아래 그림과 같이 메모리는 각 프로세스가 사용할 뿐만 아니라 커널 자체도 메모리를 사용한다.
메모리의 통계 정보
시스템의 총 메모리의 양과 사용중인 메모리의 양은 `free` 명령어를 통해 확인할 수 있다. (단위는 Kbyte)
free
total: 시스템에 탑재된 전체 메모리 용량
free: 이용하지 않는 메모리
buff/cache: 버퍼 캐시 또는 페이지 캐시가 이용하는 메모리. 시스템의 free 값이 부족하면 커널이 해제한다.
available: 실질적으로 사용 가능한 메모리 = (free) + (buff/cache)
swap
total: 설정된 스왑 총 크기
used: 사용중인 스왑 크기
free: 사용되지 않은 스왑 크기
htop을 사용하면 실시간으로 좀 더 눈에 잘 들어오는 형태로 모니터링 할 수 있다.
htop
메모리 사용량이 늘어나면 free 의 크기가 줄어든다.
이러한 상태가 되면 메모리 관리 시스템은 커널 내부의 해제 가능한 메모리 영역을 해제한다.
이후에도 메모리 사용량이 계속 증하가면 시스템은 메모리가 부족해 동작할 수 없는 메모리 부족 상태가 된다 = Out of Memory
이러한 경우 메모리 관리 시스템에서는 적절한 프로세스를 강제 종료(kill) 시켜 메모리 영역을 해제한다.
메모리 주소의 할당
커널이 프로세스에 메모리를 할당하는 경우는 크게 두 가지 타이밍에 벌어진다.
1. 프로세스를 생성할 때
2. 프로세스를 생성한 뒤 추가로 동적 메모리를 할당할때
좀 더 자세히 살펴보자.
[운영체제 10판] 9장 메인 메모리
c.f. 파이썬의 경우 인터프리터 언어라서 조금 다를 수 있을 것 같아서 찾아보니, https://stackoverflow.com/questions/19791353/linking-and-loading-in-interpreted-languages - 파이썬은 컴파일 과정이 없다. - 실행 파일(예: /usr/bin/python)이 실제로 실행되는 프로그램이고, 실행할 스크립트를 읽으며 한 줄씩 실행하게 된다. - 그 과정에서 다른 파일이나 모듈(예: /usr/python/lib/math.py)에 대한 참조를 만날 수 있으며 그 때, 이를 읽고 해석한다. - 바이너리 라이브러리들은 런타임에 코드에서 요청 시, 해당 라이브러리를 로드한 다음 사용할 수 있다. - 파일을 처음 실행할 때 바이트코드(.pyc 파일)로 컴파일되고, 다음에 모듈을 가져오거나 실행할 때 코드 실행이 향상된다.
물리 주소를 논리 주소로 변환하는 방법
[운영체제 10판] 9장 메인 메모리
Dynamic Loading: 프로세스가 실행되기 위해 프로세스 전체가 메모리에 미리 올라와 있을 필요는 없다. 메모리 공간을 더 효율적으로 이용하기 위해 동적 적재를 할 수 있다. 동적 적재에서 각 루틴은 실제 호출 전까지 메모리에 올라오지 않고 재배치 가능한 상태로 디스크에 대기하고 있다. 동적 적재는 운영 체제로부터 특별한 지원이 필요없으며, 사용자 자신이 프로그램의 설계를 책임져야 한다. 운영체제는 동적 적재를 구현하는 라이브러리 루틴을 제공해 줄 수는 있다.
예: main 프로그램이 메모리에 올라와 실행된다. 이 루틴이 다른 루틴을 호출하게 되면 호출한 루틴이 이미 메모리에 적재됐는지 조사한다. 만약 적재되어 있지 않으면 재배치 가능 연결 적재기(relocatable linking loader)가 불려 요구된 루틴을 메모리로 가져오고, 이러한 변화를 테이블에 기록해둔다. 그 후 CPU 제어는 중단되었던 루틴으로 보내진다.
Dynamic Linking and Shared Library: 동적 연결 라이브러리(DLL)은 사용자 프로그램이 실행될 때, 사용자 프로그램에 연결되는 시스템 라이브러리이다. 동적 연결에서는 linking이 실행 시기까지 미루어진다. 동적 연결은 주로 표준 C 언어 라이브러리와 같은 시스템 라이브러리에 사용된다. DLL은 여러 프로세스 간 공유될 수 있어 메일 메모리에 DLL 인스턴스가 하나만 있을 수 있으며 공유 라이브러리라고도 한다. 프로그램이 동적 라이브러리에 있는 루틴을 참조하면 로더는 DLL을 찾아 필요한 경우 메모리에 적재한다. 그런 다음 동적 라이브러리의 함수를 참조하는 주소를 DLL이 저장된 메모리의 위치로 조정한다. 동적 로딩과 달리 동적 연결과 공유 라이브러리는 일반적으로 운영체제의 도움이 필요하다. 메모리에 있는 프로세스들이 각자의 공간을 자기만 엑세스 할 수 있도록 보호된다면 운영체제만이 메모리 공간에 루틴이 있는지 검사해 줄 수 있고, 운영체제만이 여러 프로세스가 같은 메모리 주소를 공용할 수 있도록 해줄 수 있다.
c.f. 정적 연결(static linking): 라이브러리가 프로그램의 이진 프로그램 이미지에 끼어 들어간다.
동적 메모리를 할당할 때, 추가적으로 메모리가 필요한 경우 프로세스는 커널에 메모리 확보용 시스템 콜을 호출하여 메모리 할당을 요청한다. 커널은 메모리 할당 요청을 받으면 필요한 사이즈를 빈 메모리 영역으로부터 잘라내, 그 영역의 시작 주소값을 반환한다.
논리 주소를 물리 주소로 변환하는 방법
가상 주소를 물리 주소로 변환하는 과정은 커널 내부에 보관되어 있는 `페이지 테이블`을 사용한다.
가상 메모리는 전체 메모리를 페이지 단위로 나누어 관리하고 있으므로 변환은 페이지 단위로 이루어진다.
(c.f. 물리 메모리는 프레임 단위로 불리는 동일한 크기의 블록으로 나누어진다.)
이때, 페이지 사이즈는 CPU 구조에 따라 다른다. 흔히 사용하는 x86_64의 페이지 사이즈는 4kb이다.
리눅스 시스템에서 페이지 크기를 알아내고 싶다면 `getconf PAGESIZE` 명령을 입력하면 된다. (단위는 바이트)
CPU 에서 나오는 모든 주소는 (페이지 번호) + (페이지 오프셋) 두 개의 부분으로 나누어진다.
페이지 번호: 페이지 테이블 접근 시 사용된다. 페이지 테이블은 물리 메모리의 각 프레임 시작 주소를 저장한다.
페이지 오프셋: 참조되는 프레임 안에서의 위치를 나타낸다.
만약 페이지 테이블에 매핑되지 않은 영역대의 가상 주소에 접근하게 되면 CPU 에는 `페이지 폴트` 인터럽트가 발생한다.
페이지 폴트에 의해 현재 실행 중인 명령이 중단되고, 커널 내의 `페이지 폴트 핸들러` 라는 인터럽트 핸들러가 동작하게 된다.
커널은 프로세스로부터 메모리 접근이 잘못되었다는 내용을 페이지 폴트 핸들러에 알려준 후, `SIGSEGV` 시그널을 프로세스에 통지한다. (이 시그널을 받은 프로세스는 강제 종료된다.)
실제 메모리 할당(Linux)
## C
C언어에서는 표준 라이브러리에 있는 `malloc()` 함수가 메모리 확보 함수이다.
리눅스에서는 내부적으로 `malloc()` 함수에서 `mmap()` 또는 `brk()` 함수를 호출하여 메모리 할당을 구현한다.
## Python
파이썬같이 직접 메모리 관리를 하지 않는 스크립트 언어의 오브젝트 생성에도
최종적으로는 내부에서 C언어의 malloc 함수를 사용하고 있다.
mmap 함수는 페이지 단위로 메모리를 확보하지만, malloc 함수는 바이트 단위로 메모리를 확보한다.
즉, glibc에서는 사전에 mmap 시스템 콜을 이용하여 메모리 풀을 확보한 뒤, 프로그램에서 malloc이 호출되면 메모리 풀로부터 필요한 양을 바이트 단위로 잘라내어 반환하는 처리를 한다. 풀로 만들어 둔 메모리에 더 이상 빈 공간이 없으면 다시 mmap 을 호출하여 새로운 메모리 영역을 확보한다.
glibc의 메모리 풀
사용하는 메모리 양을 체크하여 알려주는 기능의 프로그램들이 있으나, 그 프로그램이 알려주는 사용량과 실제 리눅스에서 사용하는 메모리의 양이 서로 다른 경우가 매우 많다. (일반적으로 리눅스에서 프로세스가 사용하는 메모리 양이 더 많음)
왜냐하면 리눅스에서 측정한 메모리 양은 프로세스가 생성될 때, mmap 함수를 호출했을 때 할당한 메모리 전부를 더한 값을 나타내고, 프로그램이 체크한 메모리 사용량은 malloc 함수 등으로 획득한 바이트 수의 총합을 나타내기 때문에 서로 다르게 표시되기 때문이다. 이러한 프로그램이 체크한 메모리 사용량이 정확히 무엇을 나타내는지는 프로그램에 따라 다르므로 확인해봐야 한다.
실제 메모리 및 특정 시나리오 두 가지의 트레이스를 사용하여 페이지 공유의 실제 문제에 대해 연구한 논문이다.
real world 트레이스에서는 약 15%의 sharing level 을 관찰했는데, 이는 중요하긴 하지만 예상보다는 낮은 sharing 정도였다. 흥미로운 점은, 연구에서 본 대부분의 sharing 은 self-sharing 에서 비롯되었으며, 이 경우에는 가상화가 불필요하다.
공유에 영향을 미치는 다양한 요소에 대한 연구를 진행했다.
homogeneity 플랫폼의 핵심 역할(이종 시스템보다 동종 시스템에서 비교적 많은 sharing 이 관찰됨)
OS 특성 및 애플리케이션 수정의 다양한 점진적인 영향 관찰(OS family, application setup, OS version, OS architecture)
새로운 기술(ASLR과 같은)은 sharing 에 영향을 미칠 수 있다
아마존 EC2 와 같은 대규모 데이터 센터의 서비스의 운영자는 고객에게 기계 리소스를 임대한 다음, 고객은 임대한 기계에서 자체 애플리케이션을 운영한다. 단일 물리적 서버가 여러 고객에게 제공되어야 하기 때문에 공급자는 가상 머신을 이용하여 사용자들을 격리한다. 이러한 모델에서 메모리 효율성은 종종 개별 물리적 서버에서 서비스 제공자가 서비스할 수 있는 고객 수를 결정하는 병목 리소스가 될 수 있다. 대부분의 가상화된 시스템은 단순히 VM 간에 사용 가능한 물리적 메모리를 분할하기 때문에, 각 VM이 소비하는 메모리 양을 기반으로 시스템당 가능한 고객 VM 수가 대략적으로 계산될 수 있다. 그런데 만약, 적은 양의 메모리만 사용하여 각 고객에게 서비스를 제공할 수 있다면 주어진 서버에서 더 많은 고객을 잠재적으로 처리할 수 있으므로 활용도가 높아지고 하드웨어 비용이 절감된다.
Background & Motivation
전통적인 컴퓨터 vs 가상 머신
가상 머신은 가상화를 사용한 가상 환경인데, 가상화 기술을 사용하기 이전에, 전통적인 컴퓨터에서는 물리적인 컴퓨터 하나에 하나의 OS 만 설치가 가능했다.
이런 방식에는 몇가지 문제점이 있었는데,
1. 실제 CPU 가 모두 활용된다면 가장 좋은 퍼포먼스를 낼 수 있었겠지만, 실제로 CPU 를 100% 사용하지 못하는 경우가 많았다.
2. 새로운 OS 가 필요할 때마다 컴퓨터를 추가해야하고, 이는 물리적 공간의 증가, 즉 낭비로 이어졌다.
이렇게 남는 자원을 잘 활용하기 위해서 서버 가상화 기술을 이용한 여러개의 가상 머신으로 나누어 사용하게 되었고, 각각의 가상 머신은 독립적인 물리 서버처럼 동작한다.
가상 머신에서 메모리 주소 체계
가상화 환경에서 메모리 주소 체계를 살펴보면, 그림과 같이 가상주소, 물리주소, 머신 주소라는 세 단계를 가진다.
가상 머신에서 동작하는 게스트 운영체제는 가상화 환경에서 동작한다는 사실을 모르는 상태이며, 하이퍼바이저의 중재 아래 실제 물리 주소로 변환해서 사용된다.
만약에 이런식으로 페이지 중복이 발생하면,
중복된 부분을 제거하고, 동일한 페이지는 공유함으로써 자원을 효율적으로 공유하기 위해 여러가지 Page Sharing 방식을 사용할 수 있다.
Page Sharing 은 크게 두가지 종류가 있을 수 있다.
self-sharing: 개별 VM 내에서 공유하는 방식이며, 왼쪽 그림 예시를 보면 machine 당 A, B, C 3 copy 씩 존재하므로 6개의 중복 페이지들을 절약할 수 있다.
Inter-VM sharing: 여러 VM에서 공유하는 방식이고, 오른쪽 그림 예시를 보면 하나의 shared machine 의 VM 에 3개의 unique 페이지 A, B, C 가 존재하지만, 하이퍼바이저는 copy 페이지들을 공유할 수 있으므로 6개의 중복 페이지들을 절약할 수 있다.
다시 페이지 중복 예시로 돌아와서, Inter-VM sharing 의 하나의 예시 Contents Based Page Sharing를 알아보자.
Contents Based Page Sharing 이란 여러 VM에서 동일한 메모리 페이지를 제거하자는 아이디어로부터 시작되었다.
하이퍼바이저가 VM의 페이지들를 가져와 물리적 메모리에 매핑하고, 이 하이퍼바이저가 중복 페이지들을 탐지하여 중복을 제거하는 것이다. 이 페이지들의 원본을 copy-on-write references 로 대체하며, 과다 사용한 페이지에 대해서는 free 를 함으로써 자원을 절약 할 수 있다.
Copy-on-Write in Operating System Copy-on-Write(CoW) 는 주로 부모 및 자식 프로세스가 초기에 동일한 메모리 페이지를 공유할 수 있도록 하는 리소스 optimization 기술입니다. 상위 또는 하위 프로세스가 공유 페이지를 수정하는 경우에만 페이지가 복사됩니다. (데이터의 단위가 복사되었지만 수정되지 않은 경우 "복사" 는 주로 원본 데이터에 대한 참조로 존재할 수 있습니다.)
CoW 기술의 주요 의도 는 상위 프로세스가 하위 프로세스를 생성할 때마다 상위 프로세스와 하위 프로세스가 처음에 메모리에서 동일한 페이지를 공유한다는 것입니다. 따라서 만약 상위 또는 하위 프로세스가 공유 페이지를 수정하려고 하면, 이 페이지의 사본이 생성되고 수정은 다음에서만 수행됩니다. 해당 프로세스에 의해 페이지 사본이 생성되며 다른 프로세스에는 영향을 미치지 않습니다.
이전 연구들에서는 대부분의 페이지 공유가 여러 컴퓨터에서 공통적으로 사용되는 OS 라이브러리와 같은 중복 메모리 영역으로 인해 발생한다고 제안되었다.
연구자들은 간단한 벤치마크 실험을 진행하면서, 가상화된 환경에서 발견된 공유의 상당 부분이 실제로 각 VM 내부에 있다는 사실이 발견했다. 이는 제안한 이전 연구와 반대되는 결과로, 제로 페이지를 제외하고 평균적으로 총 메모리의 436MB를 공유할 수 있지만, 이 중 2/3(67%)는 개별 VM 내 self-sharing 페이지로 인한 것이며 나머지 3분의 1은 inter-vm sharing 으로 인한 것이었다.
(제로 페이지를 추가하여 통계를 내면, 내부 공유 비율이 3/4(77%) 이상으로 증가하게 된다.)
이는 메모리 공유가 관리되는 방식(예를 들어 더 많은 VM을 함께 배치해도 공유 수준이 크게 증가하지 않을 수 있다는 점)과
메모리 공유가 구현되는 방식(예를 들어 단일 OS 내에서 공유하는 것은 여러 VM에서 공유하는 것만큼 효과적일 수 있다는 점) 모두에 영향을 미친다.
문제 정의 및 실험 방법
일반적인 실제 기계에서는 어떤 수준의 page sharing 이 주로 일어날 것인가?
self-sharing vs inter-vm sharing
laboratory study와 어떻게 다른가?
sharing potential에 영향을 미치는 요소는 무엇인가?
mac/win/linux (OS), mixed versions (major, minor versions), 32/64 bit (architecture of OS
새로운 OS 기술이 sharing에 어떤 영향을 미칠 것인가?
Memory Buddies Traces: collect memory snapshots every 30 minutes
x: sampling of 7 of our machines y: total % of possible self-sharing, memory snapshots for week long period
먼저 실제 메모리 트레이스의 sharing 경향을 보기 위해 일주일동안 30분마다 수집한 트레이스의 self-sharing 에 대한 최대값, 최소값, 그리고 평균값에 대해 집계한 그래프를 보면 (E는 굉장히 특이한 경우이므로 제외하고 해석)
self-sharing 의 점유율의 평균값이 10%가 넘는다
이 값은 크지는 않지만 확실히 중요하다.
위 집계값은 제로 페이지를 완전히 제외한 값이다.
만약 제로 페이지를 추가하여 집계하면 훨씬 더 많은 self-sharing 점유율이 도출된다.
self-sharing maximum 값이 약 50% 까지 존재한다.
트레이스 수집 기간 동안 특정 시점에 많은 기계가 매우 높은 수준의 내부 중복성을 가지고 있었음을 알 수 있다.
minimum 값을 보면 트레이스 수집 일주일간 항상 최소 약 5% 이상의 내부 중복 가능성을 보여주었다.
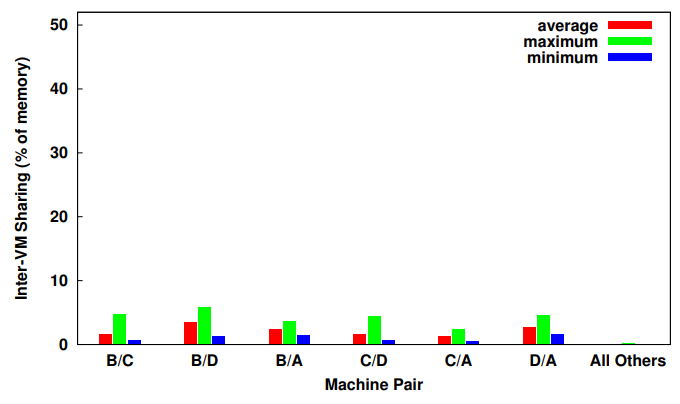
실제 메모리 트레이스의 Inter-VM Sharing 경향
x: variety of pairing of machines (6 most machine pairs shares the most) y: inter VM sharing
Inter-VM sharing 경향을 보면, (그래프는 inter-VM sharing 이 가장 높은 쌍 6개를 보여주고 있음)
inter-VM sharing의 평균값은 약 2%로 매우 낮으며, 나머지 15개의 페어링에서는 더 낮은 0.1% 의 inter-VM sharing 이 관찰되었다.
maximum 값을 보더라도 페어링 머신에서 inter-VM sharing은 6%를 넘지 않았다.
왜 self-sharing 이 크게 나타났을까? 그 이유를 알아보고자 케이스 스터디가 진행되었다.
linux desktop 에서 linux memory tracker 를 사용하여 트레이스 추출하게 되면, 페이지의 내용과 이를 사용하는 프로세스를 추적할 수 있고, 개별 페이지의 해시 값을 알 수 있다고 한다.
=> 높은 Sharing 참여 프로세스(최소 30%) 는 GUI apps/libs 와 관련되어 있다 => 시스템 백그라운드 프로세스들은 sharing 에 적게 관련되어 있다.
=> 거의 모든(94%) 자체 공유가 공유 라이브러리 및 프로그램 힙과 관련이 있다.
이 트레이스의 sharing 참여도를 분석해 본 결과, 왼쪽 그래프를 보면, 데스크 탑 애플리케이션을 분석한 것이라 그런지 GUI 프로세스가 메모리 사용량을 지배한다는 점을 알 수 있다.
오른쪽은 개별 공유 라이브러리와 나머지 요소들의 sharing 참여도를 분석한 그래프인데, x축의 빨간 색은 개별 공유 라이브러리를 각각 나타내고, 파란색의 libraries는 전체 공유 라이브러리 합계, heap은 모든 프로그램 힙, 그리고 stacks은 모든 프로그램 스택을 나타낸다.
그래프를 보면 50%에 달하는 self-sharing 이 프로그램 힙과 관련이 있음을 알 수 있다.
이렇게 힙 페이지가 가장 많이 공유되고 있는 상황은 특정 데이터 구조를 반복적으로 할당하고 해제하는 부산물일 가능성이 높다.
왜냐하면 페이지 사본에는 현재 사용중인 페이지 뿐만 아니라 OS 에서 아직 회수하지 않은 오래된 페이지가 포함될 수 있기 때문이다.
공유 라이브러리 중 가장 많이 공유되는 단일 라이브러리는 Firefox에서 사용하는 사용자 인터페이스 라이브러리인 libxul이다. libc와 같은 다른 라이브러리가 더 널리 사용되지만, 전반적으로 훨씬 적은 공유에 관여했다.
위 결과로 해당 프로세스들에서 데이터 할당이 중복되고 자체 공유가 많이 발생함을 알 수 있었다.
Sharing 에 영향을 주는 요소
Sharing 에 영향을 줄 수 있는 요소로 플랫폼의 동질성을 생각해 볼 수 있다.
먼저 real-world 트레이스 분석과 같이 self-sharing 에 대한 영향을 분석해보면,
OS 제품군 및 버전을 보는 것만으로도 상당한 차이점이 있음을 알 수 있다.
MAC, Windows XP VM의 경우 Windows 7, Linux VM 들에 비해 훨씬 더 높은 self-sharing 을 나타낸다.
(=> Mac OS X 및 Windows XP 시스템이 더 높은 수준의 내부 메모리 중복성을 지향하는 경향이 있으며 이 중복성을 활용하면 더 큰 이점을 볼 수 있음)
특히 VM이 새로 부팅되었지만 더 이상 소프트웨어를 실행하고 있지 않음을 나타내는(no-app) 빨간 바를 보면,
server 또는 desktop 과 같이 응용 프로그램을 추가할 때 공유가 no-app에 비해 크게 바뀐점이 없다는 것을 알 수 있다.
이는 기본 시스템이 대부분의 self-sharing 을 제공하며, user-level applications에서는 아주 작은 sharing 증가를 포함한다는 점을 뜻한다.
또 다른 흥미로운 점은 32비트 시스템에서 64비트 시스템으로 전환할 때 Ubuntu의 두 버전에서 공유하는 기본 시스템이 크게 감소한다는 것이다. (=> 32비트 시스템 라이브러리보다 64비트 시스템 라이브러리에서 더 낮은 수준의 중복성을 나타낸다.)
참고로 두 버전에서 CentOS 에 대해 공유하는 비율은 매우 낮다.
이는 앞쪽의 process 별 분석에서 추론할 수 있듯이, 주로 GUI가 없기 때문이라고 볼 수 있다.
이제 플랫폼 동질성에 대한 Inter-VM Sharing 영향을 분석해보면,
모든 페어링에 대한 완전한 결과는 그래프에 생략되어 있지만 대표적인 샘플은 그림 8 과 9에 나와 있다.
그림 8은 선택된 페어링에 대한 Inter-VM Sharing 의 메가바이트 단위 절대적인 값을 보여주고,
그림 9는 각 페어링에 대한 self-sharing 과 inter-VM sharing 의 상대적 중요성을 보여준다.
첫 번째 알 수 있는 점은 major OS (Mac OS X - Windows 또는 Linux) 간의 페어링에서는 Inter-VM sharing 이 무시할 수 있는 정도라는 점이다. 그래프 외의 모든 경우에 대해, 이러한 쌍은 그림 8에서 볼 수 있는 것처럼 mac/win7-64 쌍과 매우 유사하다.
그래프를 보면 no-app(기본 시스템) 의 inter-vm sharing 은 거의 없고, 서버 애플리케이션이나 데스크탑 애플리케이션을 셋업 했을 때 아주 작은 inter-vm sharing 을 관찰 할 수 있다.
애플리케이션 셋업 시 작은 inter-vm sharing 이 관찰 된 이유는 공유 리소스 파일 때문일 가능성이 높고, 그래서 서버 케이스보다 데스크탑 케이스에서 훨씬 더 크다고 생각할 수 있다.
두번째 알 수 있는 점은 공통 major 플랫폼의 다른 버전을 함께 사용하면 no-app(기본 시스템)에서 inter-vm sharing 이 매우 작은 값이지만, 공통 응용 프로그램의 경우 inter-vm sharing 의 비율이 증가됨을 관찰 할 수 있다.
기본 시스템에는 inter-VM sharing 이 5% 미만으로 거의 없지만, 애플리케이션을 셋업 하면 inter-VM sharing 양이 크게 증가한다.
이는 office 프로그램과 같은 많은 응용 프로그램 자체가 이러한 시스템에서 동일한 버전을 실행하여 상당한 양의 inter-VM sharing 이 추가되기 때문이다.
마찬가지로, Ubuntu 페어링을 살펴보면, Ubuntu 10.04와 10.10 32비트 간에 75% self-sharing 을 살펴봤을 때, no-app 기본 시스템에서 inter-vm sharing 이 매우 작은 값이라는 점을 알 수 있지만, 앱 셋업을 하게 되면 상당한 응용 프로그램 공유가 표시된다.
세번째로 inter-vm sharing 에 영향을 줄 수 있는 요소로 os architecture 가 있다.
32비트에서 64비트로 OS architecture 을 변경할 때를 관찰해보면, 대부분의 inter-vm sharing 을 완전히 제거하는 주요 OS 버전을 변경하는 것보다 훨씬 "덜" 영향이 있다.
아키텍처별 동작을 볼 수 있는 한 가지 주목할만한 사례는 두 개의 64비트 Ubuntu 버전(ub04-64/ub10-64)을 페어링할 때이다.
이 경우, no-app 시스템의 80%에 달하는 공유는 self-sharing 이 아닌 inter-vm sharing 으로 인한 것이다.
그 이유는 이전에 그림 7에서 볼 수 있는 것처럼 두 시스템 모두 self-sharing 이 최소화되었기 때문일 수 있다.
정리하자면, family, applications, version, architecture 순으로 inter-VM sharing 을 감소시키는 영향이 크기 때문에,
inter-VM sharing 을 개선하기 위해 family, applications, version, architecture 순으로 수정해보는 노력을 할 수 있다.
Memory Security and Sharing
마지막으로 OS 기술의 발전이 sharing 에 어떤 영향을 미치는지 알아보자.
운영 체제 설계자는 공격자로부터 시스템을 강화하고 악용 기회를 줄이기 위한 새로운 방법을 끊임없이 모색하고 있다.
한 가지 일반적인 공격은 메모리 버퍼 오버플로 공격이다. 만약 메모리 오버플로우가 일어나서 덮어쓴 메모리가 키 라이브러리 기능과 같이 알려진 주소에 있는 경우에는 메모리를 다루는 데에 오류가 발생하여 잘못된 동작을 야기할 수 있다. 이러한 종류의 공격에 대해 시스템을 강화하기 위해, 최신 운영 체제는 메모리에서 주요 라이브러리 및 프로그램 리소스(예: 힙)의 위치를 무작위로 지정하는 주소 공간 레이아웃 무작위화 기술을 사용한다.
이 기술은 공격자가 알려진 주소를 사용하는 것을 방지하기 위해 설계되었으며, 그림 13a에 표시된 주소 공간의 예에 대해 두 가지 가능한 무작위화가 그림 13b 및 13c에 나와 있다.
주소 공간 레이아웃 무작위화는 좋은 보안 수단이지만, 동일한 VM 에 대해 메모리 적재 시마다 달라지는 기법이므로, 페이지 공유 가능성에 영향을 미칠 가능성이 있다. ASLR이 활성화된 경우에는 동일한 소프트웨어를 실행할 수 있는 두 VM의 메모리 내용이 달라질 수 있으므로 공유 가능성이 줄어든다. 예를 들어, 그림 13b 및 13c에서 보여주는 랜덤화된 주소 공간은 랜덤화되지 않은 경우보다 더 적게 공유할 수 있다.
연구에서는 여러 운영 체제에서 여러 구현을 평가하여 ASLR이 공유 가능성에 미치는 영향에 대한 연구를 수행했다.
Ubuntu 10.10 64비트 (표준 Ubuntu 커널 버전/패치된 PaX버전 2.6.32)
Windows 7 64비트
Mac OS X 10.7
총 4개의 기기에서 실험이 진행 되었는데, 이 실험의 의도는 4가지 ASLR 구현 각각에 대해, 무작위화가 공유에 영향을 미치는지 여부를 식별하고, 만약 그렇다면 이 영향의 범위를 결정하고자 하는 것이었습니다.
이를 위해 각각은 동일한 기본 이미지에서 부팅되는 시나리오를 시뮬레이션합니다.
(왜냐하면 기본 이미지 부팅은 가상화와 페이지 공유 둘다 확인할 수 있는 시나리오이며, 사용자가 sharing 가능성을 fine-tuning 하게 되는 경우를 나타냅니다. )
테스트 방식은 다음과 같다.
1. ASLR을 전역적으로 비활성화
2. VM을 재부팅하여 메모리를 안정적인 상태로 재설정하고, 셸 스크립트 또는 배치 파일을 사용하여 미리 정의된 응용 프로그램 목록(웹 브라우저, 텍스트 편집기, 사무용 소프트웨어, 음악 플레이어 등)을 열어 VM의 메모리를 채운다.
3. 메모리 내용이 안정화된 후, '무작위화되지 않은' 메모리 스냅샷을 캡처한다.
4. ASLR을 전역적으로 활성화한다.
5. 재부팅한 다음 스냅샷 절차를 다시 반복하여 '무작위' 스냅샷을 얻는다.
공유 감소 비율에 대한 결과는 그림 14 에 확인할 수 있다. 총 공유 감소는 self-sharing 및 inter-VM sharing 으로 더 세분화되어 분석했습니다. – 주의할 점은, self-sharing 과 inter-vm sharing 이 총 sharing 에 동등하게 기여하지 않기 때문에 total-sharing 에는 이들 값이 추가되지 않는다는 점이다.
ASLR 을 활성화 하게 되면, total sharing 이 작지만 눈에 띄게 감소하는 것을 볼 수 있다.
주의할점은 Mac 은 시스템 자체에 대해 무작위화가 비활성화되지 않았으므로. 눈에 띄는 total sharing 감소를 관찰 할 수 없었다.
(Mac Lion 내에서 무작위화를 비활성화하는 직접적인 방법은 없습니다. – 알려진 유일한 방법은 프로세스 생성 중에 특정 POSIX 플래그를 설정하는 것입니다. 이를 활용하기 위해 단순히 이 플래그를 설정한 다음, 무작위화 없이 실행되는 대상 응용 프로그램을 생성하는 스크립트를 작성합니다.)
이외의 다른 sharing 들을 약 10% 이상의 total sharing 감소가 관찰되었다.
좀더 자세히 보면, Linux의 경우 ASLR은 self-sharing 및 inter-vm sharing 모두 줄였다.
그러나 Windows의 경우, total-sharing 이 inter-vm sharing 으로 인한 것이었다. windows 에서 self-sharing은 시스템은 무작위화에 상관없이 동일한 양을 공유한 것이다. 이는 가상화되지 않은 환경에서, Windows에서의 공유가 ASLR의 영향을 전혀 받지 않는다는 것을 의미한다.
Mac OS X에서는 Windows와 반대 동작이 관찰되었는데, inter-vm sharing 감소가 관찰되지 않았기 때문에 여기에서 모든 감소는 모두 self-sharing 으로 인한 것이다. 이에 대한 한 가지 이유는 자체 공유의 상대적인 양일 수 있다. (그림 7. 앞쪽에서 확인했듯이 Mac OS X의 자체 공유는 Windows 7보다 훨씬 높음)
결론
결론적으로 페이지 공유는 메모리 효율성을 높일 수 있는 기회를 제공하기 위해 나온 개념이지만,
메모리 효율성을 증가시키는 이점을 극대화 하기 위해서는 페이지 공유에 영향을 미치는 요인을 이해하는 것이 중요하다.
이 연구에서는 페이지 공유의 소스에 대한 조사 및 분석을 제시하며 많은 경우 공유 가능성의 대부분은 여러 시스템, Inter-VM Sharing 이 아니라 단일 시스템, Self-Sharing 의 중복성에 기인한다는 것을 발견했다. 이것은 Sharing 이 가상화된 시스템에 제한될 필요 없이 단일 VM 수준에서 또한 효과적으로 활용될 수 있음을 시사한다.
또한, VM 간 공유를 위해, 여러 애플리케이션 플랫폼을 조사하고 운영 체제 동질성이 Inter-VM Sharing 의 가장 중요한 구성 요소라는 점을 발견했다. (애플리케이션과 아키텍처 및 버전 동질성은 그 다음 요소)
그리고, Linux 커널 내에서 자체 공유에 대한 Case Study 를 수행하고, GUI 응용 프로그램 및 관련 시스템 라이브러리가 자체 공유 가능성의 가장 명확한 소스임을 발견했다. (Linux 외 다른 OS 에서도 동일한지 향후 연구로 남겨 둠)
마지막으로, 주소 공간 레이아웃 무작위화가 공유 가능성에 미치는 영향을 조사했다. 그 결과 모든 주요 시스템에서 이 기능이 공유 잠재력에 측정 가능한 부정적인 영향을 미친다는 것을 발견했다.
The Strategy Pattern defines a family of algorithms, encapsulates each one, and makes them interchangeable.
Strategy lets the algorithm vary independently from clients that use it.
Strategy Pattern 은 알고리즘군을 정의하고, 그 알고리즘들을 서로 바꿔가면서 쓸 수 있게 하는 패턴이다.
각 알고리즘은 캡슐화되어 있기 때문에 클라이언트에서 손쉽게 서로 다른 알고리즘을 사용할 수 있다. 이때, 클라이언트들에게 객체 구성을 통해 알고리즘 구현을 선택할 수 있게 해준다. (유연하다)
Duck class에 fly 와 quack 기능을 추가한다고 하자. 이때, 어떤 상속 클래스들은 날 수 없을 수도 있고, 어떤 클래스들은 꽥꽥 울 수 없다.
만약 단순하게 Child class 에서 fly 와 quack 메소드를 오버라이드 하게 되면 변경이 있을 때마다 모든 서브클래스를 살펴봐야 한다.
이러한 경우, 아래와 같이 오리마다 달라지는 부분과 그렇지 않은 부분을 분리하고,
오리를 정의할 때 동적으로 flyBehavior/quackBehavior 알고리즘을 선택할 수 있도록 하는 것이 Strategy 패턴이다.
Q. Behavior을 만들 때 왜 인터페이스를 쓰는 것일까? = 상위 형식에 맞추어 프로그래밍 = 실제 실행 시에 쓰이는 객체가 코드에 의해 고정되지 않는다 (다형성) = 클라이언트측에서 사용할 때, 실제 객체 형식을 몰라도 된다
Q. 다형성이란?
같은 모양의 코드가 다른 행위를 하는 것 (OCP, DIP 와 관련) => 중복을 줄이며 변경 확장에 유연하다 방법 1) Overriding - 슈퍼클래스를 상속받은 서브클래스에서 슈퍼클래스의 (추상)메소드를 같은 이름, 리턴값, 인자이나 새로운 로직으로 정의 - 런타임 시점 선택
방법 2) Overloading - 하나의 클래스에서 같은 이름의 다른 인자를 가진 메소드들을 여러개 정의 - 컴파일 시점 선택 - ex) 생성자 오버로딩
방법 3) 함수형 인터페이스 - 람다식을 사용하기 위한 API로, 자바에서 인터페이스에 구현할 메소드가 1개일 때를 말함 - ex) enum 계산기
출처 - https://brunch.co.kr/@kd4/4
장점
런타임에 개체 내부에서 사용되는 알고리즘을 교환할 수 있다.
알고리즘을 사용하는 코드에서 알고리즘의 구현 세부 정보를 분리할 수 있다.
상속을 구성으로 대체할 수 있다.
개방/폐쇄 원칙 =>컨텍스트를 변경하지 않고도 새로운 전략을 도입할 수 있다.
단점
알고리즘이 몇 개만 있고 거의 변경되지 않는 경우 오히려 복잡해진다.
언제 사용하는가?
객체 내에서 다양한 알고리즘 변형을 사용하고 런타임 중에 한 알고리즘에서 다른 알고리즘으로 전환할 수 있도록 하려는 경우
일부 동작을 실행하는 방식만 다른 유사한 클래스가 많이 있는 경우 (c.f. 템플릿 메소드 패턴)