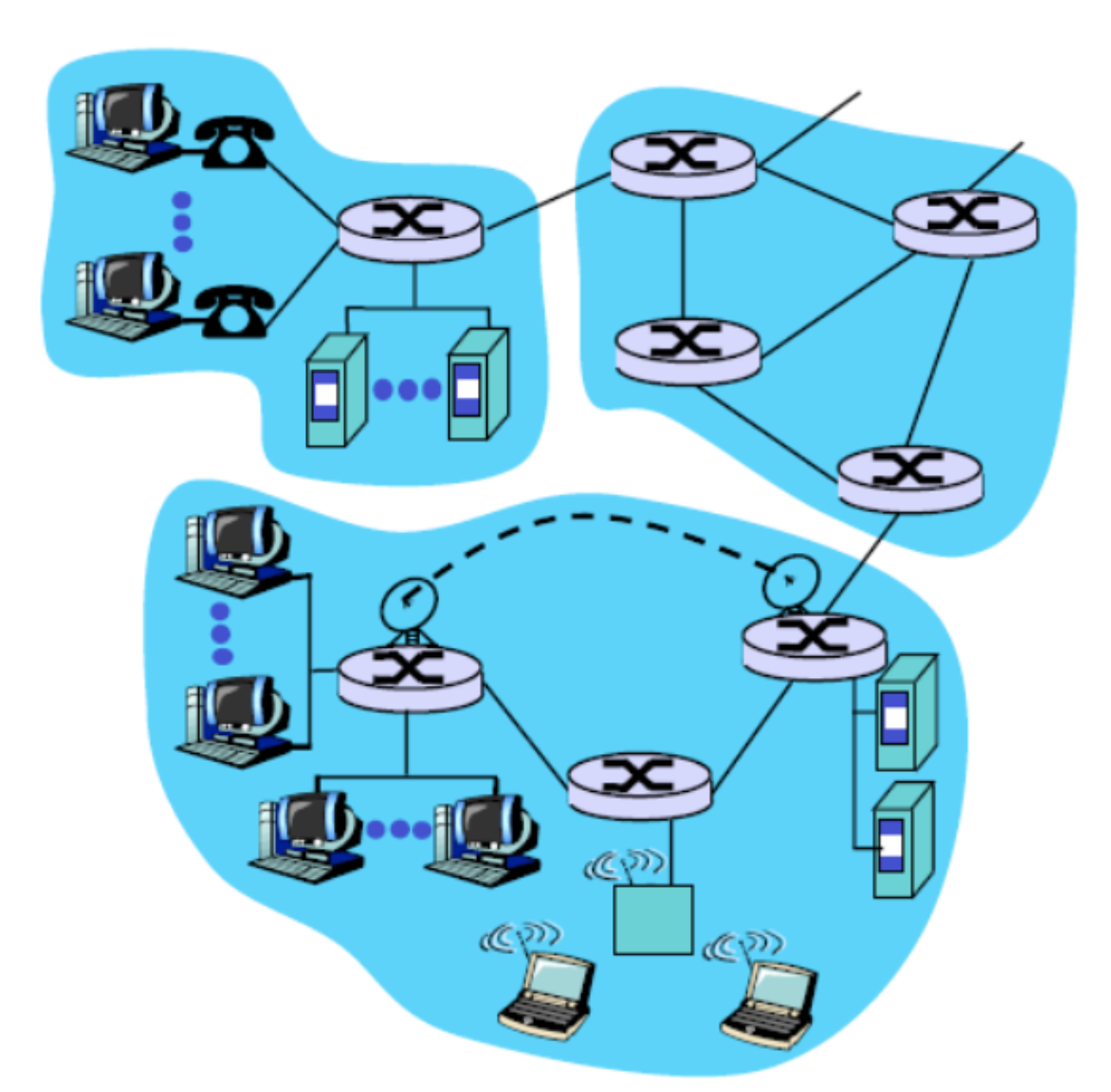
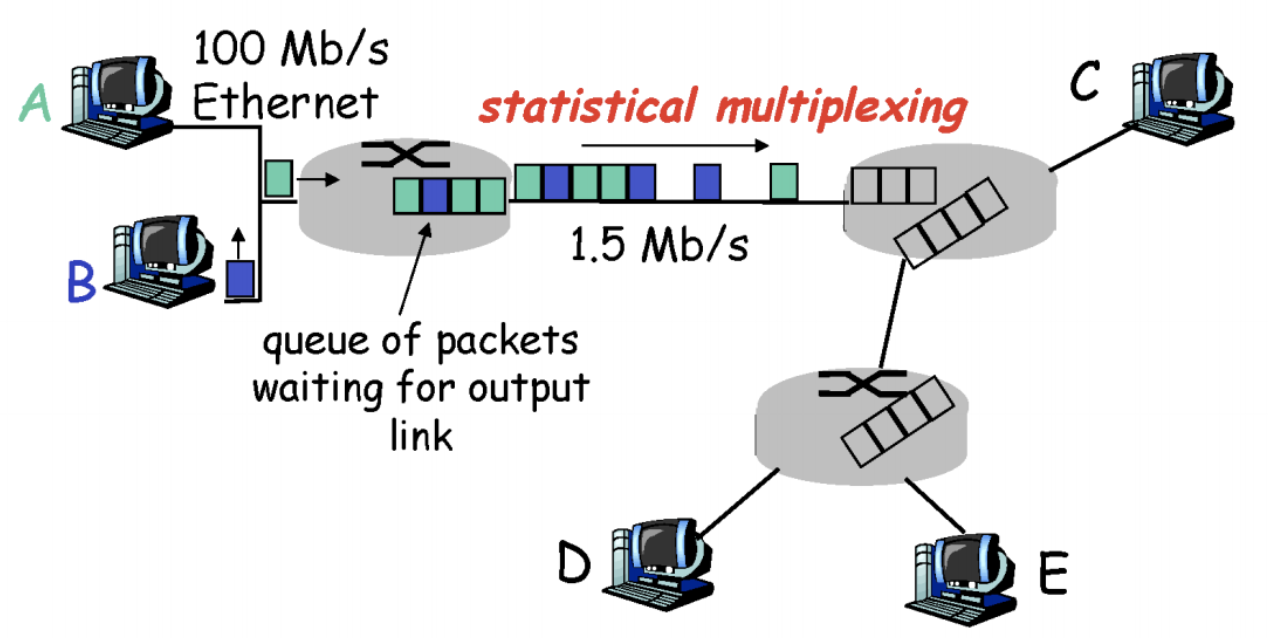
end point에는 7 layer가 존재하지만, 라우터에는 network layer까지만 존재한다.
하위 계층에서 상위 계층에게 서비스를 제공하는 것이다.
Application layer
ex) chrome 브라우저 등: user program
client process와 server process의 의사 소통(다른 컴퓨터 상에 존재하는 프로세스 간 통신)
⇒ os에서 이를 위해 `소켓`이라는 인터페이스를 만들어 놓음.
- 서버
- always-on host
- 고정된 ip 주소
- data centers for scaling
- 클라이언트
- communication with server
- may be intermittently connected
- may have dynamic ip addresses
- do not communicate directly with each other
소켓의 주소 = ip address + port
- ip 주소: 인터넷 상의 컴퓨터 주소
- port: 같은 인터넷 상의 특정 컴퓨터의 소켓
왜 웹 서버들이 동일한 포트를 쓸까? (80)
www.google.com → DNS → ip 주소로 변환(default port:80)
서버는 24시간 켜져 있어야 하고, 주소가 일정해야 한다. 주소를 해석해 주는 것이 DNS인데,
포트 넘버까지 다른 것 보다 같도록 정하는 것이 더 효율적이기 때문이다.
즉, DNS에서 포트 넘버까지 다 만들어 주어야 하기 때문이다.
transport 계층에서 이러한 서비스가 제공되면 좋겠다는 희망 사항
-
data integrity: 보낸 데이터가 유실되지 않고 온전하게 목적지까지 도착했으면 좋겠다. ⇒ transport layer(tcp)에서 제
-
throughput: 보낸 데이터가 최소 ~~ bps, 전달 용량에 대한 희망 사항
-
timing: 보낸 데이터가 ~~ 시간 안에 도착 했으면 좋겠다.
-
security: 내가 보낸 데이터가 안전 했으면 좋겠다.
⇒ 나머지는 제공x
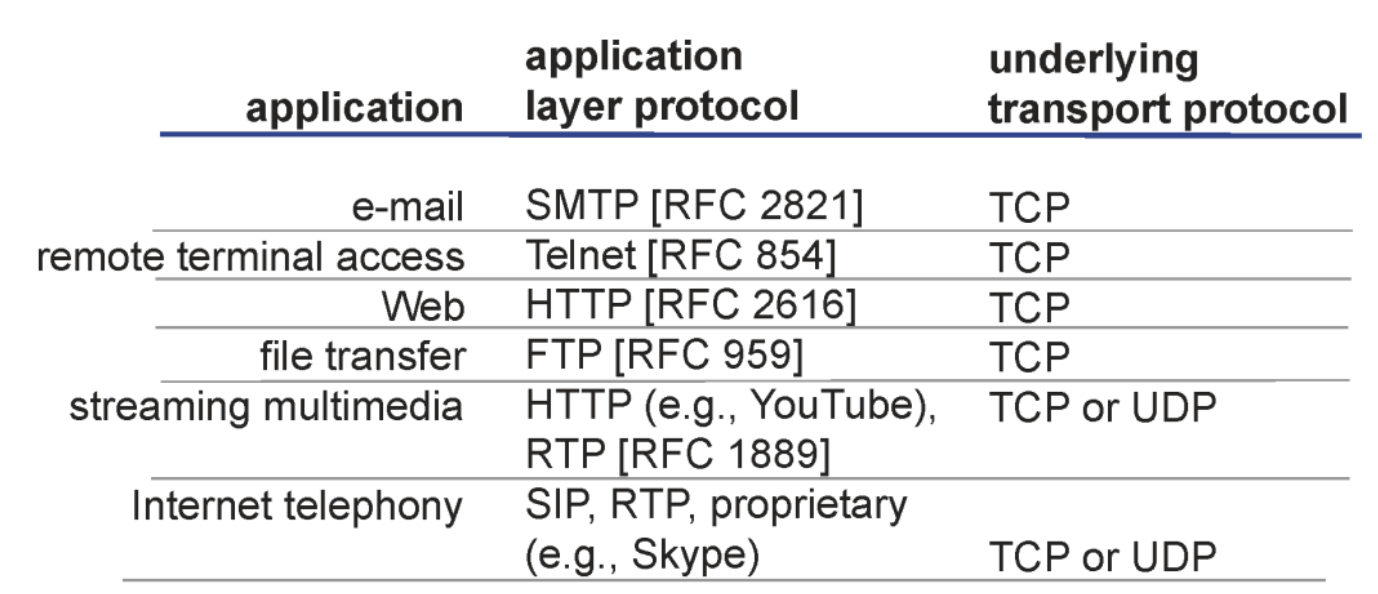
HTTP
hypertext transfer protocol
hypertext: text 인데 중간 중간에 다른 텍스트를 가리키는 링크가 존재
- tcp 프로토콜을 사용
- request, response 이전에 connection을 생성한다.
- stateless
- HTTP는 단순해서 요청 들어오면 응답을 보내주고 끝이다. 상대방의 상태 등을 기억하지 않는다.
1. non-persistent HTTP: connection 맺은 뒤 통신 완료 후 connection을 끊는 경우

2. persistent HTTP: connection 맺은 뒤 통신 완료 후 connection을 끊지 않고 재 사용하는 경우
- 실제로는 Pipeline과 persistent HTTP가 결합된 방식을 사용
소켓
client process와 server process간의 통신
os가 제공해주는 api의 일종으로, os에는 application layer의 하위 계층들이 구현되어있다. 즉, application layer와 os 사이를 이어주는 transport layer 인터페이스를 사용해 주어야 한다. os에는 transport layer를 tcp와 udp, 2가지 방식을 구현한다. application layer는 이 구현되어 있는 소켓 중에 tcp, udp 둘 중 하나의 방식을 선택한다.
1. tcp socket = socket stream

- 신뢰성 제공 및 순서대로 전송(연결성)
- bidirectional
- tcp socket function

- int socket(int domain, int type, int protocol)
- type: udp인지 tcp인지
- 리턴 값은 생성된 소켓의 id
- int bind(int sockfd, struct socketaddr* myaddr, int addrlen)
- 생성한 소켓의 id를 사용해서 특정 포트에 바인딩 하겠다.
- 클라이언트에서 바인드 함수를 사용하지 않는 이유는, 바인드 함수는 특정 소켓을 어떤 포트에 바인드 해주는 개념인데, 클라이언트는 특정 포트에 바인드 할 필요가 없기 때문이다. (아무 포트나 쓰면 됨)
- int listen(int sockfd, int backlog)
- 방금 생성한 소켓을 listen 용도로 사용할 것이며, 동시에 request가 들어올 경우, 최대 n개까지 큐에 담아 놓고 순서대로 처리하겠다.
- int accept(int sockfd, struct sockaddr* cliaddr, int* addrlen)
- 다 준비 되었으니 클라이언트로부터 연락을 기다리겠다.
- 이 함수는 실행 되면 block되어 있다가 클라이언트로부터 요청이 들어오면 리턴 된다. 리턴이 될 때, 두 번째 파라미터에 클라이언트의 ip와 port 주소가 저장된다. (=서버에 클라이언트의 주소가 저장된다)
2. udp socket = socket datagram

- 신뢰성을 제공하지 않으며 no order guarantees (비연결성)
- no notion of connection: app indicates destination for each packet
- can send or receive
- udp socket function
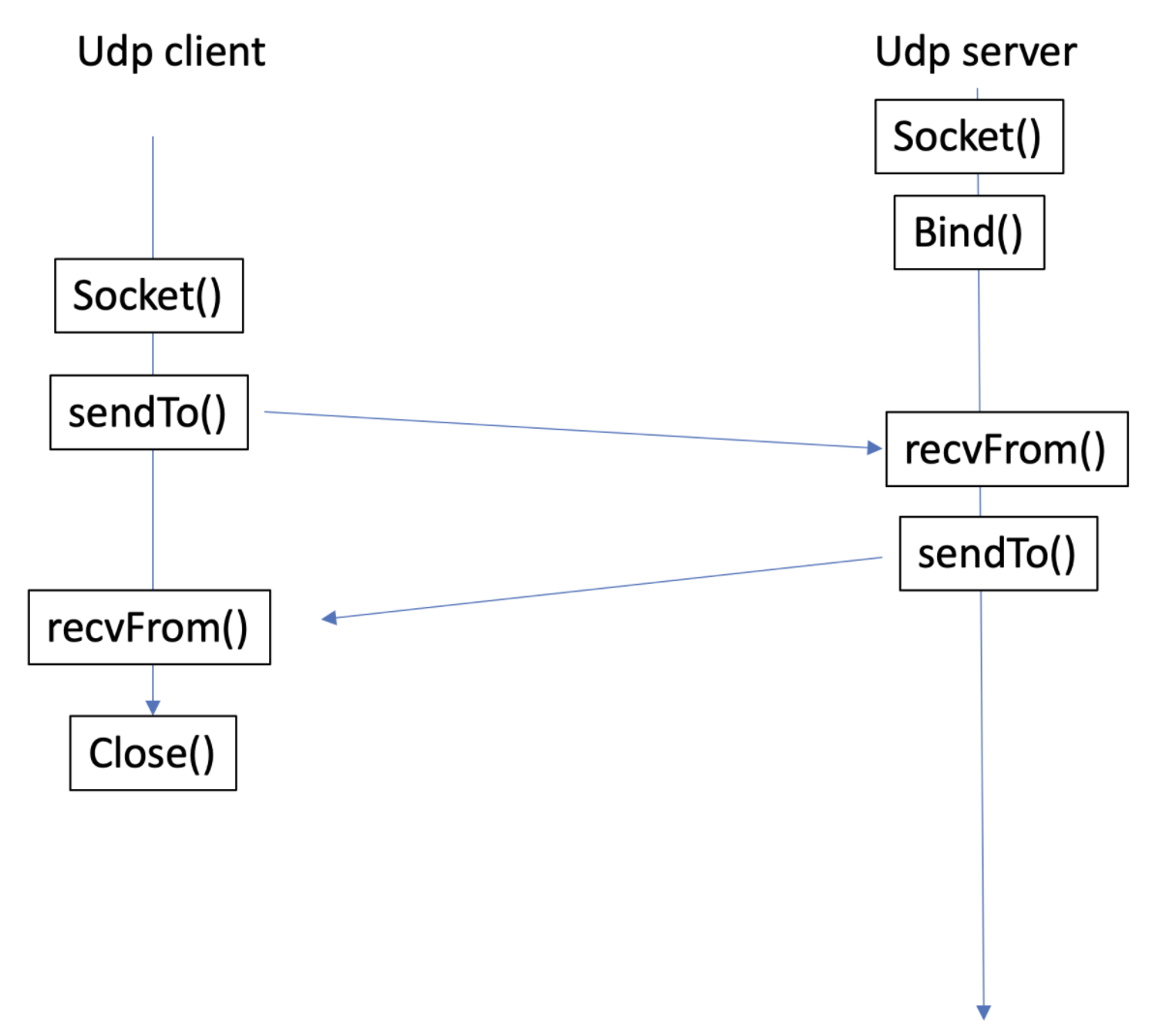
- int sendto(int sockfd, char* buf, size_t nbytes, int flags, struct sockaddr* destaddr, int addrlen)
- int close(int sockfd)
- 데이터 교환이 끝난 후, 최종적으로 close해 주어야 다른 프로세스가 사용할 수 있다.
소켓의 경우, 프로그램이 에러 등이 나서 cntrl+c/z 등을 눌러 멈추면 프로세스는 죽지만, 그 프로세스에서 바인드 한 포트는 한동안 release 되지 않고 가지고 있다. 그래서 같은 포트를 쓸 수 없는 경우가 있다.
아래 시스템 콜을 쓰면 cntrl+c 등을 눌러줄 때 소켓 관련 자료 구조들이 다 release된다.
#include<signal.h>
void cleanExit(){exit(0);}
in socket code:
signal(SIGTERM, cleanExit);
signal(SIGINT, cleanExit);
presentation layer
운영체계의 한 부분으로 입력, 출력되는 데이터를 하나의 표현 형태로 변환하는 계층으로 필요한 번역을 수행한다.
즉 두 장치가 일관되게 전송 데이터를 서로 이해할 수 있도록 하는 역할이다.
해당 계층은 클라이언트 구현중에 데이터 교환 포맷을 맞추려고 내가 직접 수행해 준 적이 종종 있던거 같다.
데이터 표현이 상이한 응용 프로세스의 독립성을 제공하고, 암호화 한다.
표현 계층(Presentation layer)은 코드 간의 번역을 담당하여 사용자 시스템에서 데이터의 형식상 차이를 다루는 부담을 응용 계층으로부터 덜어 준다. MIME 인코딩이나 암호화 등의 동작이 이 계층에서 이루어진다.
예를 들면, EBCDIC로 인코딩된 문서 파일을 ASCII로 인코딩된 파일로 바꿔 주는 것,
해당 데이터가 TEXT인지, 그림인지, GIF인지 JPG인지의 구분 등이 표현 계층의 몫이다.
- 사용자의 명령어를 완성 및 결과 표현. 포장/압축/암호화
+ 보안 규약 정의
TLS/SSL : 암호화 프로토콜
- Transport layer Secure:
- Secure Socket layer:
ex) HTTP/HTTPS -> TLS/SSL 기술이 사용 된다.
- private key & foreign key 작동 원리
session layer
SSH/TLS 제공
응용 간의 제어 역할을 수행하는 통신 세션을 구성하는 계층으로 통신장치 간의 상호작용을 설정하고 유지하며, 동기화하여 사용자 간의 세션(포트)연결이 유효한지 확인하고 설정하는 역할을 한다.
데이터가 통신하기 위한 논리적인 연결을 담당하는데, 해당 논리적인 연결을 세션이라 하는거 같다. 근데 세션이 정확히 어떤건지 이해가 안된다. 세션에 대한 [https://88240.tistory.com/190] 여기의 설명이 좋은거 같다.
데이터가 통신하기 위한 논리적인 연결을 말한다. 통신을 하기위한 대문이라고 보면 된다.
하지만 4계층에서도 연결을 맺고 종료할 수 있기 때문에 우리가 어느 계층에서 통신이 끊어 졌나 판단하기는 한계가 있다.
그러므로 세션 계층은 4 계층과 무관하게 응용 프로그램 관점에서 봐야 한다.
세션 설정, 유지, 종료, 전송 중단시 복구 등의 기능이 있다.
세션 계층(Session layer)은 양 끝단의 응용 프로세스가 통신을 관리하기 위한 방법을 제공한다.
동시 송수신 방식(duplex), 반이중 방식(half-duplex), 전이중 방식(Full Duplex)의 통신과 함께, 체크 포인팅과 유휴, 종료, 다시 시작 과정 등을 수행한다.
이 계층은 TCP/IP 세션을 만들고 없애는 책임을 진다.
통신하는 사용자들을 동기화하고 오류복구 명령들을 일괄적으로 다룬다.
통신을 하기 위한 세션을 확립/ 유지 /중단 (운영체제가 해줌)
소켓을 만드는 layer
↔ 쿠키: 중요 정보 x, 하이 재킹 당하기 쉽기 때문에
'CS > Network' 카테고리의 다른 글
| HTTP/1.1 와 HTTP/2 (Feat TCP, UDP, TLS) (0) | 2021.02.08 |
|---|---|
| network edge/core와 데이터를 전달하는 방식 (0) | 2021.01.18 |