https://www.honeybadger.io/blog/memory-management-in-python/
Memory Management in Python
Understanding memory management is a superpower that will help you design memory-efficient applications and make it easier to debug memory issues. Join Rupesh Mishra for a deep dive into the internals of CPython.
www.honeybadger.io
이 글을 번역한 글입니다.
목차
1. Memory Management in Python (1) - Python 메모리 할당
2. Memory Management in Python (2) - Python 가비지 컬렉터
가비지 컬렉션은 프로그램에서 더 이상 필요하지 않을 때 할당된 메모리를 회수하거나 해제하는 프로세스이다.
가비지 컬렉션(GC)은 메모리를 자동으로 관리하는 방법 중 하나이다.
가비지 컬렉션은 프로그램에 의해 할당되었지만 더 이상 참조되지 않는 메모리(가비지)를 회수하려고 시도한다.
- Wikipedia
C 와 같은 언어에서는 프로그래머가 사용하지 않는 객체(사용되지 않는 객체의 가비지 컬렉션)에 대한 메모리를 수동으로 해제해야 하는 반면, Python 에서는 언어 자체가 자동으로 관리한다.
Python 은 자동 가비지 컬렉션에 두 가지 방법을 사용한다:
1. 참조 횟수를 기반으로 한 가비지 컬렉션
2. 세대별 가비지 컬렉션
먼저 참조 횟수가 무엇인지 설명하고, 참조 카운팅을 기반으로 한 가비지 컬렉션에 대해 자세히 알아보자!
Reference Count
이전 글에서 본 것처럼, CPython 은 내부적으로 각 객체에 대한 속성 유형과 참조 횟수를 생성한다.
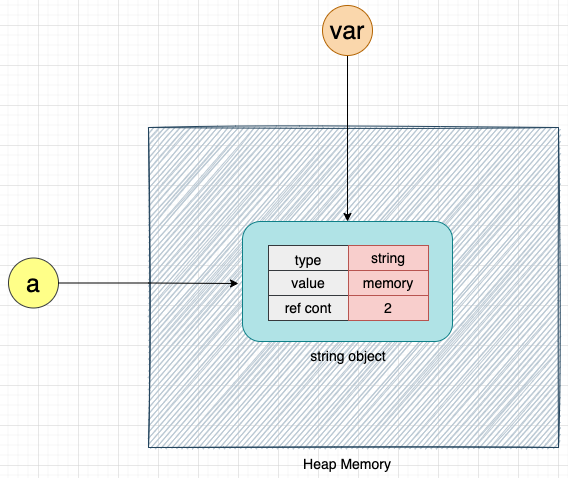
ref count 속성을 더 잘 이해하기 위한 예를 살펴보자

a = "memory"위 코드가 실행되면, CPython 은 문자열 유형의 객체 메모리를 생성한다.
필드 ref count 는 객체에 대한 참조 횟수를 나타낸다. 이전 글에서 우리는 Python 변수가 객체에 대한 참조일 뿐이라는 것을 알고 있다. 위 예에서 변수 a 는 문자열 객체 메모리에 대한 유일한 참조이다. 따라서 문자열 객체 메모리의 참조 카운트 값은 1이다.
getrefcount 메서드를 사용하면 Python 에서 모든 객체의 참조 횟수를 얻을 수 있다.
아래와 같이 문자열 객체 메모리의 참조 카운트를 구해보면:
import sys
ref_count = sys.getrefcount(a)
print(ref_count) # Output: 2결과값은 2가 나온다. 즉, 문자열 객체 메모리가 두개의 변수에 의해 참조되고 있음을 나타낸다.
앞에서 우리는 메모리 객체가 변수 a에 의해서만 참조된다는 것을 보았는데, getrefcount 메서드를 사용할 때의 문자열 객체 메모리의 참조 횟수가 2인 이유는 무엇일까?
이를 이해하기 위해서 먼저 getrefcount 메서드의 정의를 살펴보자:
def getrefcount(var):
...
변수 a를 getrefcount 메서드에 전달하면, 메서드의 매개 변수 var도 메모리 객체를 참조하게 되므로 메모리 객체의 참조 횟수는 2가 되는 것이다.
그래서 객체의 참조 횟수를 얻기 위해 getrefcount 메서드를 사용할 때마다, 참조 횟수는 항상 객체의 실제 참조 횟수보다 1이 더 많아진다.
이 상황에서 동일한 문자열 객체 메모리를 가리키는 또 다른 변수 b 를 생성해 보자:

import sys
ref_count = getrefcount(a)
print(ref_count) # Output: 3
변수 a 와 b 는 모두 문자열 객체 메모리를 가리킨다. 그 결과 문자열 객체 메모리의 참조 횟수는 2가 되고, 앞선 예시와 마찬가지로 getrefcount 메서드의 출력은 3이 된다.
Decreasing the Reference Count
위 상태에서 참조 횟수를 줄이려면 변수에 대한 참조를 제거해야 한다.
예를 들면 아래의 방법을 사용할 수 있다:
b = None이 경우 변수 b는 더 이상 문자열 객체 메모리를 가리키지 않기 때문에 문자열 객체 메모리의 참조 횟수가 줄어든다.
import sys
ref_count = getrefcount(a)
print(ref_count) # Output: 2
Decreasing the Reference Count Using the del Keyword
우리는 del 키워드를 사용하여 개체의 참조 횟수를 줄일 수도 있다.
변수 b 에 None을 할당하면 (b = None), b는 더 이상 문자열 객체 메모리를 가리키지 않게 된다.
del 키워드는 같은 방식으로 작동하며, 객체의 참조를 삭제하여 참조 횟수를 줄이는 데 사용된다. (단, del 키워드는 개체를 삭제하지는 않는다.)

del b다음 예시와 같이 del b 는 b 의 참조만 삭제하며, 문자열 객체 메모리를 삭제하는 것이 아니다.
이제 문자열 객체 메모리의 참조 카운트를 구해보면, b의 참조 횟수는 2가 된다.
import sys
ref_count = getrefcount(b)
print(ref_count) # Output: 2
참조 횟수에 대해 배운 내용을 요약해 보자!
동일한 객체를 새로운 변수에 할당하면, 객체의 참조 횟수가 증가한다. 만약 del 키워드를 사용하거나 객체가 None 을 가리키도록 하여 객체를 역참조하면 해당 객체의 참조 횟수가 감소한다.
Python 의 참조 횟수 개념에 대해 더 잘 이해했으니까, 이제 참조 횟수를 기반으로 가비지 컬렉션이 작동하는 방식에 대해 알아보자
Garbage Collection on the Basis of Reference Count
참조 횟수를 기반으로 하는 가비지 컬렉션은 객체의 참조 횟수를 사용하여 메모리를 회수한다.
객체의 참조 횟수가 0 일때, Python 의 가비지 컬렉션이 시작되어 메모리에서 객체를 제거한다.
그리고 객체가 메모리에서 삭제되면, 다른 객체들도 함께 삭제될 수 있다.
다음 예를 살펴보자:

import sys
x = "garbage"
b = [x, 20]
ref_count_x = getrefcount(x)
print(ref_count_x) # Output: 3
ref_count_b = getrefcount(b)
print(ref_count_b) # Output: 1위 예시에서 getrefcount 메소드로 인한 참조 횟수 증가를 무시하면 문자열 객체 "garbage" 의 참조 횟수는 2이고, 배열 객체의 참조 횟수는 1이다. (garbage: 변수 x 에서 참조되고, 리스트 b 에서도 참조됨)
이 때, 변수 x 를 삭제하면

del x
b[0] # Output: garbage문자열 객체 "garbage" 의 참조 횟수는 아래와 같이 배열 객체 [x, 20]로 인해 1이 된다.
우리는 변수 b 에 의해 문자열 객체 "garbage" 에 여전히 접근할 수 있다.
여기서 변수 b 를 삭제 해보자:
del b위 코드가 실행되면, 배열 객체의 참조 횟수는 0 이 되고, 가비지 컬렉션은 배열 객체를 삭제한다.
배열 객체 [x, 20] 를 삭제하면 배열 객체에서 문자열 객체 "garbage" 의 참조 x 도 삭제된다.
이렇게 하면 "garbage" 객체의 참조 횟수가 0이 되고, 결과적으로 "garbage" 개체도 수집된다.
따라서 객체의 가비지 컬렉션은 객체가 참조하는 다른 객체의 가비지 수집을 유발할 수도 있다.
참조 횟수에 따른 가비지 컬렉션은 실시간으로 이루어진다!
가비지 컬렉션은 객체의 참조 횟수가 0 이 되는 즉시 시작된다. 이는 Python 의 주요 가비지 컬렉션 알고리즘 방식이며 비활성화할 수 없다.
순환 참조가 있는 경우에는 참조 횟수를 기반으로 하는 가비지 컬렉션이 작동하지 않는다. 그래서 순환 참조가 있는 객체의 메모리를 해제하기 위해 Python 은 세대별 가비지 컬렉션 알고리즘을 사용한다.
다음으로 순환 참조에 대해 논의한 다음 세대별 가비지 컬렉션 알고리즘에 대해 더 깊이 이해해보자!
Cyclic References in Python
순환 참조는 객체가 자기 자신을 참조하거나 두개의 다른 객체가 서로를 참조하는 상태를 의미한다. 이러한 순환 참조는 리스트, 딕셔너리 및 사용자 정의 객체 등의 컨테이너 객체에서만 가능하다. 그리고 정수, 실수 또는 문자열과 같은 불변 데이터 타입에서는 불가능하다.
다음 예시를 살펴보자:
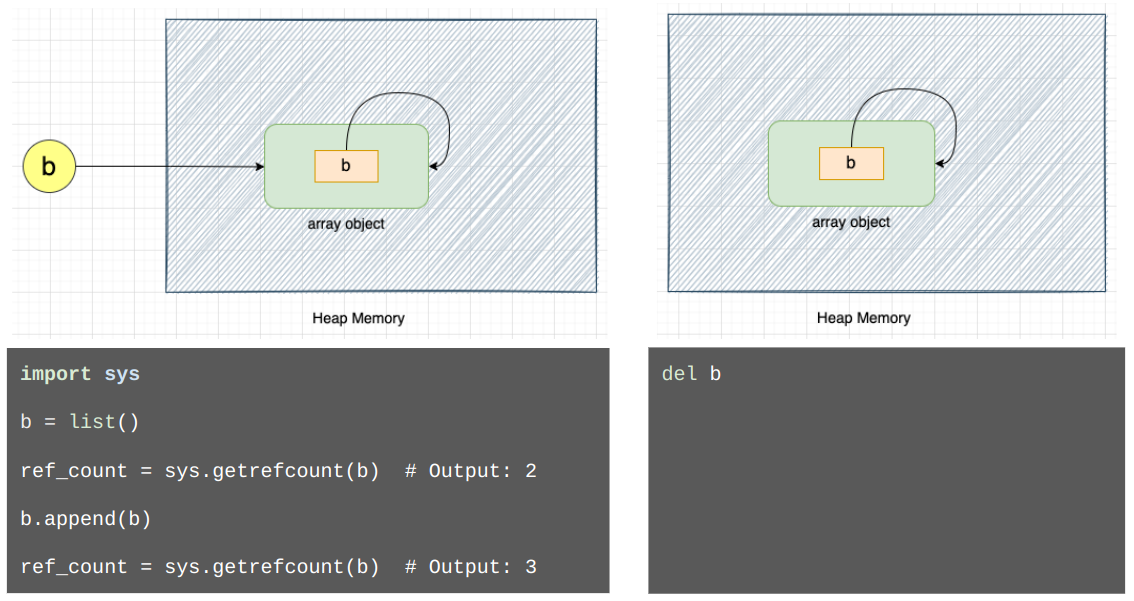
왼편에서 볼 수 있듯이 배열 객체 b 는 자신을 참조하고 있다.
오른쪽처럼 참조 b 를 삭제하면 Python 코드에서 배열 객체에는 접근할 수 없지만, 오른쪽 이미지와 같이 메모리에는 계속 존재하게 된다. 배열 객체가 자기 자신을 참조하므로 배열 객체의 참조 횟수는 영원히 0이 되지 않으며, 참조 횟수 기반 가비지 컬렉션에 의해서는 수집될 수 없다.
다른 예시를 살펴보면:

각각 ClassA 및 ClassB 클래스의 두 객체 object_a 및 object_b를 정의한다고 하자. object_a 는 변수 A 에서 참조하고 object_b 는 변수 B에서 참조 할 때, object_a 에는 object_b 를 가리키는 속성 ref_b 가 있다. 마찬가지로 객체 object_b 에는 object_a 를 가리키는 속성 ref_a 가 있다. 즉, object_a 와 object_b 는 각각 변수 A 와 B 를 이용하여 Python 코드에서 접근 할 수 있다.
만약 변수 A 와 B 를 삭제할 경우,
del A
del B
위 코드와 같이 변수 A 와 B 를 삭제하면, object_a 와 object_b 는 Python 에서 접근할 수 없지만 메모리에는 계속 남아있게 된다.
이렇게 객체는 서로 가리키고 있는 상태이므로(ref_a 및 ref_b 속성에 의해) 참조 횟수는 결코 0 이 될 수 없다. 따라서 이러한 객체는 참조 카운트 기반 가비지 컬렉터에 의해 수집되지 않는다. 따라서 이러한 경우 Python 은 세대별 가비지 컬렉션이라는 또 다른 가비지 컬렉션 알고리즘을 제공한다.
Generational Garbage Collection in Python
세대별 가비지 컬렉션 알고리즘은 순환 참조를 가지는 객체를 가비지 컬렉션하는 문제를 해결할 수 있다.
순환 참조는 컨테이너 객체에서만 가능하므로, 이 알고리즘은 모든 컨테이너 객체를 스캔하여 순환 참조를 가지는 객체를 검출한 다음, 가비지 컬렉션이 가능한 경우 제거한다.
스캔되는 객체 수를 줄이기 위해, 세대별 가비지 컬렉션은 불변 타입(예: int 및 문자열)만 포함하는 튜플을 무시한다.
객체를 탐색하고 순환 참조를 감지하는 것은 시간이 많이 걸리는 작업이므로 세대별 가비지 컬렉션 알고리즘은 실시간으로 작동하지 않으며 주기적으로 실행된다. 세대별 가비지 컬렉션 알고리즘이 실행되면 다른 모든 것이 중지된다. 따라서 세대별 가비지 컬렉션 알고리즘이 트리거되는 횟수를 줄이기 위해 CPython 은 컨테이너 객체를 여러 세대로 분류하고, 각 세대에 속할 수 있는 컨테이너 객체 수에 대한 임계값을 정의함으로써 지정된 세대의 객체 수가 정의된 임계값을 초과하면 세대별 가비지 컬렉션이 실행된다.
CPython 은 객체를 3세대(0, 1, 2세대) 로 분류한다. 새 객체가 생성되면 먼저 0 세대에 속하며, CPython 이 세대별 가비지 컬렉션 알고리즘을 실행할 때 이 객체가 수집되지 않으면 1 세대로 이동한다. CPython이 세대별 가비지 컬렉션을 다시 실행할 때 개체가 수집되지 않으면 2 세대로 이동한다. 이것은 마지막 세대이며 객체는 그대로 유지된다. 일반적으로 대부분의 객체는 1 세대에서 수집된다.
주어진 세대에 대해 세대별 가비지 컬렉션이 실행되면, 그동안 더 어린 세대들도 함께 가비지 컬렉션이 수행된다. 예를 들어 1 세대에 대해 가비지 컬렉션이 트리거되면, 0세대에 있는 객체들도 함께 수집된다. 모든 세 세대(0, 1, 2)가 가비지 컬렉션이 수행되는 상황을 풀 컬렉션(full collection) 이라고 한다. 풀 컬렉션은 대량의 객체를 스캔하고 순환 참조를 감지하는 것이 포함되므로 CPython 은 가능한 한 풀 컬렉션을 피하려고 한다.
Python 에서 제공하는 gc 모듈을 사용하면 세대별 가비지 컬렉션의 동작을 변경할 수 있다. 세대별 가비지 컬렉션은 gc 모듈을 사용하여 비활성화할 수 있다. 이를 선택적 가비지 컬렉션이라고 한다.
다음으로 gc 모듈의 중요한 메소드에 대해 알아보자.
gc Module in Python
1. 각 세대에 대한 임계값 얻기:
import gc
gc.get_threshold()
# Output: (700, 10, 10)위의 출력값은 0 세대의 임계값이 700, 2 세대 및 3 세대의 임계값이 10임을 나타낸다.
0 세대에 700개 이상의 개체가 있는 경우 0 세대의 모든 개체에 대해 세대별 가비지 컬렉션이 트리거된다.
그리고 1 세대에 10개 이상의 개체가 있는 경우 1 세대와 0 세대 모두에 대해 세대별 가비지 컬렉션이 트리거된다.
2. 각 세대에 속한 객체의 수를 확인하기:
import gc
gc.get_count()
# Output: (679, 8, 0) # Note: Output will be different on different machines여기서 0 세대는 679개, 1 세대는 8개, 2 세대는 0개이다.
3. 세대별 가비지 컬렉션 알고리즘을 수동으로 실행하기:
import gc
gc.collect()gc.collect() 는 세대별 가비지 컬렉션을 트리거하며, 초기 설정 상 풀 컬렉션(full collection)을 실행한다.
만약 특정한 세대에 대한 세대별 가비지 수집을 실행하려면 아래와 같이 파라미터를 설정한다.
import gc
gc.collect(generation=1)
가비지 컬렉션 과정이 끝난 후에도 남아 있는 객체의 수를 확인해보면 아래와 같이 나타날 수 있다.
import gc
gc.get_count()
# Output: (4, 0, 0) # Note: Output will be different on different machines
4. 각 세대의 세대 임계값을 업데이트하기:
import gc
gc.get_threshold()
gc.set_threshold(800, 12, 12)
gc.get_threshold()
# Output: (800, 12, 12) # Note: Output will be different on different machines
5. 세대별 가비지 컬렉션을 비활성화/활성화 하기
gc.disable() # disable generational garbage collection
gc.enable() # enable it again
Conclusion
이 글에서는 Python 이 규칙과 스펙들의 집합이며, CPython 은 C 로 구현된 Python 의 참조 구현체임을 배웠다.
또한 Python 이 메모리를 효율적으로 관리하기 위해 사용하는 여러 메모리 할당자, 예를 들어 Object Allocator, Object-specific Allocator, Raw memory allocator, General purpose Allocator 등을 배웠다. 그리고 Python 메모리 관리자가 소규모 객체(512 byte 이하)에 대한 메모리 할당/해제를 최적화하는 데 사용하는 Arena, Pool, Block 에 대해 배웠다. 마지막으로 참조 횟수 및 세대 기반의 가비지 컬렉션 알고리즘에 대해서도 배웠다.
'CS > Etc' 카테고리의 다른 글
| RL 스터디 개념 정리(2) 3-5강 Model-Based vs Model-free (0) | 2024.01.18 |
|---|---|
| RL 스터디 개념 정리(1) 1~2강 RL 용어 정리 및 MDP (0) | 2024.01.18 |
| Strace to monitor Dockerized Application: trial and error (0) | 2023.04.26 |
| Memory Management in Python (1) - Python 메모리 할당 (0) | 2023.01.12 |