Strace
리눅스에서는 시스템 콜 이벤트를 추적하고 기록하기 위해 strace 라는 툴을 제공한다.
strace [-ACdffhikqqrtttTvVwxxyyzZ] [-I n] [-b execve] [-e expr]... [-O overhead] [-S sortby] [-U columns] [-a column] [-o file] [-s strsize] [-X format] [-P path]... [-p pid]... [--seccomp-bpf] [--secontext[=format]] { -p pid | [-DDD] [-E var[=val]]... [-u username] command [args] }
strace -c [-dfwzZ] [-I n] [-b execve] [-e expr]... [-O overhead] [-S sortby] [-U columns] [-P path]... [-p pid]... [--seccomp-bpf] { -p pid | [-DDD] [-E var[=val]]... [-u username] command [args] }
strace는 지정된 명령어가 종료될 때까지 실행되며,
프로세스가 호출하는 system call 과 프로세스가 수신하는 signal을 가로채서 기록한다.
- 트레이스의 각 줄에는 시스템 호출 이름(함수명)과 괄호 안의 argument 및 시스템 콜 실행 후의 반환값이 포함된다
open("/dev/null", O_RDONLY) = 3- 오류가 발생하는 경우(일반적으로 반환값 -1)에는 errno symbol과 오류문자열이 기록된다
open("/foo/bar", O_RDONLY) = -1 ENOENT (No such file or directory)- signal은 signal symbol 과 디코딩 된 siginfo 구조로 기록된다
sigsuspend([] <unfinished ...>
--- SIGINT {si_signo=SIGINT, si_code=SI_USER, si_pid=...} ---
+++ killed by SIGINT +++- 만약 시스템 호출이 실행되는 동안 다른 스레드/프로세스에서 다른 호출이 실행되는 경우 이벤트 순서는 유지하되, 진행 중인 시스템 호출을 완료되지 않은 것으로 표시하고 호출이 반환되면 재개된 것으로 표시한다.
[pid 28772] select(4, [3], NULL, NULL, NULL <unfinished ...>
[pid 28779] clock_gettime(CLOCK_REALTIME, {tv_sec=1130322148, tv_nsec=3977000}) = 0
[pid 28772] <... select resumed> ) = 1 (in [3])- 단, signal 전달에 의한 restartable 시스템 호출의 중단은 다르게 처리된다
- 이 경우에는 커널이 시스템 호출을 종료하고, signal handler가 완료된 후 즉시 재실행되도록 준비된다
read(0, 0x7ffff72cf5cf, 1) = ? ERESTARTSYS (To be restarted)
--- SIGALRM {si_signo=SIGALRM, si_code=SI_KERNEL} ---
rt_sigreturn({mask=[]}) = 0
read(0, "", 1) = 0- 알 수 없는 시스템 호출은 raw 상태로 기록되며, 알 수 없는 시스템 호출 번호는 16진수 형식으로 출력되며 앞에 syscall_ 접두사가 붙는다.
syscall_0xbad(0x1, 0x2, 0x3, 0x4, 0x5, 0x6) = -1 ENOSYS (Function not implemented)
options
-ttt: 절대 시간 기록, 마이크로 초 단위
-T: 시스템 호출에 소요된 시간, 각 시스템 호출의 시작과 끝 사이의 시간차를 기록, 디폴트는 마이크로 초 단위
-f: fork, vfork, clone 등의 시스템 콜의 결과로 현재 트레이싱 중인 프로세스에 의해 생성되는 자식 프로세스를 트레이싱한다. (만약 프로세스가 멀티스레드인 경우, 모든 스레드를 트레이싱)
-Z: 오류코드와 함께 반환된 시스템 콜만 기록
-z: 오류코드 없이 반환된 시스템 콜만 기록
-o: 트레이스 출력을 지정된 파일에 쓴다. 인수가 | 또는 !로 시작하면 나머지 인수는 커맨드로 취급되어, 모든 기록이 파이프로 전달된다. 이 옵션은 실행중인 프로그램의 리디렉션에 영향을 주지 않고, 디버깅 출력을 프로그램으로 파이프할 때 편하다.
Strace는 왜 컨테이너와 일반 프로세스에서 다르게 동작할까?
A containerized process uses system calls and needs permissions and privileges in just the same way that a regular process does. But containers give us some new ways to control how these permissions are assigned at runtime or during the container image build process, which will have a significant impact on security.
커널관점에서는 컨테이너 내에서 실행되는 프로세스 vs 호스트에서 실행되는 프로세스가 크게 다르지 않다.
결국 둘 다 단순히 생각하면 프로세스이고, 커널 영역을 공유한다. 따라서 syscall, kprobe, tracepoint 등의 커널 관련 이벤트로 프로세스를 트레이싱 하는 것은 동일 할 것이다.
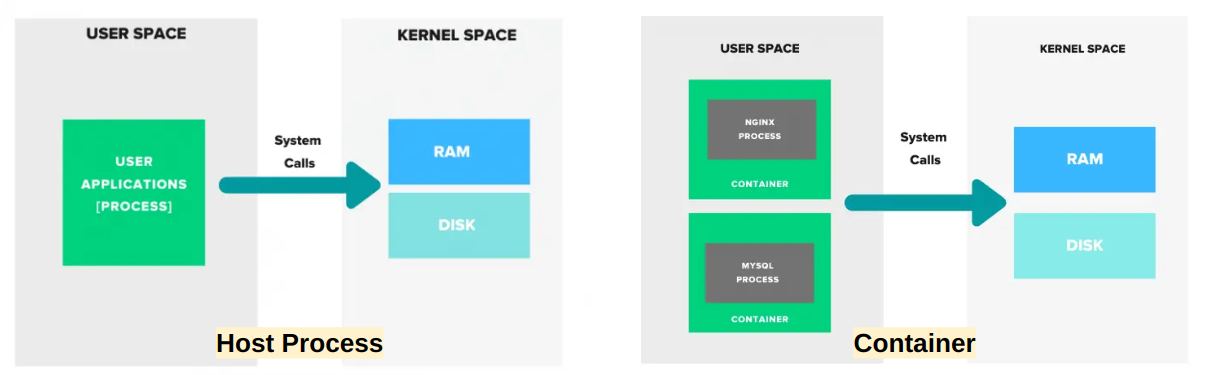
따라서 strace로 컨테이너를 분석 할 때, 일반적으로 프로세스를 분석하는 것과 똑같이 하면 될 줄 알았다.
-rw-rw-r-- 1 soyeon soyeon 1.8M 4월 27 16:13 squeezenet_docker.txt # 22091 lines
-rw-rw-r-- 1 soyeon soyeon 19G 4월 27 10:51 squeezenet_real.txt # 223172114 lines그런데 트레이스 사이즈가 너무 다르다;;
컨테이너와 호스트에서 실행되는 프로세스는 거의 비슷하지만,
사실은 컨테이너 워크로드에 자체 네임스페이스가 있어서 프로세스를 격리하게 된다.
즉, 컨테이너는 자체 루트 파일 시스템이 있고, binary/library는 서로 다른 mount namespace에 의해 격리된다
= 이벤트 추적 도구로부터 격리된다
그래서 트레이싱 툴이 작동할수도, 작동하지 않을수도 있다.
예를 들어 syncsnoop.bt는 잘 동작한다.
syncsnoop.bt
Attaching 7 probes...
Tracing sync syscalls... Hit Ctrl-C to end.
TIME PID COMM EVENT
10:27:04 1229 auditd tracepoint:syscalls:sys_enter_fsync
10:27:04 1229 auditd tracepoint:syscalls:sys_enter_fsync
10:27:05 11459 fluent-bit tracepoint:syscalls:sys_enter_fsync
10:27:05 11459 fluent-bit tracepoint:syscalls:sys_enter_fsync
10:27:05 11459 fluent-bit tracepoint:syscalls:sys_enter_fsync
10:27:05 11459 fluent-bit tracepoint:syscalls:sys_enter_fsync
10:27:05 11459 fluent-bit tracepoint:syscalls:sys_enter_fsync
.....
##################
cat /proc/1229/status | grep nspid -i
NSpid: 1229
cat /proc/11459/status | grep nspid -i
NSpid: 11459 1 # 기본 PID 네임스페이스: 11459, 자체 네임스페이스: 1
그런데 bpftrace 같은 경우에는 컨테이너 내부 바이너리 또는 .so 파일에 접근하여 uprobe를 주입할 수 없으므로 컨테이너 내부 애플리케이션은 제대로 된 트레이싱이 불가능하다.
- uprobe: 프로세스가 probe를 만났을 때 수행할 작업을 커널에 알려준다. probe는 파일과 연결되어 있으므로 해당 파일에서 코드를 실행하는 모든 프로세스에 영향을 미친다.
// uprobe의 핵심 기능
#include <linux/uprobes.h>
int uprobe_register(struct inode *inode, loff_t offset, struct uprobe_consumer *uc);
//////////////////////////
struct uprobe_consumer {
int (*handler) (struct uprobe_consumer *self, struct pt_regs *regs);
bool (*filter) (struct uprobe_consumer *self, struct task_struct *task);
struct uprobe_consumer *next;
};
strace도 비슷하다. 거기다가 도커는 seccomp-bpf을 사용하여 컨테이너 프로세스가 특정한 시스템 콜을 실행하지 못하도록 막는다.
(기본 seccomp profile에서 허용되는 호출을 지정하는 허용 목록 작성)https://docs.docker.com/engine/security/seccomp/
Seccomp security profiles for Docker
docs.docker.com
그래서 만약 seccomp profile 옵션을 사용하지 않고 도커를 실행하고 싶다면 --security-opt seccomp=unconfined 을 도커를 실행할 때 추가해야한다.
근데 이렇게 하더라도 큰 변화는 없어서 더 찾아보니,,,
결론적으로 strace는 docker container의 동작을 빠짐없이 추적하기에는 적합하지 않은 도구였다.
strace는 프로그램이 실행하는 동안 호스트 운영 체제에 액세스하는 데 사용되는 시스템 콜을 추적할 수 있지만,
컨테이너가 호스트 운영 체제와 상호 작용하기 위해 사용하는 API 호출은 추적할 수 없다는 걸 알았다...
예를 들어,
- 컨테이너가 파일 시스템에 액세스하려면 open() 시스템 콜을 호출 -> strace 시스템 콜 추적 O
- 컨테이너가 Docker 네트워크를 통해 네트워크에 액세스할 때 docker_network_connect() API 호출 -> strace 시스템 콜 추적 X
strace는 API 호출을 추적할 수는 없다. (이러한 API 호출이 컨테이너의 네트워크 및 파일 시스템 드라이버에서 처리되기 때문)
네트워크 및 파일 시스템 드라이버는 컨테이너가 호스트 운영 체제와 상호 작용할 수 있도록 하는 소프트웨어인데,
strace는 드라이버가 호스트 운영 체제에 액세스하는 데 사용하는 시스템 콜을 추적할 수 있지만 드라이버 자체가 호스트 운영 체제에 액세스하는 방법은 추적할 수 없다.
'CS > Etc' 카테고리의 다른 글
| RL 스터디 개념 정리(2) 3-5강 Model-Based vs Model-free (0) | 2024.01.18 |
|---|---|
| RL 스터디 개념 정리(1) 1~2강 RL 용어 정리 및 MDP (0) | 2024.01.18 |
| Memory Management in Python (2) - Python 가비지 컬렉터 (2) | 2023.01.13 |
| Memory Management in Python (1) - Python 메모리 할당 (0) | 2023.01.12 |