💡 요약
- abstract: 다양한 워크로드에 대처할 수 있는 유연성을 높이기 위해 컨테이너 기반 애플리케이션의 수평 및 수직 탄력성을 제어하기 위한 강화 학습(RL) 솔루션을 제안한 연구
- introduction: 컨테이너 기반 애플리케이션을 확장할 때 효율성을 최적화하기 위해 확장 정책이 유연하고 적응적으로 동작해야 한다는 과제가 있다.
- related works: 기존에는 수직적 탄력성과 수평적 탄력성을 결합한 연구가 소수만 이루어졌다. 또한 기존에는 탄력성을 구동하기 위해 임계값을 사용했다.
- method: 컨테이너 기반 애플리케이션의 탄력성을 제어하기 위해 모델 없는 솔루션과 모델 기반 솔루션을 포함한 다양한 RL 정책을 사용할 것을 제안했다.
- experiment: 시뮬레이션과 프로토타입 기반 실험을 통해 다양한 RL 접근 방식을 평가했다. 결과적으로 결과는 모델 기반 접근 방식이 사용자 정의 배포 목표에 따라 최상의 적응 정책을 성공적으로 학습할 수 있음을 보여주었다.
- conclusion & discussion: 모델 기반 RL 접근법을 사용하여 컨테이너 기반 애플리케이션의 탄력성을 제어하기 위한 RL 알고리즘을 설계했으며, 제안된 정책을 컨테이너 오케스트레이션 도구인 Docker Swarm에 자체 적응 기능을 도입하는 확장 기능인 Elastic Docker Swarm을 적용했다.
Introduction
컨테이너를 사용하면 수평 및 수직 확장을 통해 애플리케이션 배포를 쉽게 조정할 수 있다.
- 수평적 탄력성: 애플리케이션 인스턴스(컨테이너) 수를 늘린다. => 컨테이너 구성을 변경하므로 새 구성을 적용하는 데 필요한 시간 동안 전체 애플리케이션을 사용할 수 없게 됨(다운타임 발생)
- 수직적 탄력성: 애플리케이션 인스턴스에 할당된 컴퓨팅 리소스의 양을 늘리거나 줄인다 => 일반적으로 추가적인 다운타임이 발생하지는 않지만, Docker Swarm에서 스케일 아웃을 수행하면 적응 비용이 발생
- Docker Swarm에서 스케일 아웃을 수행하면 적응 비용이 발생하는 이유?
- Docker Swarm의 트래픽 라우팅 전략 때문이다. 새로운 인스턴스가 실행되기 전에도 Docker Swarm은 애플리케이션 요청을 새로 추가된 인스턴스로 보내려고 시도하는데, 이때 해당 인스턴스가 아직 실행 중이지 않으면 응답하지 못할 가능성이 있다. 따라서 이전 버전의 컨테이너를 사용하여 요청을 처리하기 위해 일시적으로 다운 타임이 발생할 수 있다.
이러한 컨테이너의 특성을 사용하여 런타임에 애플리케이션 배포를 적절히 조정하여 성능을 유지할 수 있다
Related Work
(1) 탄력성 조치를 적용하는 범위에 따른 연구
- 인프라 수준: 인프라 수준에서 탄력성 컨트롤러는 일반적으로 VM을 획득하고 해제하여 컴퓨팅 리소스의 수를 변경한다.
- 애플리케이션 수준: 애플리케이션 수준에서 컨트롤러는 애플리케이션에 직접 할당된 컴퓨팅 리소스를 조정한다(ex. 병렬 처리 수준 변경) 또는, 탄력성 컨트롤러를 애플리케이션 코드 내에 통합하는 임베디드 탄력성을 사용하는데, 이 경우 애플리케이션 자체에서 적응을 조정하는 메커니즘과 정책도 구현해야 한다.
외부 컨트롤러를 사용하여 컴퓨팅 리소스를 조정하는 방식은 소프트웨어 모듈성과 유연성을 향상시키기 때문에, 본 논문에서는 분산 컨테이너화된 애플리케이션의 수평 및 수직 탄력성을 관리하기 위한 외부 컨트롤러를 제안하고 있다.
(2) 탄력성 조치 적용의 목표에 따른 연구
- 애플리케이션 성능 개선: 로드 밸런싱 및 리소스 활용
- 에너지 효율성
- 배포 비용 절감
대부분의 연구는 단일 수준의 배포 목표를 고려하기 때문에, 본 연구 또한 단일 수준의 배포에 초점을 맞추고 컨테이너 수준에서 탄력성을 활용한다.
(3) 배포를 조정하는 데 사용되는 작업 및 방법론에 따른 연구
- 수학적 프로그래밍 접근법: 컨테이너의 초기 배치와 런타임 배포 적응 비용(배포 재구성으로 인한 성능 저하) 을 고려하여 배포를 조정함
- 휴리스틱: 임계값 기반 및 RL 기반 솔루션
- 임계값 기반: 클라우드 인프라 레이어뿐만 아니라 런타임에 컨테이너를 확장하는 데 가장 많이 사용되는 접근 방식으로, 기존의 오케스트레이션 프레임워크(Kubernetes, Docker Swarm, Amazon ECS 등)는 일반적으로 일부 로드 메트릭(ex. CPU 사용률)에 기반한 최선의 임계값 기반 정책에 의존하고 있다. => 효과적인 임계값 기반 정책을 사용하려면 임계값 매개변수를 올바르게 설정해야 하며, 이를 위해서는 애플리케이션 리소스 소비에 대한 어느 정도 지식이 필요하며, 수직 확장에 대한 연구는 별로 이루어지지 못했다. = 매우 번거롭다
- RL 기반 솔루션: Q-Learning 을 이용하여 가상 머신 할당 및 프로비저닝을 위한 정책 수립 등에 적용되어왔다. => 모델이 없는 솔루션이기 때문에 수렴이 느리다는 문제가 있다.
본 논문에서는 빠르게 학습시키기 위해 시스템 지식을 활용하는 새로운 모델 기반 RL 정책을 제안하며, 애플리케이션 배포를 런타임에 적응하기 위해 특히 수직 및 수평 탄력성을 공동으로 활용할 때의 이점을 조사한다.
Background
A. Docker Swarm
Docker는 컨테이너화된 애플리케이션을 생성하고 관리하기 위한 플랫폼으로, Docker를 사용하여 특정 리소스 할당량을 가진 컨테이너를 구성할 수 있고, 런타임에 업데이트하여 수직적 탄력성을 활성화할 수 있다.
Docker Swarm은 master-worker 패턴에 따라 여러 노드에서 컨테이너 실행을 단순화하는 클러스터링 시스템이다.
Method
- 강화학습(Reinforcement Learning): 런타임에 컨테이너 기반 애플리케이션에 대한 최적의 적응 전략을 학습한다.
- 에이전트(agent): 개별적인 시간 단위로 애플리케이션과 상호 작용하고, 애플리케이션 상태(state)를 관찰하며 예상되는 장기 비용을 최소화하기 위한 작업을 수행한다.
- 상태(state): 컨테이너 수(=인스턴스 수), CPU 사용률, 각 컨테이너에 할당된 CPU 점유율의 튜플로 정의한다.
- cost function: 애플리케이션 상태가 s에서 s'로 전환될 때 작업 a를 수행하는 데 드는 비용을 나타낸다. => 비용 최소화는 일반적으로 RL 에이전트의 제약 조건 또는 부차적인 목표이다.
- 본 논문에서는 적응 비용(컨테이너 추가 또는 제거와 같은 작업에 대한 비용), 성능 비용(애플리케이션 응답 시간 제한을 초과할 때마다), 리소스 비용(애플리케이션 인스턴스 수 및 할당된 CPU 점유율에 비례) 을 단일 가중치 비용 함수로 결합하여 사용한다.
- solution1) Q-learning: 강화 학습에서 샘플링 평균을 통해 최적의 Q-function을 추정하는 데 사용되는 모델 없는 알고리즘이다. 본 논문에서는 greedy 정책으로 기반으로 작업을 선택하지만, 낮은 확률로 차선의 작업도 탐색한다. 각 시간 슬롯이 끝날 때마다 학습 속도 매개변수와 향후 보상의 중요성을 결정하는 discount factor 를 사용하여 관찰된 state-action 쌍에 대한 Q값이 업데이트됨
- Q-function=Q(s,a): 상태 s에서 액션 a를 실행 시 예상되는 장기 비용을 나타낸다. 컨테이너 확장에 대한 결정을 내리는 데 사용되며, 실제 발생한 비용을 관찰하여 시간이 지남에 따라 업데이트된다. => 높은 보상을 받을 가능성이 가장 높은 행동을 결정할 때 사용
- Dyna-Q: 애플리케이션과 환경 간의 상호 작용을 시뮬레이션하여 학습 프로세스의 속도를 높이는 강화 학습 알고리즘이다. 런타임에 Dyna-Q는 애플리케이션 상태를 관찰하고 Q-러닝과 유사하게 Q(s, a)의 추정치를 사용하여 적응 action을 선택한 뒤, 탐색된 (s, a)에 대한 다음 상태 s'와 비용 c를 저장하여 런타임에 시스템 모델인 모델(s, a)을 업데이트한다. 모델은 Q-함수를 업데이트하는 데 사용된다.
- solution2) 모델 기반 강화 학습: 본 논문에서는 경험적 데이터를 사용하여 시스템 모델의 전이 확률과 비용 함수를 추정하는 전체 백업 모델 기반 강화학습 접근 방식을 적용했다.
- 전체 백업 접근법: 추정 가능한 시스템 모델에 의존하며, 벨만 방정식을 사용하여 Q 함수 계산한다.
- 샘플 값을 사용하여 비용 추정치를 업데이트하는 동안, 특정 속성을 적용하여 컨테이너 수가 감소하거나 CPU 사용률이 증가하거나 CPU 점유율이 감소할 때 Rmax 위반으로 인한 예상 비용이 낮아지지 않도록 한다
본 논문에서는 Docker Swarm에 모니터링/분석/계획/실행 제어 루프를 적용함으로써 Elastic Docker Swarm(EDS) 아키텍쳐로 확장했다. EDS는 RL 정책을 사용하여 애플리케이션 배포 및 재구성 시기/방법을 결정하며, Docker Swarm API를 활용한다.
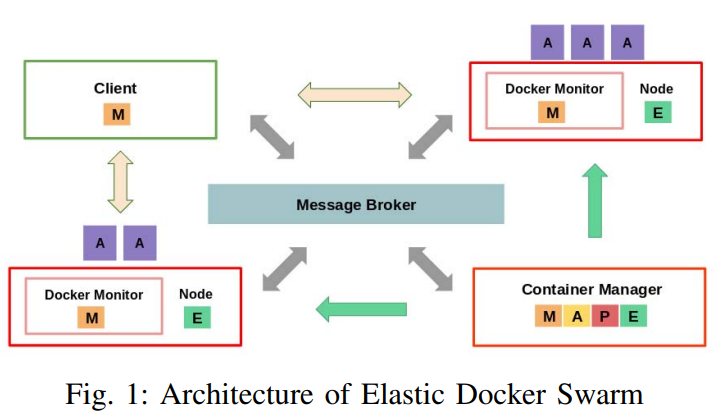
- Docker Monitor: 각 노드에서 실행되며, 노드에서 실행 중인 컨테이너의 CPU 사용률에 대한 정보를 메시지 브로커(Apache Kafka)에 주기적으로 게시
- Container Manager: 메시지 브로커를 통해 모니터링 정보를 수신하고, RL 에이전트를 사용하여 분석 및 계획 단계를 수행
- RL 에이전트가 애플리케이션 상태를 판단하고 Q-function 을 업데이트한다.
- RL 에이전트를 사용하여 수행해야 할 확장 작업을 식별한다.
- 애플리케이션 배포를 조정하기 위해 EDS는 Docker Swarm API를 활용한다.
Experiment
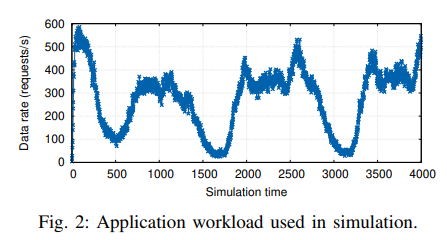
- 시뮬레이션 실험: 애플리케이션이 무작위적이고 독립적인 요청(M)을 수신하고, 서버가 요청을 처리하는 데 걸리는 시간(D)은 고정되어 있으며 변하지 않으며, 서버 수는 시간 단계 i에서 사용된 컨테이너 수(ki)와 같다고 가정한다.
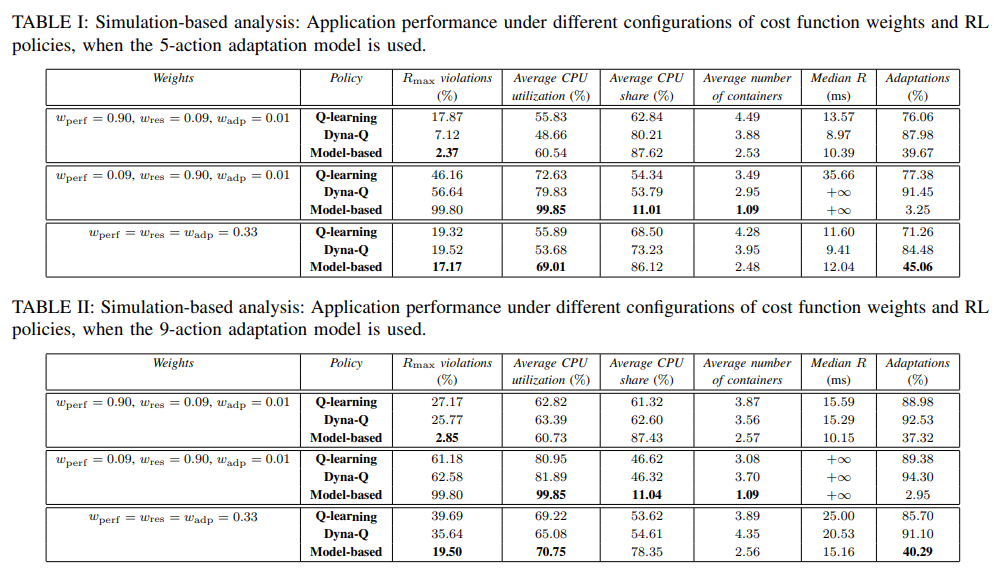
- 최대 응답 시간(Rmax) 위반을 방지하는 데 중점을 둔 경우, 모델 기반 솔루션은 응답 시간 위반이 2.85%에 불과하여 모델 없는 접근 방식보다 성능이 더 우수했다. 또한, 리소스 중점 시나리오에서는 모델 기반 솔루션이 애플리케이션 응답 시간이 길어지는 대신 리소스 활용도를 성공적으로 개선했다.
- 5-액션 모델은 학습 작업을 간소화하고 모든 RL 정책에 대한 Rmax 위반을 줄이는 반면, 9-액션 모델은 학습 프로세스를 느리게 했다.
=> 모델 기반 접근 방식이 더 우수하다 = 시스템에 대한 사전 지식이 매우 중요하다
*모델 기반 접근 방식: 시스템의 동적인 특성을 사전에 알고 있는 경우, 이를 활용하여 강화학습 모델이 더욱 효과적으로 학습할 수 있도록 하는 방법
- 프로토타입 기반 실험: Amazon EC2 인스턴스로 구성된 클러스터에서 EDS로 제안된 정책을 사용하여 실제 환경에서 강화 학습(RL) 알고리즘을 평가함

- 목표 응답 시간 위반을 줄이고 워크로드 변동에 적응하는 측면에서 모델 기반 정책이 Q-러닝보다 우수한 것으로 나타났다.
- Q러닝은 모델 기반 솔루션과 유사한 솔루션을 찾지만 애플리케이션 배포를 더 자주 변경했다.
- 모델 기반 솔루션은 Q-러닝보다 Rmax 위반 횟수를 줄이고 애플리케이션 배포를 덜 변경하여 애플리케이션 가용성을 높이는 것으로 나타났다.
- 모델 기반 접근 방식은 수직 확장보다 수평 확장을 선호하는 것으로 관찰되었다.
- Elastic 배포 시스템(EDS)의 적응 비용 정의에 따라 컨테이너 구성 변경(수직 확장)이 새 컨테이너 추가(수평 확장)보다 비용이 더 많이 들기 때문
=> RL 기반 접근 방식이 갑작스러운 워크로드 변화에 적응할 수 있어서 더 좋지만, 모델 기반 솔루션은 모든 상태, 동작, 다음 상태를 반복해야 하므로 계산이 많이 필요하며, 사용 가능한 동작과 전환 확률이 제한되어 있기 때문에 복잡성이 크다