💡 요약
- abstract: Hadoop, MPI 등 여러 다양한 클러스터 컴퓨팅 프레임워크 간에 리소스를 공유할 수 있는 플랫폼에 관한 연구
- introduction: 모든 애플리케이션에 최적화된 단일 프레임워크는 없기 때문에, 단일 클러스터에서 여러 프레임워크를 실행하여 활용도를 극대화하고 프레임워크 간에 데이터를 공유하고자 하는데 효율적으로 공유하기 어렵다는 문제점이 있다.
- related works:
* HPC 스케줄러(예: 토크, LSF, 썬 그리드 엔진): 비탄력적인 작업(예: mpi)을 위한 세분화된 공유
* 가상 머신 클라우드: HPC와 유사한 coarse-grained 공유
* 콘도르: 매치메이킹에 기반한 중앙 집중식 스케줄러
* 병렬 작업: 차세대 하둡
* 애플리케이션별 마스터를 갖도록 하둡 재설계
* 또한 맵리듀스가 아닌 작업도 지원하는 것을 목표
* 리소스 요청 언어와 지역 환경설정에 기반한 비매핑 작업 지원 목표
- method: Mesos는 각 프레임워크에 제공할 리소스 수를 결정하고, 프레임워크는 어떤 리소스를 수락할지, 어떤 계산을 실행할지 결정한다. zookeeper를 사용하여 master 장애를 조치할 수 있으며, hadoop/mpi/torque에 연결할 수 있다.
- experiment: 다양한 프레임워크 간에 클러스터를 공유할 때 거의 최적의 데이터 로컬리티를 달성할 수 있고, 50,000개(에뮬레이트된) 노드로 확장할 수 있으며, 장애에 대한 복원력이 뛰어난 것으로 나타남
- conclusion & discussion: Mesos는 세분화된 방식으로 리소스를 공유하므로 프레임워크가 각 머신에 저장된 데이터를 번갈아 읽음으로써 데이터 로컬리티를 달성할 수 있다
Introduction
클러스터 컴퓨팅 프레임워크는 상용 서버 클러스터에서 프로그래밍을 간소화하고 데이터 집약적인 과학 애플리케이션을 실행하는 데 사용 된다. 모든 애플리케이션에 대해 최적화된 프레임워크는 없기 때문에, 사람들은 동일 클러스터 내에서 여러 프레임워크를 실행하고 그들간에 데이터가 공유되길 원한다.
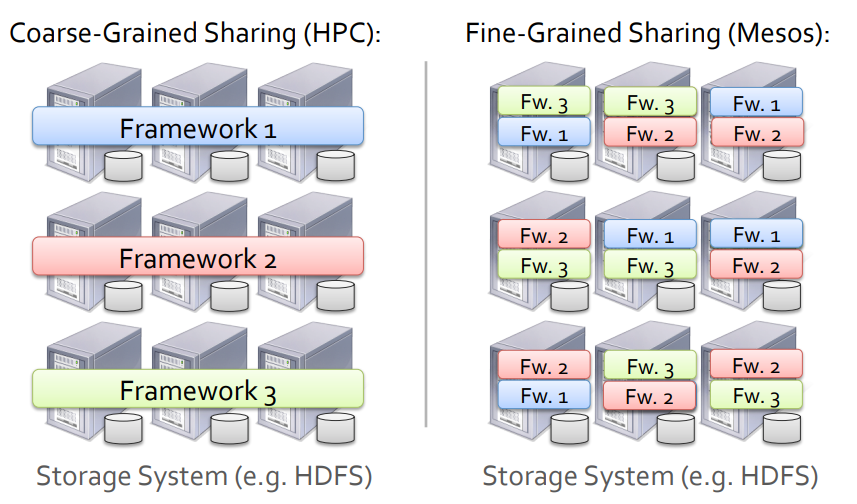
클러스터를 공유하는 두 가지 일반적인 방법:
- 클러스터를 정적으로 분할 후, 파티션 당 하나의 프레임워크 실행
- 각 프레임워크에 VM 할당
그러나 이러한 방법들은 프레임워크 간에 세분화된 공유를 수행할 수 있는 방법이 없기 때문에 프레임워크 간에 클러스터와 데이터를 효율적으로 공유하기가 어렵다.
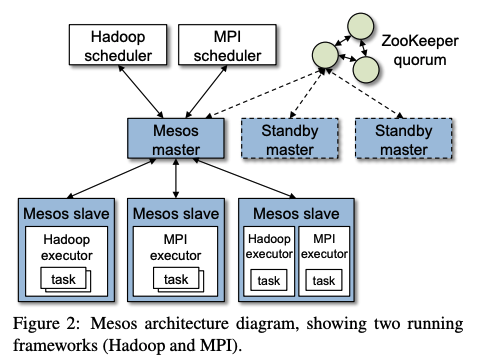
따라서 본 논문에서는 프레임워크에 클러스터 리소스 접근을 위한 공통 인터페이스를 제공하여 다양한 클러스터 컴퓨팅 프레임워크 간 세분화 된 공유를 가능하게 하는 fine-grained 리소스 공유 계층 Mesos를 제안한다. 즉, Mesos는 여러 클러스터 컴퓨팅 프레임워크 간에 세분화된 공유를 제공하여 MPI 및 MapReduce Online과 같은 다양한 프레임워크를 사용할 수 있도록 하는 것을 목표로 한다.
Mesos는 프레임워크 요구 사항, 리소스 가용성, 조직 정책을 입력으로 받아 모든 작업에 대한 글로벌 스케줄을 계산하는 중앙 집중식 스케줄러를 구현하는 대신, resource offer 이라는 추상화를 통해 스케줄링에 대한 제어를 프레임워크에 위임한다.
- resource offer: 프레임워크가 작업을 실행하기 위해 클러스터 노드에 할당할 수 있는 리소스를 캡슐화
Related Work
- Hpc schedulers(torque, lsf, sun grid engine): 특수 하드웨어로 클러스터를 관리하며, 여기서 작업은 모놀리식이며 수명 기간 동안 리소스 요구 사항이 변경되지 않는다. 중앙 집중식 스케줄링을 사용하며 사용자가 작업 제출 시 필요한 리소스를 선언해야 하므로 클러스터가 세분화되어 할당된다.
- Mesos는 작업 및 프레임워크 수준에서 세분화된 공유를 통해 배치를 제어할 수 있으므로 작업이 클러스터 전체에 분산된 데이터에 액세스하고 동적으로 확장 및 축소할 수 있다.
- 가상 머신 클라우드(Amazon EC2, Eucalyptus): 애플리케이션을 격리하고 낮은 수준의 추상화를 제공하는 것을 목표로 하지만, 가상 머신 클라우드는 상대적으로 세분화된 할당 모델을 사용하므로 리소스 활용과 데이터 공유의 효율성이 떨어진다. 또한, VM의 크기를 초과하여 작업 배치를 지정할 수 없다.
- Mesos는 프레임워크별로 매우 선택적인 작업 배치를 허용
- Quincy: DAG 기반 프로그래밍을 위해 중앙 집중식 스케줄링 알고리즘을 사용하는 Dryad용 스케줄러
- Mesos는 여러 클러스터 컴퓨팅 프레임워크를 지원하기 위해 리소스 오퍼의 저수준 추상화를 제공
- Condor: 리소스 사양 언어를 사용하여 노드와 작업을 매칭하는 클러스터 관리자, 단 프레임워크에 유연하진 않다.
Method
Mesos는 다양한 프레임워크가 클러스터를 효율적으로 공유할 수 있도록 확장 가능하고 복원력 있는 코어를 제공하는 것을 목표로 하기 때문에, 프레임워크 간에 리소스를 효율적으로 공유할 수 있는 최소한의 인터페이스를 정의하고, 그렇지 않은 경우 작업 스케줄링 및 실행 제어를 프레임워크에 위임한다.
- slave: 각 클러스터 노드에서 실행됨 = launches and isolates executors
- framework: salve에서 작업 실행
- scheduler: 마스터에 등록하여 리소스를 제공받음, 제공된 리소스 중 어떤 리소스를 사용할지 선택 = framework-specific scheduling
- job: 프레임워크의 작업을 실행하기 위해 슬레이브 노드에서 실행되는 실행자 프로세스
- 제약 조건을 충족하지 않는 리소스를 거부하고 제약 조건을 충족하는 리소스를 기다릴 수 있다 (필터링 기능)
- master: slave 데몬 관리 = pick framework to offer resources to
- resource offer(slave에 있는 free 리소스)를 사용하여 프레임워크 간 세분화 된 공유 구현
- 각 프레임워크에 제공할 리소스 수를 결정

- master가 slave로부터 사용 가능한 리소스에 대한 리포트를 수신
- master가 할당 모듈을 호출하여 특정 프레임워크에 사용 가능한 모든 리소스 제공 (resource offer를 프레임워크로 전달)
- 프레임워크 스케줄러가 slave에서 실행 할 작업에 대한 정보로 응답
- master가 프레임워크의 실행자에게 할당하기 위해 작업을 slave로 전송
Mesos의 리소스 할당 모듈은 공정한 공유를 수행하거나, 리소스 할당에 대한 엄격한 우선 순위를 구현할 수 있다.
일반적으로 대부분의 작업이 짧다는 가정 하에 리소스가 작업이 완료 후 재할당 되는데, 만약 클러스터가 긴 작업으로 가득 차면 할당 모듈이 어느 작업이든 kill 할 수도 있다. (단, Mesos는 작업을 종료하기 전에 프레임워크에 유예 기간을 제공)
이러한 경우에는 상호 의존적인 작업이 종료되는 것을 방지하기 위해, 할당 모듈은 프레임워크가 작업 손실 없이 보유할 수 있는 리소스의 양을 지정하고, 프레임워크는 API 호출을 통해 보장된 할당을 읽을 수 있다.
Mesos의 리소스 격리 정책에 대해 살펴보자면, 동일한 서버에서 실행되는 서로 다른 프레임워크의 서로 다른 작업을 서로 격리하여 간섭을 방지할 수 있다. 이러한 메커니즘은 플랫폼에 따라 다르므로 플러그형 격리 모듈을 통해 운영체제 격리 매커니즘을 지원한다.
특히 Mesos는 현재 Linux 컨테이너 및 Solaris 프로젝트와 같은 OS 컨테이너 기술을 사용하여 프로세스 트리의 CPU, 메모리, 네트워크 대역폭 및 I/O 사용량을 제한할 수 있다.
=> 격리 없이 컨테이너(프로세스)를 사용하는 Hadoop보다 개선됨
Mesos는 내결함성(fault tolerant)을 제공하기 위해 모든 프레임워크가 의존하는 master를 내결함성으로 만드는 것이 중요하다. 즉, 마스터에 장애가 발생하더라도 새로운 마스터가 슬레이브와 프레임워크 스케줄러가 보유한 정보로부터 마스터의 상태를 재구성할 수 있도록 할 수 있어야 한다.
- master의 상태: 활성 슬레이브, 활성 프레임워크, 실행 중인 작업 목록 등으로 정의
또한, 분산 시스템에서 리더 또는 코디네이터 역할을 할 단일 노드를 선택하기 위해 ZooKeeper가 사용된다.(여러 master가 hot-stanby 구성으로 실행되고, 그 중 하나가 언제든지 활성 마스터로 선출)
- hot-standby: 시스템의 여러 인스턴스가 동시에 실행되지만 주어진 시간에 하나의 인스턴스만 활성화된다. 다른 인스턴스는 대기 상태에 있으며 활성 인스턴스에 장애가 발생하거나 사용할 수 없게 되면 이를 대신한다. => master 중 하나에 장애가 발생하거나 유지보수를 위해 다운되더라도 Mesos 클러스터에서 리소스를 관리하고 작업을 예약할 수 있는 활성 마스터가 항상 존재

- callbacks: 프레임워크가 구현해야 하는 함수
- actions: 프레임워크가 호출 할 수 있는 작업
프레임워크의 워크로드는 탄력성 & 작업 시간 분포 두 가지로 특징지어질 수 있다.
- Hadoop 및 Dryad: 탄력적인 프레임워크, 필요에 따라 리소스를 확장 및 축소 가능 = 탄력적 프레임워크
- MPI: 고정된 양의 리소스가 필요하며 동적으로 확장할 수 없다 = 경직적(rigid) 프레임워크
- 작업 시간: 동종분포 vs 이질분포 / 상수형 vs 지수형
리소스는 두 가지 유형으로 구분되는데, 프레임워크에서 요청하는 필수 리소스의 양은 보장된 점유율을 초과하지 않는 것으로 가정한다. => 프레임워크가 필수 리소스가 확보되기를 기다리면서 데드락에 걸리지 않게 된다.
- 필수 리소스: 프레임워크가 실행하기 위해 반드시 확보해야 하는 리소스
- 선호 리소스: 프레임워크가 해당 리소스를 사용하여 "더 나은" 성능을 발휘하지만 다른 동등한 리소스를 사용하여 실행할 수도 있는 경우
또한 모든 작업은 동일한 리소스 요구량을 가지고, "슬롯"이라고 하는 동일한 머신 슬라이스에서 실행되며, 각 프레임워크는 단일 작업을 실행한다고 가정한다.
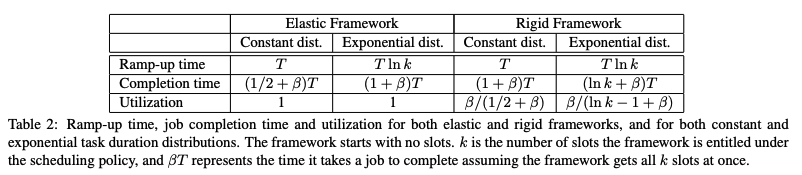
위 환경에 Mesos를 적용한 경우, 작업 지속 시간이 일정한 탄력적 프레임워크의 성능이 가장 우수하고, 작업 지속 시간이 기하급수적으로 증가하는 rigid 프레임워크의 성능이 가장 나쁘다.
- framework ramp-up time: 프레임워크가 선호하는 슬롯을 모두 확보하는 데 걸리는 시간
- 작업 지속 시간이 일정하면 모든 슬롯이 T 간격 동안 사용 가능해지므로 프레임워크가 k 슬롯을 획득하는 데 최대 T 시간이 걸리지만 작업 지속 시간이 기하급수적으로 증가하면 예상되는 램프업 시간은 T ln k만큼 길어질 수 있다
- 작업 완료 시간: 작업 기간 분포가 다른 여러 프레임워크의 작업에 대한 예상 완료 시간
- 탄력적 작업의 예상 완료 시간은 최대 (1 + β)T이며, 이는 모든 슬롯이 한 번에 완료될 때 작업 완료 시간의 T 이내이다.
- 리지드 작업은 일정한 작업 기간의 경우 비슷한 완료 시간을 달성
- 작업 지속 시간이 기하급수적으로 길어질 때는 훨씬 더 긴 완료 시간, 즉 (ln k + β)T
- 시스템 활용률: 사용되는 프레임워크 유형에 따라 시스템 활용률이 달라진다.
- 탄력적 작업은 할당된 슬롯을 받는 즉시 모든 슬롯을 완전히 사용하므로 해당 작업에 대한 수요가 무한대인 경우 전체 활용도가 높아진다
- 리지드 프레임워크는 전체 할당을 받을 때까지 작업을 시작할 수 없기 때문에 활용도가 약간 떨어지며, 램프업 시간 동안 리소스가 낭비된다
만약 프레임워크마다 선호하는 노드가 다르며, 시간이 지남에 따라 선호도가 변경된다고 한다면 어떻게 될까?
- 일부 프레임워크가 선호하는 슬롯을 모두 할당받을 수 없는 경우 = 가중치 공정 할당 정책을 사용할 수 있으며, 추첨 스케줄링이 이러한 할당을 달성하는 데 도움이 될 수 있다. 즉, 스케줄러는 각 프레임워크의 선호도를 알 수 없지만 추첨 스케줄링은 의도한 할당에 비례하는 확률로 프레임워크에 슬롯을 제공할 수 있다.
작업 기간이 짧은 프레임워크가 일부 작업이 다른 작업보다 훨씬 긴 이질적인(혼합된) 작업 기간 분포의 영향을 받게 되는데 어떻게 해야할까?
- 태스크에 리소스를 무작위로 할당하는 것이 잘 작동할 수 있다
- 또한 최대 작업 기간을 해당 리소스에 연결하여 짧은 작업을 위해 각 노드에서 리소스를 예약하는 할당 정책을 허용하는 Mesos의 확장도 제안 = HPC 클러스터에서 짧은 작업을 위한 별도의 대기열을 두는 것과 유사 = 컴퓨팅 리소스를 할당할 때 짧은 작업이 긴 작업보다 우선순위를 갖도록
Experiment
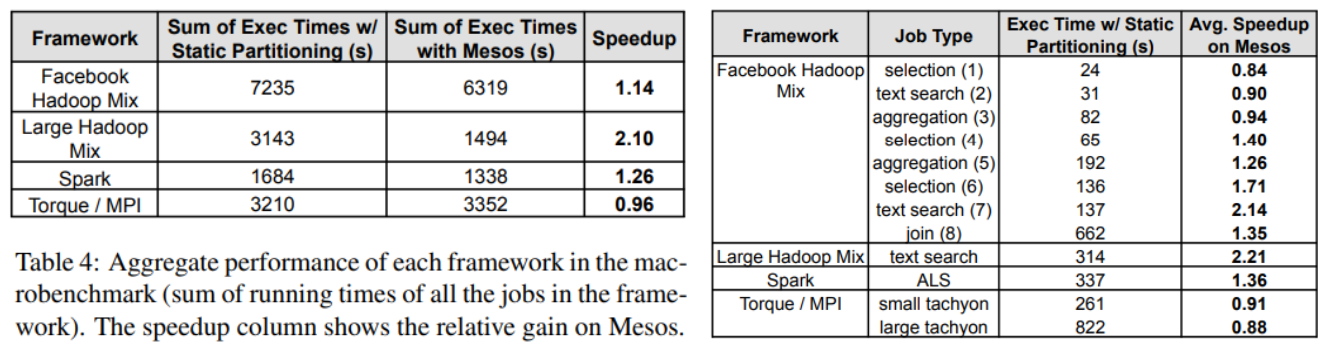
본 챕터에서는 Mesos가 AWS EC2(4CPU, 15GB RAM)에서 시스템이 4개의 워크로드 간 리소스를 공유하는 방식을 평가했다.
- Facebook의 워크로드에 따라 소규모 작업과 대규모 작업을 혼합하여 실행하는 Hadoop 인스턴스 (텍스트 검색/단순 선택/집계/조인의 네 가지 유형의 쿼리로 구성되며, 데이터 필터링(CPU-intensive) 및 데이터 그룹화(I/O-intensive)와 같은 다양한 작업 포함)
- 대규모 배치 작업 세트를 실행하는 Hadoop 인스턴스 (IO-intensive)
- 머신 러닝 작업을 실행하는 Spark (CPU-intensive, 그러나 각 노드에서 입력 데이터를 캐싱하는 이점이 있고, 각 반복마다 작업을 실행하는 모든 노드에 업데이트된 매개변수를 브로드캐스트해야 한다)
- MPI 작업을 실행하는 Torque (CPU-intensive)
=> fair sharing, 96 노드의 Mesos 클러스터에서 4개의 프레임워크로 워크로드를 실행 VS 클러스터의 정적 파티션(24 노드) 비교
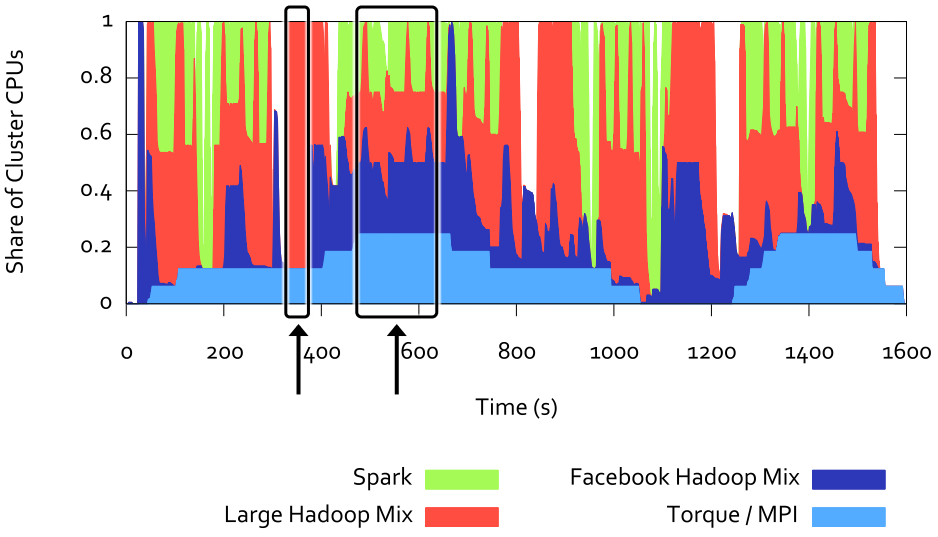
- 다른 프레임워크의 수요가 낮은 기간 동안 Mesos를 통해 각 프레임워크가 확장될 수 있다
- Hadoop/Spark: 글로벌 수요가 허용하는 경우 Mesos를 활용하여 클러스터의 1/4 이상으로 확장하고, 결과적으로 작업을 더 빠르게 완료할 수 있다
- Torque: Mesos에서 거의 유사한 할당과 작업 기간을 달성하며, 더 오래 걸리기도 함 => 부분적으로 Torque가 각 작업을 시작하기 전에 Mesos에서 24개의 작업을 실행할 때까지 기다려야하기 때문
- Hadoop mix: 가장 큰 이득을 보는 프레임워크로, 거의 항상 실행할 작업이 있고 다른 프레임워크의 수요 부족을 메워준다
- 규모가 작은 작업일수록 새로운 리소스를 제안 받기까지 지연이 생기므로 Mesos에서 성능이 더 나쁘다
단, Mesos의 오버헤드는 실험 결과 4%미만으로 거의 없었다.

- 정적 파티셔닝: Hadoop 인스턴스가 파티션 외부의 노드에서 데이터를 가져와야 하므로 데이터 로컬리티(18%)가 매우 낮다
- Mesos: 지연 스케줄링 없이도 데이터 로컬리티가 향상 => 각 Hadoop 인스턴스는 클러스터의 더 많은 노드에서 작업을 수행하므로(노드당 4개의 작업) 로컬로 더 많은 블록에 액세스할 수 있기 때문
- 지연 스케줄링: Mesos는 프레임워크에 리소스를 즉시 할당하는 대신 리소스를 제공하기 전에 일정 시간 동안 기다림으로써 여러 프레임워크가 리소스 요구 사항을 표현한 다음 그에 따라 리소스를 제공 = 성능 향상
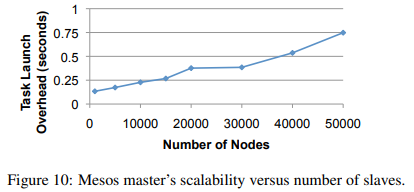
- 99개의 Amazon EC2 노드에서 최대 50,000개의 슬레이브 데몬을 실행하여 대규모 클러스터 실험
- 클러스터 전체에서 실행되는 프레임워크를 사용하여 작업을 지속적으로 실행한 결과, 50,000개의 노드에서도 오버헤드가 1초 미만으로 관찰 됨 = 데이터 센터 워크로드의 평균 작업 및 작업 길이보다 훨씬 작다
- EC2의 가상화 환경은 슬레이브가 5만 개를 넘어서는 확장성에 제한 => 50,000개의 슬레이브에서 마스터가 초당 100,000개의 패킷(인+아웃)을 처리하기 때문이며, 이는 현재 EC2에서 달성할 수 있는 한계이다. 슬레이브 노드가 더 많아지면 네트워크 혼잡 및 기타 요인으로 성능이 저하될 수 있다.
Discussion
Mesos 스케줄링 시스템을 통해 프레임워크는 어떤 오퍼를 수락할지 선택할 수 있으며, 프레임워크가 짧은 작업을 사용하고, 탄력적으로 확장하며, 알려지지 않은 리소스를 수락하지 않도록 하는 장점이 있다. 그러나 분산형 스케줄링은 파편화, 상호 의존적인 프레임워크 제약, 프레임워크의 복잡성 증가 등 중앙 집중식 스케줄링에 비해 한계가 있을 수 있다
- 클러스터 환경에서의 분산 스케줄링 접근 방식의 한계
- 작업의 리소스 요구 사항이 이질적인 경우 중앙 집중식 스케줄러와 마찬가지로 빈 패킹을 최적화하지 못할 수 있다
- 리소스 요구량이 많은 프레임워크가 리소스 요구량이 적은 작업으로 클러스터가 채워질 경우 고갈될 수 있다
- 상호 의존적인 프레임워크 제약으로 인해 클러스터의 단일 전역 할당만 잘 수행되는 시나리오를 구성하기 어려울 수 있다. (단, 이러한 시나리오는 실제로는 드물다)
- 리소스 오퍼를 사용하면 프레임워크 스케줄링이 더 복잡해질 수 있지만, 기존 프레임워크의 많은 스케줄링 정책은 온라인 알고리즘이며 리소스 오퍼를 통해 쉽게 구현할 수 있다
Mesos이 효율적인 이유는:
- 프레임워크가 특정 리소스를 거부할지 여부를 지정하는 필터를 마스터에 제공함으로써 거부 프로세스를 단축할 수 있다.
- Mesos는 프레임워크에 제공되는 리소스를 클러스터 할당에 포함시켜 프레임워크가 오퍼에 신속하게 응답하고 사용할 수 없는 리소스를 필터링하도록 인센티브를 부여
- Mesos는 프레임워크가 응답하는 데 너무 오래 걸리는 경우 오퍼를 취소하고 다른 프레임워크에 리소스를 다시 제공
특히 프레임워크가 탄력적으로 확장 및 축소할 수 있고, 작업 지속 시간이 균일하며, 프레임워크가 모든 노드를 동일하게 선호할 때 더 효율적이다.
https://github.com/apache/mesos
GitHub - apache/mesos: Apache Mesos
Apache Mesos. Contribute to apache/mesos development by creating an account on GitHub.
github.com