💡 요약
- abstract: 딥러닝 모델을 학습하는 컨테이너의 리소스 사용량을 분석하는 방법에 관한 연구
- introduction: 딥 러닝 클라우드 서비스에 컨테이너를 배치할 때, 동적으로 배치 시 최적의 리소스 요구량을 자동으로 예측하기 어렵다.
- related works:
- method: 모니터링을 통해 서로 다른 DL 모델을 학습하는 컨테이너의 반복되는 패턴과 리소스 사용의 유사성을 관찰하여, 반복 패턴을 스케줄러 또는 리소스 오토스케일러에서 활용한다.
- experiment: 통계 기반 사후 대응 대책과 비교했을 때, CPU 및 메모리 할당을 최대 30% 줄일 수 있었다.
- conclusion & discussion: 리소스 사용 메트릭에서 컨테이너 변화를 측정하고, 리소스 수요를 추정하여 딥 러닝 워크로드에 대한 컨테이너 자동 확장 정택을 고안하는 메커니즘을 구축했다.
Introduction
기존 고성능 컴퓨팅 환경에서는 특정 학습 작업마다 전용 머신을 리소스 요구량에 맞는 서버를 설정(프로비저닝)했다면,
IBM DLaaS 또는 Google Cloud AI Platform, Kubeflow 등의 클라우드의 네이티브 머신러닝 서비스는 동일한 머신에 여러 개의 컨테이너를 함께 배치할 수 있는데, 만약 각 컨테이너에 고정된 양의 리소스를 할당하면 리소스가 과도하게 할당될 수 있다. 왜냐하면 각 컨테이너마다 필요한 리소스양이 다를 수 있기 때문이다.
각 컨테이너에 리소스를 동적으로 프로비저닝하려면 과소 프로비저닝 및 서비스 품질(QoS) 저하 방지를 위한 사전 예방적 정책이 필요하다. 모든 컨테이너는 서로 다른 모델에 대한 트레이닝을 실행한다고 가정하면, 보편적으로 알맞은 정책은 찾기 어려울 것이다. 또한, 복잡하고 변화하는 리소스 요구량은 기존의 시계열 알고리즘(ARIMA, ARMA 등)만으로는 모델링하기 어렵다.
본 논문에서는 Conditional Restricted Boltzmann Machine을 사용하여 리소스 사용량의 다변량 시계열을 인코딩하고, 비지도 클러스터링 방법을 적용하여 컨테이너의 리소스 변화량을 자동으로 발견할 것을 제안했다.
- DL 워크로드와 같은 무작위적이고 복잡한 패턴의 burst 및 spike를 학습함으로써 패턴을 발견할 수 있다.
- 트리와 그래프를 사용하여 컨테이너에서 학습한 모든 단계 시퀀스를 기반으로 컨테이너 작동 단계를 모델링한다.
Backgrounds
Autoscaling: 실제 사용량이 정점에 도달하기 전 미래의 리소스 수요 촉증을 사전에 예측하고 이에 대비할 수 있다.
Related Works
- 과거 리소스 사용량의 통계적 특징을 기반으로 시계열 ML 기법을 사용하여 애플리케이션 리소스 수요를 예측하는 데 중점을 두었다. => 워크로드의 애플리케이션에 초점을 맞추고 예측모델을 선택하여 범용적인 워크로드에 적용하기에는 어려움이 있었다.
- 리소스 사용에 대한 패턴을 발견하고 애플리케이션을 분류하기 위해 워크로드를 모델링한 연구 => 패턴을 식별하기 위해 DL 모델을 학습하는 여러 컨테이너에서 관찰되는 리소스 사용 데이터가 필요하다.
- 워크로드 모델링의 경우 기존에는 작업의 도착이 리소스의 수요를 결정한다고 가정하며, 추세와 계절성을 포함한 시간 의존적 구조를 잘 포착하는 ARMA 및 ARIMA 모델을 사용했다. => DL 학습 중 리소스 사용량이 급증하는 패턴을 포착하기 어렵다.
- 분산 DL 학습에는 네트워킹 리소스가 중요한 부분을 차지하므로, 학습 태스크의 배치를 최적화 하기 위해 다양한 토폴로지 기반 정책을 적용했다. 기존에는 코드에 수동으로 라벨을 지정하거나, 해당 DL 아키텍처의 일부를 식별하도록 했다. => 클라우드 사용자들은 DL 모델이나 특정 구성에 대한 정보를 공유하기 꺼릴 수 있으며, 훈련 세션마다 서로 다른 유형의 데이터와 모델을 사용하므로 사용자 및 실행에 따라 다양한 정책을 적용하기 어렵다.
주요 클라우드 서비스 제공업체의 ML 플랫폼(IBM WML, Amazon Sagemaker, Microsoft Azure ML, Google Cloud AI Platform 등)과 클라우드 네이티브 머신 러닝을 위한 오픈 소스 솔루션(Kubeflow, FfDL 등)에 대한 공개 문서를 보면, 위 플랫폼 대부분이 컨테이너화된 클라우드 네이티브 환경에서 모델 학습 워크로드를 목표로 한다는 것을 알 수 있다.
만약 모든 DL 작업의 최대 사용량만큼 컨테이너에 리소스를 할당하면, 클러스터의 할당 가능한 리소스가 빠르게 고갈될 수 있으며 실제 사용량에 비해 낭비될 수 있다. 따라서 ML 워크로드의 리소스 사용 패턴을 이해하고, 컨테이너를 동적으로 자동 확장함으로써 전반적인 리소스 효율성을 개선하는 것이 중요하다.
Method

- 컨테이너 리소스 사용량(CPU와 메모리) 수집
- Conditional Restricted Boltzmann Machine에서 컨테이너 리소스 사용량 메트릭을 인코딩
- Conditional Restricted Boltzmann Machine: 신경망의 일종으로, 다차원 데이터를 특징 벡터로 인코딩함으로써, 시계열 패턴 분석을 유용하게 한다. 유사한 패턴은 유사한 인코딩 결과값을 가진다.
- k-means 과 같은 클러스터링 방법을 사용하여 유사한 동작을 phase 별로 그룹화한다.
- Memory load - Intensive CPU - Memory unload
- 컨테이너가 어떤 동작을 하는지, 얼마나 많은 리소스가 필요한지, 어떤 순서로 리소스를 소비하는지 분석
- 컨테이너의 전체 수명 주기를 일련의 phase로 표현하며, 이를 트리 또는 그래프로 모델링하여 컨테이너가 수행하는 동작의 유형과 필요한 리소스의 양을 파악한다.
- 동적 리소스 할당 정책: 특정 기간동안 애플리케이션 사용량을 미리 파악하여 리소스 할당 => 리소스 사용량을 예측하는 데 효과적일 수 있지만 갑작스러운 변경이나 예기치 않은 수요 급증을 고려하지 못할 수 있다.
- 적응형 리소스 할당 정책: 이전 시간대를 기준으로 관찰된 수요에 따라 리소스 할당 => 갑작스러운 변화에 더 잘 대응하고 예기치 않은 수요 급증을 더 잘 처리할 수 있지만, 이 접근 방식은 반응형 특성으로 인해 새 리소스를 프로비저닝할 때 지연이 발생
- phase 기반 리소스 할당 정책: 현재 단계에 대해 검색하고, 통계를 사용하여 리소스 할당 => 각 단계의 통계 정보를 기반으로 리소스 프로비저닝을 동적으로 조정할 수 있으며, 컨테이너 요구사항의 약 95%를 충족함
본 논문에서는 실험을 통해 5000개의 DL 애플리케이션의 리소스 요구량이 약 6개의 형태의 클러스터로 나뉨을 관찰할 수 있었다.
Experiments
내부 연구자로부터 제공된 IBM DLaaS 서비스를 제공하는 클러스터에서 DL 모델을 학습하는 컨테이너 리소스 사용량 메트릭 5000개를 사용하고, 테스트 및 모델링 프로세스에는 500개의 컨테이너 트레이스를 사용했다. 평가 결과, 컨테이너를 실행하는 동안 phase를 감지함으로써 리소스 프로비저닝을 동적으로 조정하여, 단순한 적응형 정책보다 더 나은 리소스 활용도를 달성할 수 있는 것으로 나타났다.
- Conditional Restricted Boltzmann Machine: CRBM 모델 훈련은 아키텍쳐와 숨겨진 유닛 수가 미리 정의된 일반 신경망 훈련과 유사하다.
- Clustering Behaviors: 리소스의 사용 패턴을 sliding time window 단위로 클러스터링 함으로써 리소스 사용 패턴에 대한 유사성을 학습할 수 있다. 단순성을 위해 k-means를 사용하며, 본 논문에서는 k=5가 최적임을 확인했다.
- Phase Information: 각 execution에 대해 phase sequence를 생성하여, phase별로 리소스 사용의 추세와 다양한 변동성을 관찰했다. => 특히, 워밍업 단계의 리소스 사용량은 변동성이 높아 충분한 메트릭 데이터가 확보될 때까지 매커니즘이 패턴을 식별하기 어렵다.
- CPU와 메모리를 안정적으로 사용하는 단계
- 메모리 로딩 및 언로딩 단계
- 워밍 업 단계
- CPU 스파이크와 함께, 메모리 사용량이 점진적으로 증가하는 단계
- 메모리를 집중적으로 사용하지만, CPU 사용량이 가변적인 단계
4.2 Phase 기반 리소스 할당
- ground.truth: 모든 컨테이너의 실제 리소스 사용량
- current.step.max 및 current.step.rules(maximum 및 stat.rulesfor current.step): 오라클이 향후 기간의 리소스 사용량을 미리 알고 있는 경우, 적용할 두가지 리소스 할당 정책 => 선험적 지식에 의존하기 때문에 비실용적
- current.step.max: 향후 최대 사용량에 따라 프로비저닝
- current.step.rules: 평균 제곱 표준편차를 더한 값에 따라 프로비저닝
- prev.step.max 및 prev.step.rules: 이전 주기에서 관찰된 정보(사후 지식)을 사용하여 다음 주기를 프로비저닝 하며, 현재 패턴이 다음 자동 확장 주기에서도 계속될 것으로 예상한다.
- phase.rule: 프로비저닝 주기 직전의 단계를 감지하고, 해당 단계의 리소스 사용량 정보를 얻은 후, 다음 주기에 그에 따라 리소스를 프로비저닝
4.3 동작 예측 가능성
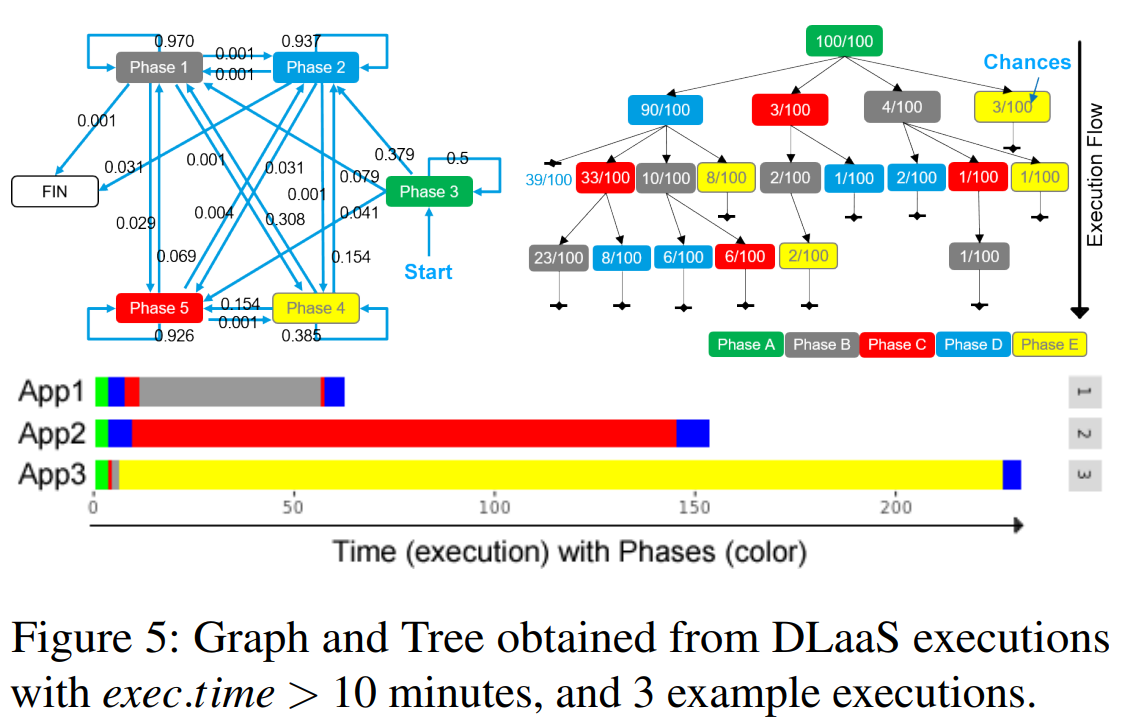
아래 그림과 같이, 확률 그래프에서 위상 시퀀스를 표현하기 위해 각각의 고유한 위상을 노드로, 위상 간의 전환을 전환 확률을 나타내는 속성을 가진 방향이 지정된 에지로 모델링한다.
Discussion
GPU도 사용하는 딥러닝 태스크겠지..? GPU도 함께 리소스 클러스터링을 하면 좋을 것 같다.
컨테이너에서 트레이스를 뽑는 방법에 대해 조금 더 조사해봐야겠다.
- https://github.com/amrabed/strace-docker
- Why strace doesn't work in Docker
'논문을 읽자' 카테고리의 다른 글
| Mesos: A platform for fine-grained resource sharing in the data center (0) | 2023.04.14 |
|---|---|
| An analysis of Facebook photo caching (0) | 2023.04.13 |
| Gpipe: Efficient training of giant neural networks using pipeline parallelism (0) | 2023.03.22 |
| Joint Task Scheduling and Containerizing for Efficient Edge Computing (0) | 2023.03.20 |
| An Empirical Study of Memory Sharing in Virtual Machines (0) | 2022.05.18 |