>
- Linux와 같은 대형 상용 운영 체제 커널을 효율적으로 분석하고 가능한 메모리 손상을 감지 할 수 있는 프레임워크
- 커널 코드의 고도로 표준화 된 인터페이스 구조를 활용하여 확장 가능한 포인터 분석을 가능하게 하고, 상황에 맞는 글로벌 분석을 수행
- 최신 OS 커널의 정확한 절차 간 정적 분석을 가능하게하기 위해 대규모 코드 기반, 복잡한 상호 의존성 및 전역 커널 포인터와 메모리 개체 간의 aliasing 관계 처리와 같은 여러 가지 문제를 해결한다.
- 절차 간 분석을 통해 K-Miner는 댕글링 포인터, 사용자 애프터 프리, 이중 자유 및 이중 잠금 취약성과 같은 여러 등급의 메모리 손상 취약성을 체계적이고 안정적으로 발견할 수 있다.
- 제시된 프레임 워크는 확장 가능하며 추가 분석 패스를 추가하는 것은 간단하다. K-Miner에는 보고 및 협업을 용이하게하는 웹 기반 사용자 인터페이스가 포함되어 있다. 또한 경보수 및 성능에 대한 광범위한 그래프 기반 분석 개요 및 통계를 제공한다.
<구조>
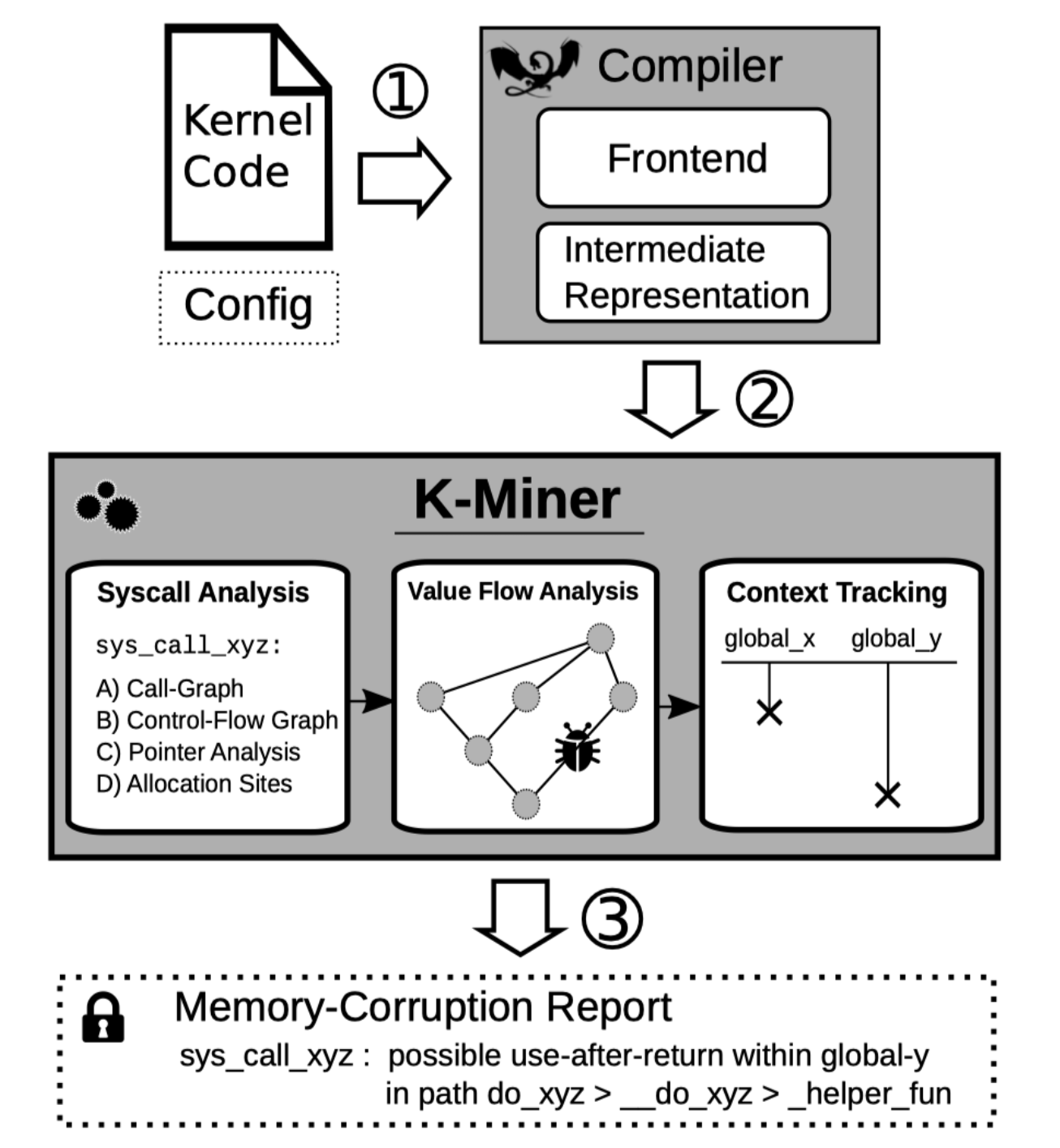
- 기존 컴파일러 제품군 LLVM 위에 구축된다. 컴파일러(1 단계)는 두 개의 입력을 받는다.
- 선택한 커널 기능 목록이 포함 된 구성 파일 - 사용자는 개별 커널 기능을 선택하거나 선택 취소 할 수 있다. (기능이 비활성화되면 해당 코드가 구현에 포함되지 않음) 따라서 분석 결과는 특정 쌍의 커널 코드 및 구성 파일에 대해서만 유효하다.
- 컴파일러 제품군은 구성에 따라 커널 코드를 구문 분석합니다. 코드를 구문 적으로 확인하고 AST (추상 구문 트리)를 만든다. 그런 다음 컴파일러는 내부적으로 AST를 소위 중간 표현 (IR)으로 변환한다.이 표현은 본질적으로 추상적인 가상 머신 모델을 나타낸다. IR은 일련의 변환 과정을 통해 커널 코드를 분석하고 최적화하는 데도 사용된다.
- 컴파일러는 커널의 IR을 K-Miner에 대한 입력으로 전달하여 모든 시스템 호출 목록을 통해 코드를 정적으로 확인한다.
- 모든 시스템 호출에 대해 K-Miner는 시스템 호출 함수의 진입점을 다음과 같이 사용하여 호출 그래프 (CG), 값 흐름 그래프 (VFG), 포인터 분석 그래프 (PAG) 및 기타 여러 내부 데이터 구조를 생성한다.
- 데이터 구조가 생성되면 K-Miner는 실제 정적 분석 패스를 시작하여 시스템 호출의 제어 흐름을 분석한다.
- 다양한 유형의 취약성에 대한 개별 패스: dangling-pointer, use-after-free, doublefree 및 double-lock 오류
- 패스는 상황에 맞는 가치 흐름 분석으로 구현되며, 주어진 시스템 호출의 제어 흐름을 고려하여 절차 간 상황 정보를 추적하고 호출 그래프에서 내려간다.
- 잠재적인 메모리 손상 버그가 발견되면 KMiner는 모든 관련 정보 (영향을 받는 커널 버전, 구성 파일, 시스템 호출, 프로그램 경로 및 개체)가 포함 된 보고서를 생성한다.

- LLVM-IR은 K-Miner에 vmlinux 비트 코드 이미지로 전달되어 사전 분석을 시작하여 전역 커널 컨텍스트를 초기화하고 채운다.
- 이 컨텍스트 정보는 개별 시스템 호출을 분석하는 데 사용되는데, 여러 분석 패스 (예 : 매달린 포인터, 사용 후 사용 및 이중 무료 검사기)를 연속적으로 실행하거나 각각 독립적으로 실행할 수 있다.
- 다양한 유효성 검사 기술을 통해 버그 보고서를 삭제하여 오 탐지 수를 줄인다.
- 정렬 된 보고서는 취약성보고 엔진을 사용하여 렌더링된다.
<평가>
- 기본 구성 (defconfig)을 사용하여 5가지 버전의 Linux 커널에 대해 메모리 손상 검사기를 실행
- K-Miner는 29 개의 가능한 취약점을 발견하여 총 539 개의 경보를 생성했으며, 대부분은 오탐으로 분류 되었다
- 시스템 호출 당 평균 분석 시간은 약 25 분

<장단점>
- 장점
- 현재 Linux 커널은 2,400 만 줄 이상의 코드로 구성되어 있으며 수십 개의 서로 다른 아키텍처와 수백 개의 외부 하드웨어 용 드라이버를 지원하기 때문에, 대량의 프로그램 코드에 대한 데이터 구조와 의존성 그래프를 생성하면 궁극적으로 리소스 요구 사항이 폭발적으로 증가하게 된다. 따라서 코드를 생략하지 않고 중간 결과를 재사용 할 수 있도록 개별 분석 패스에 대한 코드 양을 줄이는 기술을 제공하며, 시스템 호출 인터페이스에 따라 커널을 분할함으로써 모든 코드를 고려하고 중요한 데이터 구조 (예 : 커널 컨텍스트)의 재사용을 허용하면서 분석 된 경로 수를 크게 줄이고 있다.
- false positive를 과도한 근사값으로 주게 되면, 개발자가 처리 할 수없는 많은 보고서가 생성되는데 KMiner는 오탐의 수를 최소화하고 있다. 오탐의 수는 개별 분석 패스의 구현에 따라 크게 달라지므로 가능한 한 많은 정보를 활용하여 런타임에 불가능한 사례가 필요한 보고서를 제거하거나 너무 대략적인 근사치를 만들도록 분석을 신중하게 설계합니다. 또한 협업 웹 기반 사용자 인터페이스에서 개발자에게 표시하기 전에 생성 된 보고서를 삭제, 중복 제거 및 필터링할 수 있다.
- 사용자 지정 및 확장 가능한 프레임 워크로 설계되었기 때문에 추가 검사기를 구현하는 것은 간단하다.
- 한계점
- 경우에 따라 커널은 LLVM에서 다루지 않을 수있는 비표준 코드 구조와 사용자 정의 컴파일러 확장을 사용하는데, 이 경우 패치가 필요하다.
- 컨텍스트 처리는 모든 후속 데이터 흐름 분석 단계의 첫 번째 단계를 나타내므로 시간이 많이 걸린다.
- 여전히 많은 수의 false positive가 표시 되고있다. 특히, 커널 코드에서 nullness 검사에 기반한 조건부 분기가 잠재적인 use-after-free로 보고되는 경우가 많다. (정적 분석 도구에는 항상 일정한 수의 false positive가 있기 때문에 개발자는 컴파일러 경고를 확인하는 방법과 유사하게 이러한 경고를 교차 확인해야한다)
- K-Miner의 경우, 모든 간접 callsite의 1 % 만 해결한다. 왜냐하면, K-Miner에서 사용하는 SVF는 코드 기반이 전체 커널보다 작은 각 파티션에서 실행되고 분석 범위가 상당히 제한되고 다른 파티션의 함수 포인터를 해결할 수 없어 해상도가 저하된다. 또한, PeX 논문에서 실험한 결과, defconfig보다 훨씬 더 큰 코드 기반을 포함하는 allyesconfig에서는 메모리 부족으로 인해 작동하지 않는다는 것을 발견했다.
PeX: A permission check analysis framework for Linux kernel
권한 검사는 권한있는 기능에 대한 액세스 제어를 제공하여 운영 체제 보안에 필수적인 역할을 하지만, 커널 개발자가 새로운 권한 검사를 올바르게 적용하고 큰 코드 기반과 커널의 복잡성으로 인해 기존 검사의 건전성을 확장 가능하게 확인하는 것은 특히 어렵다.
<특징>
- Linux용 정적 권한 검사 오류 탐지기로, 커널 코드를 입력으로 받아 누락되고 일관되지 않으며 중복 된 권한 검사를 건전하고 확장 가능하게 감지 할 수 있다.
- PeX는 새롭고 정확하며 확장 가능한 간접 호출 분석 기술인 KIRIN (커널 인터페이스 기반 간접 호출 분석)을 사용하여 커널 추상화 인터페이스에 사용되는 공통 프로그래밍 패러다임을 활용한다.
- KIRIN이 구축 한 절차 간 제어 흐름 그래프를 통해 PeX는 모든 권한 검사를 자동으로 식별하고 권한 검사와 권한있는 기능 간의 매핑을 추론한다.
<구조>

PeX는 LLVM 비트 코드 형식의 입력 커널 소스 코드를 공통 권한 검사로 취해 누락, 불일치 및 중복 권한 검사를 포함하여 감지 된 모든 권한 검사 오류를 분석하고 보고 한다. 그 결과 PeX는 공식적으로 문서화되지 않은 권한 검사 및 권한 있는 기능의 매핑을 생성한다.
- 콜 그래프 생성 및 분할
- 사용자 공간 접근 가능 함수 : 시스템 호출 진입 점을 나타내는 공통 접두어 SyS_가 있는 함수에서 시작하여 PeX는 호출 그래프를 탐색하고 방문한 모든 함수를 표시하고, 이를 사용자 공간 접근 가능 함수로 취급한다. 파티션에서 사용자가 접근 할 수있는 기능은 가능한 권한 검사 오류에 대해 조사된다.
- 커널 초기화 기능 : 부팅 중에 만 사용되는 기능을 수집하여 중복 검사를 감지합니다. Linux 커널은 start_kernel 함수에서 부팅하고 공통 접두사 __init를 사용하여 함수 목록을 호출합니다.
- PeX는 KIRIN의 결과를 활용하여 콜 그래프를 생성 한 다음, 이를 두 그룹으로 분할한다. 분할 된 호출 그래프는 권한 검사와 권한있는 기능간의 매핑 추론에 사용되는 ICFG (Interprocedural Control Flow Graph)를 구축하기위한 기반으로 사용된다.
- 권한 검사 래퍼 감지주어진 권한 검사 함수에 대해 PeX는 함수의 인수를 호출 수신자에게 전달하는 함수 내의 모든 호출 명령을 검색하고, 권한 검사만 사용하는 다른 호출자를 제외하고 권한 매개 변수를 래퍼로 전달하는 호출자만 참조한다.
- 권한 확인 오류를 정확하고 정확하게 감지하려면 전체 권한 확인 목록이 필요하다. PeX는 래퍼를 포함한 모든 권한 검사를 식별하는 프로세스를 자동화하여 래퍼 검사를 효율적으로 시행합니다. PeX는 사용자가 제공한 권한 검사의 불완전한 목록을 입력으로 받습니다. 여기서 시작해서 PeX는 호출 그래프에 대해 포워드 호출 그래프 슬라이싱을 수행하여 기본 권한 검사를 감지한다.
- Privileged Function Detection
- 권한 검사 오류를 효과적으로 감지하려면 권한 검사와 권한있는 기능 간의 매핑을 이해하는 것이 중요한데, PeX는 주어진 권한 검사에 의해 보호되는 권한 기능을 자동으로 식별 할 수있는 절차 간 지배자 분석을 활용한다. PeX는 ICFG 위에있는 각 권한 검사가 지배하는 호출 명령의 모든 호출자를 잠재적인 권한 기능으로 보수적으로 취급한다.
- Non-privileged Function Filter
- Privileged Function Detection에서의 보수적 접근 방식은 false positive를 유발할 수 있기 때문에, 4단계에서 PeX는 휴리스틱 기반 필터를 적용하여 잘못된 권한 함수를 제거한다.
- Permission Check Error Detection
- 마지막 단계에서는 잠재적 권한 검사 오류를 감지하기 위해 권한있는 함수의 사용을 확인하는 단계이다. 권한 검사와 권한있는 기능 간의 지정된 매핑에 대해 PeX는 해당 권한 검사를 염두에 두고 권한있는 기능에서 시작하여 ICFG의 역방향 순회를 수행한다. PeX는 관심있는 각 권한 기능에 대한 가능한 모든 경로의 유효성을 검사한다.
<평가> K-Miner 접근법과 비교

K-Miner는 분석을 위해 전체 커널 코드를 사용하는 대신 시스템 호출 단위로 커널을 분석하여 SVF의 확장성 문제를 해결했다. K-Miner는 주어진 시스템 호출에서 도달 할 수있는 커널 코드의 작은 크기의 파티션을 생성하고 해당 파티션에 SVF를 적용한다.

전반적으로 PeX는 DAC, CAP 및 LSM에 대해 각각 221, 850 및 1017 경고 (권한있는 기능별로 그룹화 됨)를 보고했다. PeX는 36 개의 버그 목록을 보고 했으며, 그중 14 개는 Linux 커널 개발자가 확인했다.
<장단점>
- 장점
- 많은 양의 분석을 빠른 시간 내에 할 수 있다.
- KIRIN의 효과를 강조하기 위해 유형 기반 (PeX + TYPE) 및 K-Miner 스타일 (PeX + KM) 간접 호출 분석을 사용하여 종단 간 PeX 분석을 반복한 결과, allyesconfig의 경우 PeX + TYPE 및 PeX + KM은 12 시간 실험 제한 내에 분석을 완료 할 수 없다. PeX + TYPE은 ICFG에서 너무 많은 (거짓) 모서리를 생성하고 PeX 분석의 마지막 단계에서 경로 폭발을 겪었다. 타임 아웃 전에 19 개의 버그만보고되었다. 그 동안 PeX + KM은 이전 포인터 분석 단계에서 시간이 초과되어 버그를보고하지 못했다.
- 많은 양의 분석을 빠른 시간 내에 할 수 있다.
- 한계점
- 도메인 지식이있는 커널 개발자는 복잡하지 않게 오류를 식별 할 수 있지만, 연구자들은 36 개의 버그 경고를 보수적으로 보고 하도록 했다. 대신 오픈 소스로 열어 두어 커널 개발자가 권한이있는 기능을 식별하고 더 많은 실제 권한 오류를 수정하는 데 기여하도록 했다.
- PeX에서 보고한 특정 정적 경로는 프로그램 실행 중에 동적으로 실행되지 않아 오탐지가 발생할 수 있다.
- 이 문제를 해결하기 위해 경로 제약을 해결하는 솔루션을 고안이 필요하다.
- 비실용적 인 수동 작업이 많다.
- Linux 커널에 대해 125,172 개의 버그 보고서를 생성했지만 팀이 보고서 중 838 개에 불과한 두 번의 버그 검토 마라톤을 실시한 후 17개만 확인 되었습니다.
KUBO(Kernel-Undefinned Behavior Oracle): Precise and Scalable Detection of User-triggerable Undefined Behavior Bugs in OS Kernel
Undefined Behavior bugs(정의되지 않은 동작 버그: UB)는 주로 비교적 낮은 수준의 프로그래밍 언어 (예 : C / C ++)로 구현 된 소프트웨어에 상주하는 광범위한 프로그래밍 오류를 나타내며, 트리거 된 UB는 종종 권한이없는 사용자 공간 프로그램의 악용으로 이어질 수 있으며 OS 내에서 중요한 보안 및 안정성 문제를 일으킬 수 있다. 커널에서 UB를 감지하는 이전 작업은 확장성을 위해 정밀도를 희생해야했고, 그 결과 사용성을 심각하게 손상시키는 극도로 높은 오탐지 문제를 겪었다.
<특징>
- KUBO는 높은 정밀도와 전체 커널 확장성을 동시에 달성하며 새로운 Linux 커널용 정적 UB 검출기
- 사용자 공간 입력에 의해 트리거 될 수있는 중요한 UB를 감지하는 데 중점을 두고 있다.
- 높은 정밀도는 UB 트리거 경로 및 조건의 만족도에 대한 KUBO의 검증에서 비롯되고, 전체 커널 확장성은 온 디맨드 방식으로 콜 체인을 따라 점진적으로 뒤로 이동하는 효율적인 절차 간 분석을 통해 가능하다.
- KUBO는 각 UB 명령에서 시작하여 잠재적인 사용자 공간 입력 사이트를 추적하는 주문형 증분 절차 간 분석을 수행한다. 증분 콜 체인 업 워크라고 하는 이 분석은 필요할 때 콜 체인에서 선택한 호출자 기능으로만 역 추적한다. 필요성은 BTI (Bug Triggerability Indicator)라고하는 경험적 UB 트리거 가능성 표시기에 의해 결정된다. BTI가 참으로 분석 된 후 KUBO는 종속 매개 변수를 스캔하고, 이를 오염시키는 발신자만 조사한다. 이러한 절차 간 분석 설계를 통해 KUBO는 이전 작업에서와 같이 탐지 세차를 희생하거나 절차 간 데이터를 무시하고 종속성을 제어하지 않고도 전체 커널 코드베이스를 확장하고 분석 할 수 있다.

<구조>

- 먼저 맨 처음에는 각 잠재적 UB 명령어 (UBSan에 의해 표시됨)에서 시작하여 코드 경로를 따라 다시 이동하고, UB가 사용자 공간 입력에 의해 트리거 될 수 있는지 확인한다. KUBO는 이 때, 순회 코드 경로 P와 관련된 두 가지 요구 사항을 기반으로 트리거 가능성을 결정한다. UB 조건에 관련된 변수는 사용자 공간 입력에 완전히 의존 한다. (또는 그에 의해서만 수정되어야함)
- 만약, P 및 UB 조건에 대한 경로 제약 조건이 만족될 경우, KUBO는 데이터를 정적으로 추적하고 각 UB 트리거링 변수의 종속성을 제어하여 R1을 확인한다. 현재 함수에서 R1을 결정할 수없는 경우 (ex. 그림에서 1, R1에서는 UB 조건 변수의 데이터 소스 또는 그 종속성을 아직 찾을 수 없음) KUBO는 절차 간 분석이 필요한지 BTI라는 경험적 지표를 통해 확인한다.
- BTI가 참이면(2) KUBO는 사용자 공간 입력에 의해 UB가 트리거 될 수 있다는 높은 신뢰도를 가지고, BTI는 KUBO가 분석해야하는 절차 간 경로의 수를 줄인다. BTI가 거짓(3)이면 KUBO는 증분 콜 체인 업 워크를 시작하고 선택한 호출자 함수에 대한 역방향 분석을 계속하여 R1이 유지되는지 확인한다 (즉, UB 조건부 변수가 사용자 공간 입력에서만 값을 가져옴).
- 증분 콜 체인 업 워크는 한 번에 하나의 호출자 함수를 선택하고 R1에 대한 또 다른 검사 라운드를 위해 함수의 데이터 흐름 요약을 입력 추적 구성 요소(4)로 보낸다. 이 프로세스는 R1이 확인 / 정의되거나 기능 홉 수가 제한에 도달하면 중지된다.
- R1이 확인 된 후 (2또는 5) 포스트 버그 분석의 일부로 KUBO는 SMT 솔버를 사용하여 경로 제약 조건 및 UB 조건이 만족 스러운지 확인하여 R2를 확인합니다. R2도 충족되면 KUBO는 나머지 버그 후 분석을 수행하여 UB가 의도하지 않은 결과를 초래할 수 있는지 여부를 최종적으로 확인하고, 그렇다면 버그 보고서(6)를 생성한다.
<평가>
- KUBO의 정확성과 완전성
- 수동으로 설정된 Ground Truth를 기반으로 두 가지 제어 된 실험을 통해 KUBO의 FNR (false negative rate) 및 FDR (false detection rate)을 측정
- UB로 확인 된 19 개의 CVE (S eval)가 포함 된 비교적 오래된 Linux 커널 (4.1)을 테스트했고 KUBO가 놓친 19 개 CVE 중 몇 개를 검사하여 위음성 비율을 도출
- KUBO는 테스트 된 커널에서 19 개 CVE 중 12 개를 올바르게 감지하여 36.8 %의 위음성 비율을 나타냈다.
- 오 탐지율을 측정하기 위해 최신 Linux 커널 (5.6.13)을 사용하고 KUBO에서 생성 한 모든 버그 보고서를 수동으로 검증
- 총 166 개의 커널 모듈과 잠재적 UB 버그를 확인했고, 그 결과로 KUBO는 40 개의 UB 버그 보고서를 생성했다. 각 보고서를 수작업으로 조사한 결과, 그 중 29 개가 실제 UB 버그 (11 개 허위 버그)였으며, 27.5 %의 오 탐지율을 확인했다.
- 이 비율은 오 탐지 비율이 91 % 인 대규모 코드베이스에서 작동 할 수있는 기존 UB 감지기보다 현저히 낮다.
- 전체 Linux 커널을 분석 할 때 KUBO의 성능 오버 헤드
- 처리 시간은 다양한 복잡성으로 인해 모듈마다 다르고 모든 작업이 스레드 풀에 배치되었지만 대부분의 모듈은 16 시간 (0.5h + 4m + 15h) (파란색 막대) 내에 완료 될 수 있다. 복잡한 모듈은 에 33시간 (2h + 6m + 30h) (빨간색 막대) 인 최악의 시나리오로 훨씬 더 오래 걸린다.
- 각 분석 단계에서 각 모듈을 하나씩 분석하는 대신 모든 작업이 스레드 풀에 배치되었으며 스레드 풀에 들어간 순간부터 완료 될 때까지 개별 모듈의 시간을 측정했다.
- 오염 분석의 경우 대부분의 하위 시스템에서 기능별 taint 요약을 생성하는 데 30 분이 걸리지 만 드라이버 / 넷 드라이버 / inFiniband 드라이버 / gpu 및 드라이버 / 넷은 약 2시간이 걸린다.
- 콜 그래프 분석에는 모든 모듈이 6 분 미만 소요된다.
- KUBO의 경우 분석 시작 후 15 시간 이내에 161 개의 하위 시스템이 완료된다. 주석이 달린 양이 많고 코드베이스가 복잡하기 때문에 5 개의 하위 시스템의 경우 15 시간이 더 걸린다.
- ex. 하위 시스템 fs, drivers : video, drivers : gpu, net 및 drivers : scsi 등
- ⇒ KUBO는 너무 많은 오버 헤드없이 고품질의 버그 보고서를 생성 할 수 있으며, 전체 분석은 합리적인 시간 인에 완료 될 수 있다.

<장단점>
- 장점
- KUBO는 사용자 공간 입력에 의해 트리거 될 수 있는 OS 커널에서 UB를 감지하는 데 중점을 두기 때문에, user space에서 가져온 데이터에 대한 UB의 종속성을 추적할 수 있다.
- 높은 오탐지로 어려움을 겪는 커널에서 UB를 감지하는 이전 작업과 달리 KUBO는 데이터를 추적하고 함수 호출에서 종속성을 제어하는 새로운 절차 간 분석을 제공한다.
- 사용자 제어 데이터를 중심으로하는 온 디맨드 증분 콜 체인 업 워크 분석을 통해 KUBO는 절차 간 데이터 흐름을 추적하여 전체 Linux 커널을 분석 할 수 있다.
- KUBO는 모든 KConfig 항목이 활성화되고 드라이버가 포함 된 전체 커널을 분석했다.
- 한계점
- KUBO는 현재 하드웨어 입력 소스를 처리하지 않으며 이로 인해 설문조사에서 누락 된 버그 중 5개가 발생했다.
- 하드웨어 인터페이스는 다양한 하드웨어 사양 (예 : DMA, MMIO)으로 인해, 들어오는 신뢰할 수없는 입력을 식별 할 때 일반적으로 사례별로 분석해야한다.
- 평가에서 알 수 있듯이 KUBO의 오탐 중 80%가 절차 내 제한으로 인해 불완전한 사후 버그 분석으로 인해 발생한다.
- KUBO는 현재 하드웨어 입력 소스를 처리하지 않으며 이로 인해 설문조사에서 누락 된 버그 중 5개가 발생했다.
결론

- KMiner - Linux 커널에서 메모리 손상 버그를 감지하기위한 정적 분석 도구로, 가치 흐름 분석을 기반으로하며 메모리에 대한 잠재적 인 잘못된 작업을 추론 할 수 있다. 특정 메모리 개체에서 사용 가능
- PEX - 전체 커널 호출 그래프를 생성하고 정적 호출 체인을 사용한다. 커널에서 권한 검사 오류를 감지하기위한 분석
- Unisan - API 오용을 찾는 것을 목표로 한다. 절차 내 분석은 높은 거짓 감지율, 특히 정수 감지에 사용되는 경우 API 매개 변수가 API로 유입되는 위치와 방식을 추적 할 수 없기 때문에 오버플로가 발생할 수 있다.
- KUBO - 확장 가능하고 효율적인 절차 간 분석을 사용하며 사용자 공간 입력에 의해 트리거 될 수있는 중요한 Undefined Behavior bugs를 감지하는 데 중점을 둔다.
'논문을 읽자' 카테고리의 다른 글
| An analysis of Facebook photo caching (0) | 2023.04.13 |
|---|---|
| AI4DL: Mining Behaviors of Deep Learning Workloads for Resource Management (0) | 2023.03.24 |
| Gpipe: Efficient training of giant neural networks using pipeline parallelism (0) | 2023.03.22 |
| Joint Task Scheduling and Containerizing for Efficient Edge Computing (0) | 2023.03.20 |
| An Empirical Study of Memory Sharing in Virtual Machines (0) | 2022.05.18 |