💡 요약
- abstract: 모바일 디바이스에 서비스형 컴퓨팅 오프로딩을 제공하여 이러한 격차를 해소하는 COSMOS 시스템의 설계와 구현에 관한 연구
- introduction: 모바일 디바이스에서 연산 오프로드를 위해 컴퓨팅 리소스를 요구 방식과 클라우드 제공업체의 리소스 제공 방식이 일치하지 않고, 모바일 디바이스가 오프로딩을 사용할 경우 무선네트워크를 사용하는데 이러한 경우 오프로딩 성능의 저하, 높은 비용이 발생한다는 문제점이 있다.
- related works: 데이터센터의 전력 소비 비용을 최소화하는 데 초점, 가변적인 네트워크 등은 고려되지 않았다.
- method: 상용 클라우드 서비스 제공업체로부터 컴퓨팅 리소스를 동적으로 확보하여 모바일 사용자의 컴퓨팅 오프로드 수요에 할당한다. 최적화 문제를 제시하고 리소스 관리 메커니즘, 위험 제어 메커니즘, 작업 할당 알고리즘을 포함한 COSMOS 의사 결정의 세 가지 구성 요소를 제안한다.
- experiment: 스마트폰/태블릿에서 Amazon EC2로 오프로딩하는 시스템을 평가한 결과, 기존 오프로딩 시스템에 비해 금전적 비용을 크게 절감하는 것으로 나타났다.
- conclusion & discussion:
Introduction
오프로딩은 컴퓨팅 자원 및 계산 속도의 한계를 극복하기 위해, 모바일 애플리케이션의 연산 집약적인 부분을 클라우드 컴퓨팅 리소스로 전송하여 성능을 개선하고, 에너지 소비를 줄이는 프로세스이다.
- 모바일 디바이스의 컴퓨팅 리소스 요구 방식과 클라우드 제공업체의 리소스 제공 방식이 일치하지 않아 오프로딩 성능이 저하되고 금전적 비용이 높아질 수 있다.
- 연산 오프로딩에 적합한 이상적인 컴퓨팅 리소스는 요청 시 즉시 사용할 수 있어야 하며 실행 후 신속하게 해제되어야
- 클라우드 리소스는 설정 시간이 길고 장기간 임대된다
- 모바일 기기가 서비스 비용이 높은 무선 네트워크를 통해 클라우드 리소스에 접근
- 3G 네트워크는 상대적으로 대역폭이 낮아 연산 오프로딩을 위한 통신 지연이 길어짐
- WiFi 네트워크는 대역폭이 높고, 무료로 사용할 수 있지만 커버리지가 제한되어 있어 클라우드에 간헐적으로 연결
따라서 본 논문에서는 모바일 장치에 컴퓨팅 오프로딩을 서비스로 제공하는 COSMOS 시스템을 제안한다.
- 상용 클라우드 서비스 제공업체로부터 컴퓨팅 리소스를 동적으로 확보하여 모바일 사용자의 컴퓨팅 오프로드 수요에 할당
- 계산 오프로딩에 적합한 리소스를 선택하고 오프로딩 요청에 따라 컴퓨팅 리소스를 적응적으로 유지하는 리소스 관리 메커니즘
- 오프로딩 결정을 내릴 때 수익과 위험을 적절히 평가하는 위험 관리 메커니즘
- 제한된 제어 오버헤드로 클라우드 리소스에 오프로딩 작업을 적절히 할당하는 작업 할당 알고리즘
Background
2.1.1. Computation Offloading
연산 오프로딩 시스템 = 클라이언트 컴포넌트(모바일 디바이스에서 실행) + 서버 컴포넌트(클라우드에서 실행)
- 클라이언트 컴포넌트
- 모바일 디바이스의 네트워크 성능을 모니터링하고 예측
- 모바일 디바이스와 클라우드 양쪽에서 입출력 데이터 요구 사항과 실행 시간 측면에서 모바일 애플리케이션의 실행 요구 사항을 추적하고 예측
- 클라이언트 컴포넌트는 이 정보를 사용하여 계산의 일부분을 클라우드에서 실행하도록 선택하여 총 실행 시간을 최소화
- 서버 컴포넌트
- 오프로드된 부분을 수신한 후 즉시 실행 및 결과값을 클라이언트 컴포넌트에 반환
일반적으로는 통신 비용을 손해보는 대신 계산적 이득을 얻지만,
불안정한 네트워크 연결과 불충분한 클라우드 리소스 환경에서는 통신 비용이 증가하고 계산 이득 또한 낮아질 수 있다
2.1.2. Cloud Computation Resources
클라우드 컴퓨팅 리소스는 일반적으로 가상 머신(VM) 인스턴스 형태로 제공되며, VM에 OS를 설치하고 시작해야하기 때문에 이 과정에서 지연이 발생한다. VM 인스턴스는 일반적으로 시간 단위로 임대된다.
Related Work
- cyber foraging, cloudlet 등
- 데이터센터의 전력 소비 비용을 최소화하는 데 초점
- MAUI, CloneCloud, ThinkAir: 애플리케이션에서 컴퓨팅 집약적인 부분을 식별하거나 서버 측 지원을 통해 병렬 작업 오프로딩을 활성화하여 모바일 디바이스 전용 컴퓨팅 오프로딩을 활성화하는 방법에 중점
차별점
- 가변적인 네트워크 연결 조건을 처리
- 성능과 금전적 비용을 고려하면서 오프로딩 요구와 클라우드 컴퓨팅 리소스 간의 격차를 해소시킨다.
Method
본 연구에서 COSMOS 시스템은 네트워크 연결, 프로그램 실행 및 리소스 경합의 불확실성을 고려하면서 오프로딩 결정과 작업 할당을 최적화하는 것을 목표로 한다.

- COSMOS Master: 클라우드 리소스를 관리하고 모바일 디바이스와 통신
- COSMOS Server: 오프로드된 작업을 실행하고 대기열에 있는 작업의 실행 시간을 예측
- COSMOS Client: 모바일 애플리케이션을 모니터링하고 컴퓨팅 집약적인 작업을 식별하며, 연산 속도 향상과 통신 지연 예측을 기반으로 오프로드 여부를 결정
작업이 오프로드되면 활성 COSMOS 서버에 할당되고 기한 내에 결과를 받지 못하면 로컬 워커에서 작업이 실행된다.
- Cloud resource management: 비용을 최소화하면서 오프로딩 속도를 높이기 위해 시간 경과에 따라 임대할 가상 머신(VM) 인스턴스의 수와 유형을 결정
- resource selection:
- Mi: VM 인스턴스 유형 선택
- Ti: COSMOS 서버를 시작 및 중지하는 시기 선택
- 프로세서 코어 수 & CPU 주파수 & 각 VM 인스턴스의 가격을 고려하여 선택: COSMOS는 일정 수준의 속도 향상을 보장하면서 오프로딩 비용을 절감하는 것을 목표로 하므로, CPU 주파수가 가장 강력한 VM 인스턴스의 1 - δ보다 큰 가장 비용이 적게 드는 VM 인스턴스를 선택한다고 하자 => 가능한 최대 1 - δ 이상의 속도 향상을 달성
- server scheduling: 서버 스케줄링은 VM 인스턴스의 사용 비용과 오프로딩 성능의 균형을 맞추는 핵심 메커니즘
- COSMOS Master는 주기적으로 오프로딩 요청 수와 COSMOS 서버의 워크로드를 수집 => 워크로드가 너무 많으면 새 서버를 켜고, 더 이상 오프로딩 요청을 처리할 필요가 없으면 서버를 끈다.
- COSMOS Master는 오프로드된 연산 작업의 현재 도착률과 서비스 시간을 계산하여 원하는 오프로드 성능을 달성하는 데 필요한 최소 COSMOS 서버 수를 추정하여 활성 서버 수 조정
- COSMOS 서버가 처리할 수 있는 최대 도착 속도(λs)를 추정하기 위해 Kingman의 공식을 사용; λs = c / [μ(1 - δ)]
- input: 필요한 속도 향상(즉, 최대 속도 향상의 1-δ), 시스템의 최대 응답 시간(μ(1-δ)보다 작아야 함)
- c: 서버 수, μ: 서버의 서비스 속도
- λs = 단일 서버가 δ 및 μ로 지정된 성능 요구 사항을 충족하면서 처리할 수 있는 초당 오프로딩 요청 수
- resource selection:
- Offloading decision: 네트워크 연결 및 리소스 경합과 같은 불확실성을 고려하여 컴퓨팅 작업을 모바일 기기에서 VM 인스턴스로 오프로드할지 아니면 로컬에서 실행할지를 결정
- Offloading Controller: connectivity/execution predictor의 정보를 사용하여 오프로딩 서비스의 잠재적 이점을 추정
- greedy 전략: 오프로드 가능한 작업이 시작될 때마다 오프로드 컨트롤러는 해당 작업을 오프로드하는 것이 유리한지 여부를 결정 => 만약 잘못된 결정이 내려지면 새로운 정보를 바탕으로 전략 조정
- 예측된 로컬 실행 시간이 오프로드 응답 시간보다 긴 경우에 오프로드하는 것이 유리하다.
- Risk-Controlled Offloading Decision: 모바일 환경의 불확실성 때문에 위험 제어 매커니즘 필요
- 오프로딩의 수익과 위험을 동시에 고려하는 위험 조정 수익 접근 방식을 사용
- 위험 조정 수익률이 특정 임계값을 초과하면 작업이 클라우드로 오프로드되고, 그렇지 않으면 로컬에서 실행 => 시스템은 새로운 정보(연결상태 등)가 입수되면 수익률과 리스크를 재평가하고 그에 따라 결정을 조정
- Offloading Controller: connectivity/execution predictor의 정보를 사용하여 오프로딩 서비스의 잠재적 이점을 추정
- Task allocation: 계산 작업이 오프로드되는 경우 사용 가능한 모든 인스턴스 중에서 VM 인스턴스를 선택하는 작업이 포함되며, 각 모바일 기기에서 독립적으로 결정하고 이전 작업 결정 및 리소스 공유를 고려
- 모바일 디바이스가 작업을 COSMOS 서버로 오프로드하려면 일단 작업을 어느 서버로 보낼지 결정해야한다.
- 서버를 결정하기 위한 세 가지 휴리스틱 방법이 있다:
- 1. COSMOS 마스터가 글로벌 대기열을 유지하여 오프로딩 요청을 직접 수락하고 COSMOS 서버에 유휴 코어가 있을 때 태스크 할당 = 서버 활용도가 높아야 하지만 COSMOS 마스터를 연결하는 네트워크가 병목 현상이 발생 가능
- 2. COSMOS 클라이언트가 COSMOS 서버 집합의 워크로드를 쿼리하여 워크로드가 낮은 서버를 무작위로 선택하여 태스크 할당 = 작업이 COSMOS 서버로 직접 전송되지만 엄청난 제어 트래픽을 유발 & 추가 대기 시간 발생
- 3. COSMOS 마스터가 각 COSMOS 클라이언트에 활성 COSMOS 서버 셋을 제공하고 모든 COSMOS 서버의 평균 워크로드를 알려준다. << COSMOS는 리소스 관리 메커니즘으로 인해 제어 오버헤드가 최소화되고 성능이 좋은 세 번째 방법을 사용
- 모바일 디바이스가 작업을 COSMOS 서버로 오프로드하려면 일단 작업을 어느 서버로 보낼지 결정해야한다.
Experiment
- COSMOS 서버: Android-x86 AMI(32bit OS)를 사용하여 Android x86 및 Amazon EC2 인스턴스에서 구현되었다.
- COSMOS 마스터: Ubuntu 12.04 EC2 인스턴스에서 실행되며, Amazon EC2 API 도구를 사용하여 COSMOS 서버를 관리
- COSMOS 클라이언트: 와이파이 및 3G 연결이 가능한 안드로이드 기기에서 실행되며, 자바 리플렉션 기술을 사용하여 계산 작업의 오프로딩을 지원한다.
속도 향상과 비용이라는 두 가지 메트릭을 사용하여 COSMOS를 평가한다.

- 클론클라우드: 각 모바일 디바이스가 클라우드에 항상 켜져 있는 서버를 가지고 있는 기본 오프로딩 시스템, 안정적인 네트워크 연결을 가정한다.
- 오라클: 오프로딩 결정을 내리는 데 필요한 모든 연결 및 실행 프로파일 정보를 정확하게 알고 있다고 가정한다. (오프로딩 이점에 대한 상한선)
- COSMOS(OP): 리소스 관리를 위한 간단한 전략, 즉 피크 요청에 대해 활성 COSMOS 서버의 수를 오버프로비저닝하는 COSMOS의 변형 => 단, 피크 요청의 수를 사전에 정확하게 예측한다고 가정한다.
세 시스템 모두 비슷한 속도 향상2(a)을 달성하지만, COSMOS의 총 비용2(b)은 CloneCloud 및 COSMOS(OP)보다 훨씬 낮다.
그림 2(c)에서 활성 디바이스 수(파란색 점선)와 활성 COSMOS 서버 수(빨간색 선)를 그래프로 표시하여 COSMOS가 비용을 절감하는 방법을 설명한다 => COSMOS는 오프로딩 요청의 도착률에 따라 활성 COSMOS 서버의 수를 적응적으로 변경함으로써 오프로딩 요청이 적을 때는 일부 COSMOS 서버를 꺼서 비용을 절감한다.
- COSMOS: 오프로딩 요청의 도착 속도에 따라 활성 COSMOS 서버의 수를 적응적으로 변경하여 비용을 절감
- COSMOS(OP): 하루 종일 3대의 COSMOS 서버를 활성화하는 데 더 많은 비용을 지출
- CloneCloud: 약간의 속도 향상 효과만 있을 뿐 COSMOS보다 훨씬 더 많은 비용을 지출
내 Wi-Fi, 실외 Wi-Fi, 실외 3G와 같은 다양한 네트워크 환경에서 COSMOS가 얼마나 잘 작동하는지 테스트하려고 하는데, 동적인 모바일 환경에서는 오프로드 가능한 작업을 호출할 때마다 인터넷 품질이 다르기 때문에 비교가 매우 어렵다. 따라서 공정한 비교를 위해 실험실 컴퓨터를 실행해서 다른 클라우드 리소스로부터의 간섭을 제거한다. 이를 통해 인터넷 속도나 동시에 실행 중인 다른 클라우드 서비스와의 리소스 경합과 같은 외부 요인으로 인한 편견이나 불공정한 장단점 없이 다양한 조건에서 COSMOS가 얼마나 잘 작동하는지 비교할 수 있다.
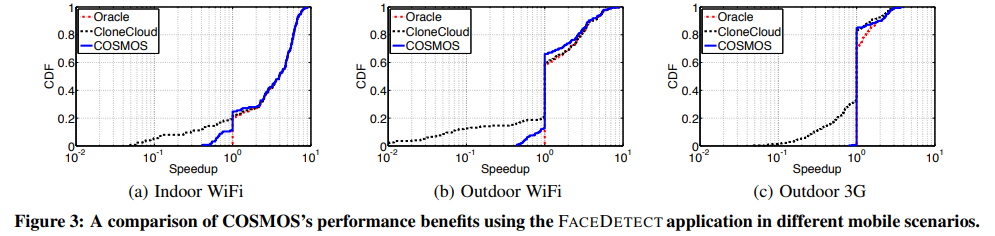
- COSMOS는 성능이 뛰어나며 오라클과 비슷한 성능을 달성하는 동시에, 잘못된 오프로딩 결정 횟수를 줄임으로써 클론 클라우드보다 뛰어난 성능을 발휘한다.
- 클라우드로 계산을 오프로드하면 실내 WiFi 시나리오에서는 약 80%의 경우에서 모바일 애플리케이션에 이점이 있지만, 실외 3G 시나리오에서는 대역폭이 낮고 지연이 길기 때문에 최대 30%의 경우만 이점이 있다
그 다음은, 오프로드 요청 강도가 COSMOS의 성능에 미치는 영향을 분석한다.
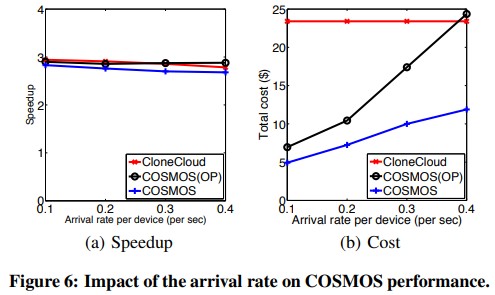
- 시뮬레이션을 사용하여 다른 설정은 변경하지 않고 도착 속도(요청이 발생하는 빈도)를 초당 0.1에서 최대 초당 0.4까지 다양하게 변경 => 비용 절감을 위해 클라우드 리소스 공유가 중요한 낮은 도착률에서 COSMOS가 CloneCloud라는 다른 시스템보다 더 낮은 비용과 더 빠른 속도를 달성
- COSMOS와 COSMOS(OP) 모두 도착률이 낮을수록 비용이 낮아지는 반면, CloneCloud는 비용이 일정 = 비용 절감에 있어 클라우드 리소스 공유가 중요하다
- 도착률이 매우 높은 경우(0.4)에는 COSMOS(OP)가 CloneCloud보다 더 높은 속도를 보인다.
- 모든 실험에서 COSMOS의 속도 향상은 CloneCloud와 COSMOS(OP)의 속도 향상과 유사하다.
- 오프로딩 요청의 수에 따라 비용과 속도 사이에 약간의 트레이드오프가 있을 수 있지만, COSMOS는 CloneCloud와 같은 다른 시스템에 비해 매우 저렴한 비용으로 고성능 계산 오프로딩을 제공할 수 있다
오프로딩 결정을 내리기 위해 COSMOS 클라이언트는 연결 예측과 실행 예측에 의존하여 오프로딩된 작업이 처리를 완료하고 결과를 반환하는 데 필요한 시간(응답 시간)을 추정하게 되는데, 만약 예측에 오류가 있으면 응답 시간이 잘못 예측되어 잘못된 오프로드 결정과 성능 저하로 이어질 수 있다. 이러한 예측 오류에 비해 COSMOS 성능이 얼마나 견고한지 알아보자
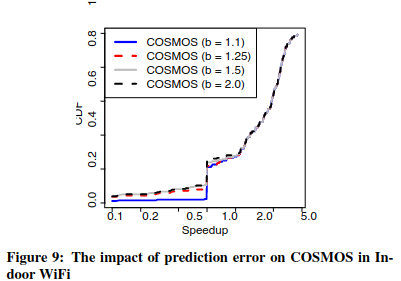
- 예측 오차가 증가함에 따라 COSMOS 성능이 약간 저하되지만, 심각한 오차가 있더라도 대부분 오프로딩 요청에 대해 COSMOS는 여전히 높은 속도 향상을 달성한다. => 오프로딩 이득이 높을수록 예측 오류에 대한 견고성이 더 높다
Discussion
어느 환경에서 실험했는지, 시나리오도 굉장히 자세해서 좋았다. (왜 이런 실험을 했는지도 잘 나와있음)
그리고 어떠한 결과값을 보여 주기 위해서 어떻게 실험 설계를 해야하는지 잘 설명이 되어있어서 배울점이 많았다.
시뮬레이션 뿐만 아니라 실제 트레이스를 가지고 실험 결과를 보여줘서 더 신뢰성이 있었다.