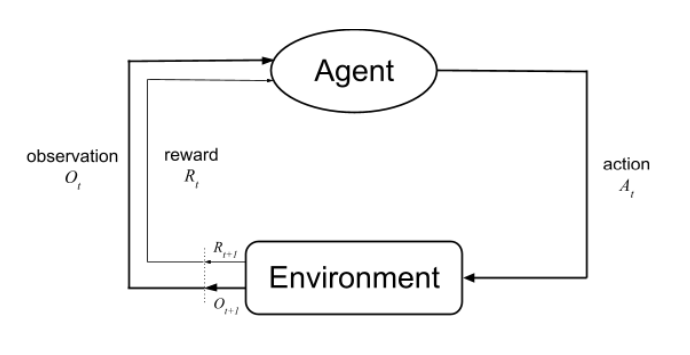
Modified Policy Iteration: policy evaluation 단계에서 꼭 v_π가 수렴할 필요 없이 early-stopping도 가능하고, batch 단위로 업데이트도 가능함
Value Iteration: policy iteration과 달리 explicit한 policy가 없다
v1 초기화
Bellman Optimality backup(synchronous) 적용
2 반복
Principle of Optimality: Optimal Policy는 두가지 요소로 나뉠 수 있다
첫 action A가 optimal하다 = A*
그 action을 해서 어떤 State s'에 도달하면 거기서부터 또 optimal policy를 따라간다
즉, Bellman Optimality Equation에 따르면 v*(s) =max_a(R_s^a + r\sum_{s' from State} P_{ss'}^a v*(s'))
즉 상태 s의 optimal value를 알기 위해서는 다음 상태 s'까지 진행해봐야 상태 s의 value가 최적인지/아닌지 판단이 가능하다
S0 -> S1 -> ... ->St(terminate) 인 시퀀스가 있을 때, V(St)를 알아야 비로소 V0(S0)을 알 수 있다.
길찾기 문제
예를 들어 길찾기 문제에서 goal 근처의 value는 goal을 이용하여 계산하게 된다.
*하지만 DP에서 모든 상태에 대한 업데이트를 동시에 진행해야하므로, goal의 optimal value가 goal과 가까운 곳부터 퍼져나가면서 다른 위치의 칸들이 optimal vlaue를 계산할 수 있을 때 까지 여러번 반복된다. 이를 value iteration이라고 한다.
알고리즘이 State value function에 의존하고 있으면 한 iteration마다 complexity는 O(mn^2)
알고리즘이 State action value function에 의존하고 있으면 한 iteration마다 complexity는 O(m^2n^2)
위의 경우 모두 synchronous backup을 말하고 있는데, asynchronous backup을 하는 경우 computation을 줄일 수 있다.
(State 들이 비슷한 확률로 다양하게 뽑힌다면 수렴도 보장된다.)
asynchronous backup을 할 땐 state에 우선순위를 두고 하면 빠르게 수렴될 수 있는데, Bellman error가 클수록 우선순위를 높게 설정한다. asynchronous backup을 하는 경우에는 계산적 이득 뿐만 아니라 실제로 구현 시 v array를 하나만 사용해도 된다.
State Space가 넓고 Agent가 도달하는 State가 한정적인 경우에는, Agent를 움직이게 해 놓고, Agent가 방문한 State를 먼저 업데이트하는 Real-Time Dynamic Programming 기법이 효과적이다.
사실 DP는 full-width backup으로, s에서 갈 수 있는 모든 s'를 이용하여 value를 업데이트 하게 되기 때문에 medium-sized problem에는 효과적이지만, 큰 문제에서는 비효율적이다. (state 수가 늘어날수록 계산량이 exponential하게 증가하므로)
따라서 큰 문제에서는 sample backup을 사용한다.
state가 많아져도 고정된 비용(sample 갯수)로 backup (=dimension이 커질 때 발생하는 문제를 sampling을 통해 해결)
강화학습에서는 오로지 보상에만 초점을 맞춘다. 미리 정해진 정답값을제공하는 기존 ML과 달리, 강화학습은 reward를 보고 가장 최적의 솔루션을 찾아내는 데 중점을 둔다.
즉, 강화학습의 목적은 최대 보상을 얻기 위해 특정 행동을 지시하는 것이 아니라, RL이 받고 있는 보상을 최적화 하는 방법을 알아내는 것이다. 이런 접근 방식은 인간은 결국 sub-optimal한 정답값에 도달하게된다는 생각에서 출발한다. 따라서 복잡한 시나리오에서 사람이 답을 알려주며 학습을 하게 되면 결국 sub-optimal한 정답값을 학습하게 되기 때문에 차선책에 만족하는 경우가 많다. 강화학습은 알고리즘이 보상을 기반으로 자유롭게 탐색하고 최적화 하도록 함으로써 복잡한 시나리오에서 자율적으로 global optimal을 찾아나갈 수 있다.
핵심적인 차이점은 강화학습은 순서가 중요한 sequential data를 사용한다는 점이다. 고정된 예시가 아니라 경험을 통해 학습함으로써, 시간이 지남에 따라 행동에 대한 보상이 누적되며 agent가 따르는 policy가 형성된다.
RangL: A Reinforcement Learning Competition Platform
강화학습의 목표는 누적된 총 Reward를 최대화하는 것이다.
Reward: 단일 스칼라 숫자값, 시간 t 동안 agent가 얼마나 잘 수행했는지 나타내는 지표
Agent: Reward의 축적된 합을 최대화하는 것이 목적인 것
강화학습을 수행하기 위해 Reward를 단일 숫자 값으로 표현할 수 있어야 하며, reward가 스칼라 값 하나로 치환 불가능할 정도로 복잡한 경우는 강화학습이 적합하지 않을 수 있다.
Agent는 다음 Action을 결정하는 데 State를 기반으로 의사 결정을 내린다.
State: 다음에 무슨 행동을 할지 결정하기 위한 모든 정보들
Environment State: environment가 observation(행동에 따라 상황이 어떻게 바뀌었는지)과 reward를 계산할 때 쓴 모든 정보(Agent는 알 수 없는 정보) = Markov
Agent State: 다음 action을 하기 위해 필요한 모든 정보 (reward와 observation 값/가공값)
Markov State: 어떤 tate가 Markov한지/아닌지
Markov하다 = 미래는 전체 히스토리가 아닌 현재 상태에만 의존한다. t 시간에 대한 결정을 할 때 바로 이전 (t-1)에만 의존하여 결정하는 것, 즉 (t+1) 미래의 시간은 현재 t와 관련 있으며, 과거 (t-1)와 그 이전의 시간들과는 관련 없다. 문제를 단순화 하여 agent가 이전의 모든 상태를 기억하지 않고도 그 순간의 보상을 극대화하는 데 집중할 수 있다.
Agent의 구성 요소
Agent의 목표는 Value Function을 최대화 하는 것이다. 이를 위해서는 장기적으로 가장 높은 Reward를 가져오는 최선의 Action을 선택하도록 Policy를 최적화해야 한다. Value Function과 Policy는 상호 의존적이며 반복적으로 개선된다.
Stochastic Policy: State가 주어지면 가능한 여러 action들이 일어날 확률이 리턴
Value Function: 현재 Policy에 따라 State가 얼마나 좋은지 나타내는 지표, 종료될 때까지 받을 수 있는 미래 리워드의 합산
v_π(s): State=s에서 시작했을 때, 정의된 policy에 따라 받게되는 총 기댓값
r: discount factor = 미래의 리워드는 불확실하니까 등의 이유로
Model: Model을 활용하여 Environment가 어떻게 될지 예측할 수 있다
State s에서 Action a를 했을 때
State=s에서 Action=a를 취한 후 즉각적인 reward는 무엇을 받을지 예측
State=s에서 Action=a를 취함으로써 발생할 다음 State가 무엇이 될지 예측
이러한 모델링 기법은 RL에서 사용될 수도(model-based) / 사용되지 않을수도(model-gree) 있다.
RL의 분류 (value-based/policy-based/actor critic) vs (model-free/model-based)
강화학습 방법은 두 가지로 분류할 수 있다.
value-based vs policy-based vs actor critic
value-based: policy(x), value function(o) -> 각 state에서 value를 학습하여, 이로부터 도출된 정책을 따르는 데 의존
value function만 있더라도 agent 역할을 할 수 있는 경우
policy-based: policy(o), value function(x) -> value function을 하용하지 않고 policy를 직접 최적화하는 데 중점
actor critic: policy(o), value function(o) -> policy와 value function을 동시에 학습
model-free vs model-based
model-free: policy and/or value function(o), model(x)
모델을 내부적으로 만들지 않고
model-based: policy and/or value function(o), model(o)
agent가 내부적으로 environment 모델을 추측하여 만들어서, model에 근거한 action이 이루어짐
RL 문제의 종류
강화학습에서 Agent는 크게 두 가지 방법으로 Policy를 개선할 수 있다.
Learning: Agent가 environment를 알지 못할 때, environment와 상호작용하면서 policy를 개선해나가는 것
Planning: Agent가 environment(reward & state transition)를 알고 있을 때, 실제로 environment에서 동작하지 않고도 내부 계산만으로 다양한 시나리오를 시뮬레이션하고 평가함으로써 policy를 개선해나간다
ex. 알파고의 몬테카를로 Search
Agent의 주요 목표는 크게 두가지로 나눌 수 있다.
Prediction: 주어진 Policy 하에서, 미래를 평가하는 것 = value function 을 잘 학습시키는 것
Control: Policy를 최적화하는 것 = best policy를 찾는 것
그 외 용어
Exploration: environment에 대한 새로운 정보를 발견하기 위해 이전에 해보지 않은 행동을 시도하는 것
Exploitation: 이미 가지고 있는 정보들을 활용하여 reward를 최대화하는 것
RL 학습이 잘 이루어지려면 Exploration과 Exploitation 두 개념에 대한 균형이 중요하다
Markov Decision Process(MDP)
강화학습이 적용되는 문제 도메인은 모두 MDP(=완전히 관찰 가능한 환경)이다
강화학습은 MDP으로 모델링할 수 있는 환경에서 최적의 순차적 의사결정을 하는 것이다.
MDP: RL에서의 environment를 표현 & environment가 모두 관측 가능한 상황을 말한다.
모든 강화학습 문제는 MDP 형태로 만들 수 있다.
Markov Process: n개의 State가 있고, 과거 경로에 관계없이 확률에 따라 State를 옮겨다니는 프로세스
State Transition Matrix: action없이 state를 확률에 따라 옮겨다님(Environment를 설명하기 위한 개념)
State S -> S'로 옮겨갈 확률 P_{ss'} = P[S_{t+1}=s' | S_t=s]일때, 모든 state의 확률을 나타내는 matrix
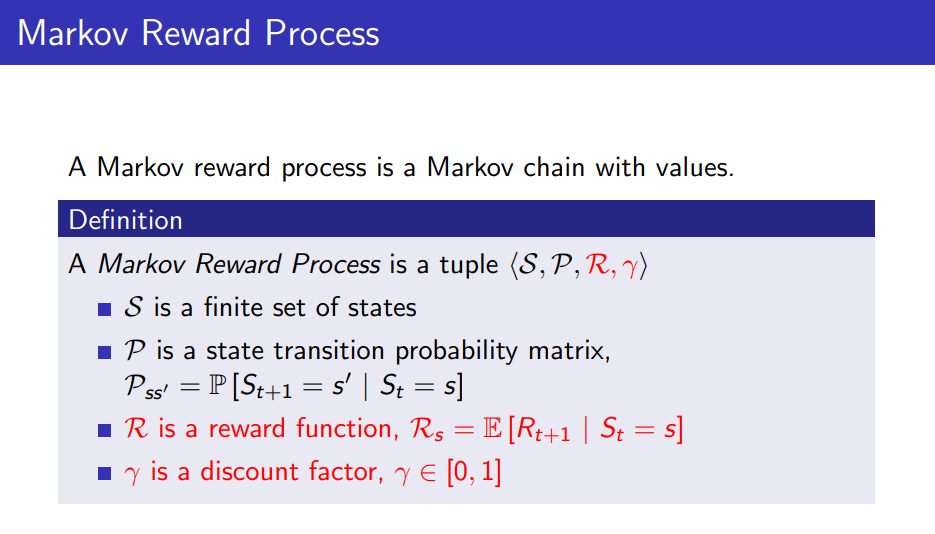
Markov Reward Process: n개의 State가 있고, 과거 경로에 관계없이 확률에 따라 State를 옮겨다니는 프로세스로, State s일때의 reward는 R_s=E[R_{t+1} | S_t=s]이고 r(discount factor)는 0~1사이 값이다.
Return: 강화학습은 return을 maximize하는 것이다.
G_t = R_{t+1} + rR_{t+2} + ... = 미래의 리워드 합
Value Function: Return의 기대값 = State s에 왔을 때 G_t의 기대값
v(s) = E[G_t | S_t=s] = State s에서 시작한 여러 episode들의 평균
r(R_{t+2} + rR_{t+3} + ...): discounted value of successor state = r v(s_{t+1})
v(s) = R_s + r\sum_{s' from S} P_{ss'}v(s')
R_s: s일때의 reward
P_{ss'}: s->s'로 옮겨갈 확률
v(s'): s'일때 value function
이를 행렬로 표현하면 V=(I-rP)^{-1}R이다. 즉, 주어져있는 값이므로 역행렬을 통해 한번에 계산이 가능하다.
computational complexity는 O(n^3)이므로 비싼 연산임
n이 작을 때는 한번에 계산 가능하지만, n이 클 때는 iterative(DP/Monte-Carlo Evaluation/Temporal Difference Learning)한 방법을 사용해야 한다.
Markov Decision Process: n개의 State와 Action이 있고, 과거 경로에 관계없이 확률에 따라 State를 옮겨다니는 프로세스로, Action a를 하고 State s일때의 reward는 R_s^a=E[R_{t+1} | S_t=s, A_t=a]이고 r(discount factor)는 0~1사이 값이다.
State s에서 Action a를 하면 확률적으로 다른 State들에 도달하게 된다.
P_{ss'}^a = P[S_{t+1}=s' | S_t=s, A_t=a]: State s에서 Action a를 했을 때 State s'로 갈 확률
Policy: State s일때 Action a를 할 확률 = agent의 행동을 완전히 결정해줌
π(a|s) = P[A_t=a | S_t=s]
Value Function: 만약 agent의 policy가 고정되면 Markov process와 동일하다고 볼 수 있으며, reward도 마찬가지로 MRP로 볼 수 있음
State Value Function: State s에서 Policy π를 따랐을 때, episode들의 평균
v_π(s) = E_π[G_t | S_t=s]
Action Value Function: State s에서 Action a를 했을 때, 그 이후에는 Policy π를 따랐을 때의 기댓값
q_π(s,a) = E_π[G_t | S_t=s, A_t=a]
Bellaman Expectation Equation (= Prediction 문제): Bellman Eq.와 마찬가지로
q_π(s,a) = R_s^a + r\sum_{s' from State} P_{ss'}^a v_π(s')
v_π(s) = \sum_{a from Action} π(a|s) {R_s^a +r\sum_{s' from State} P_{ss'}^a v_π(s')}
MRP에서의 Bellman Eq.에 의해 행렬식으로 바꾸면 V_π = (I-rP_π)^{-1}R_π 로 구할 수 있다.
마찬가지로 n이 커지면 구하기 어려우므로, q는 optimal value function을 이용하여 구한다.
Optimal Value Function
Optimal State Value Function: State s에서 어떤 policy를 따르든 간에, 그 중 가장 큰 value
Optimal Action Value Function: q*(s,a) = max_π(q_π(s,a))
Optimal Policy: 두 policy 중 더 나은 policy를 비교하기 위해서는 모든 State s에 대해 v_π(s) >= v_π'(s)가 성립하면 Policy π 가 Policy π' 보다 낫다고 할 수 있다.
Optimal Policy π*를 따르면 Optimal State Value Function v*(s)와 Optimal Action Value Function q*(s,a)를 구할 수 있다. 그리고 Optimal Policy는 q*(s,a)를 아는 순간 찾을 수 있다.
Bellman Optimality Equation (= Control 문제)
v*(s) = max_a(q*(s,a)): q*값들이 각 action마다 있을텐데, 그 중 max인 a를 선택하면 v*와 같다
q*(s,a) = R_s^a +r\sum_{s' from State} P_{ss'}^a v*(s')
따라서 v*(s) = max_a(R_s^a +r\sum_{s' from State} P_{ss'}^av*(s')): 이 식은 max 때문에 linear equation이 성립하지 않아 역행렬을 구하여 풀 수 없는 문제가 된다. 즉, 다양한 iterative solution method로 풀이를 해야한다.(value equation/policy equation/q-learning/sarsa)
options -ttt: 절대 시간 기록, 마이크로 초 단위 -T:시스템 호출에 소요된 시간, 각 시스템 호출의 시작과 끝 사이의 시간차를 기록, 디폴트는 마이크로 초 단위 -f: fork, vfork, clone 등의 시스템 콜의 결과로 현재 트레이싱 중인 프로세스에 의해 생성되는 자식 프로세스를 트레이싱한다. (만약 프로세스가 멀티스레드인 경우, 모든 스레드를 트레이싱) -Z: 오류코드와 함께 반환된 시스템 콜만 기록 -z:오류코드 없이 반환된 시스템 콜만 기록 -o:트레이스 출력을 지정된 파일에 쓴다. 인수가 | 또는 !로 시작하면 나머지 인수는 커맨드로 취급되어, 모든 기록이 파이프로 전달된다. 이 옵션은 실행중인 프로그램의 리디렉션에 영향을 주지 않고, 디버깅 출력을 프로그램으로 파이프할 때 편하다.
Strace는 왜 컨테이너와 일반 프로세스에서 다르게 동작할까?
A containerized process uses system calls and needs permissions and privileges in just the same way that a regular process does. But containers give us some new ways to control how these permissions are assigned at runtime or during the container image build process, which will have a significant impact on security.
커널관점에서는 컨테이너 내에서 실행되는 프로세스 vs 호스트에서 실행되는 프로세스가 크게 다르지 않다.
결국 둘 다 단순히 생각하면 프로세스이고, 커널 영역을 공유한다. 따라서 syscall, kprobe, tracepoint 등의 커널 관련 이벤트로 프로세스를 트레이싱 하는 것은 동일 할 것이다.
가비지 컬렉션은 프로그램에서 더 이상 필요하지 않을 때 할당된 메모리를 회수하거나 해제하는 프로세스이다.
가비지 컬렉션(GC)은 메모리를 자동으로 관리하는 방법 중 하나이다. 가비지 컬렉션은 프로그램에 의해 할당되었지만 더 이상 참조되지 않는 메모리(가비지)를 회수하려고 시도한다. - Wikipedia
C 와 같은 언어에서는 프로그래머가 사용하지 않는 객체(사용되지 않는 객체의 가비지 컬렉션)에 대한 메모리를 수동으로 해제해야 하는 반면, Python 에서는 언어 자체가 자동으로 관리한다.
Python 은 자동 가비지 컬렉션에 두 가지 방법을 사용한다:
1. 참조 횟수를 기반으로 한 가비지 컬렉션
2. 세대별 가비지 컬렉션
먼저 참조 횟수가 무엇인지 설명하고, 참조 카운팅을 기반으로 한 가비지 컬렉션에 대해 자세히 알아보자!
Reference Count
이전 글에서 본 것처럼, CPython 은 내부적으로 각 객체에 대한 속성 유형과 참조 횟수를 생성한다.
ref count 속성을 더 잘 이해하기 위한 예를 살펴보자
a = "memory"
위 코드가 실행되면, CPython 은 문자열 유형의 객체 메모리를 생성한다.
필드 ref count 는 객체에 대한 참조 횟수를 나타낸다. 이전 글에서 우리는 Python 변수가 객체에 대한 참조일 뿐이라는 것을 알고 있다. 위 예에서 변수 a 는 문자열 객체 메모리에 대한 유일한 참조이다. 따라서 문자열 객체 메모리의 참조 카운트 값은 1이다.
getrefcount 메서드를 사용하면 Python 에서 모든 객체의 참조 횟수를 얻을 수 있다.
위 예시에서 getrefcount 메소드로 인한 참조 횟수 증가를 무시하면 문자열 객체 "garbage" 의 참조 횟수는 2이고, 배열 객체의 참조 횟수는 1이다. (garbage: 변수 x 에서 참조되고, 리스트 b 에서도 참조됨)
이 때, 변수 x 를 삭제하면
del x
b[0] # Output: garbage
문자열 객체 "garbage" 의 참조 횟수는 아래와 같이 배열 객체 [x, 20]로 인해 1이 된다.
우리는 변수 b 에 의해 문자열 객체 "garbage" 에 여전히 접근할 수 있다.
여기서 변수 b 를 삭제 해보자:
del b
위 코드가 실행되면, 배열 객체의 참조 횟수는 0 이 되고, 가비지 컬렉션은 배열 객체를 삭제한다.
배열 객체 [x, 20] 를 삭제하면 배열 객체에서 문자열 객체 "garbage" 의 참조 x 도 삭제된다.
이렇게 하면 "garbage" 객체의 참조 횟수가 0이 되고, 결과적으로 "garbage" 개체도 수집된다.
따라서 객체의 가비지 컬렉션은 객체가 참조하는 다른 객체의 가비지 수집을 유발할 수도 있다.
참조 횟수에 따른 가비지 컬렉션은 실시간으로 이루어진다!
가비지 컬렉션은 객체의 참조 횟수가 0 이 되는 즉시 시작된다. 이는 Python 의 주요 가비지 컬렉션 알고리즘 방식이며 비활성화할 수 없다.
순환 참조가 있는 경우에는 참조 횟수를 기반으로 하는 가비지 컬렉션이 작동하지 않는다. 그래서 순환 참조가 있는 객체의 메모리를 해제하기 위해 Python 은 세대별 가비지 컬렉션 알고리즘을 사용한다.
다음으로 순환 참조에 대해 논의한 다음 세대별 가비지 컬렉션 알고리즘에 대해 더 깊이 이해해보자!
Cyclic References in Python
순환 참조는 객체가 자기 자신을 참조하거나 두개의 다른 객체가 서로를 참조하는 상태를 의미한다. 이러한 순환 참조는 리스트, 딕셔너리 및 사용자 정의 객체 등의 컨테이너 객체에서만 가능하다. 그리고 정수, 실수 또는 문자열과 같은 불변 데이터 타입에서는 불가능하다.
다음 예시를 살펴보자:
왼편에서 볼 수 있듯이 배열 객체 b 는 자신을 참조하고 있다.
오른쪽처럼 참조 b 를 삭제하면 Python 코드에서 배열 객체에는 접근할 수 없지만, 오른쪽 이미지와 같이 메모리에는 계속 존재하게 된다. 배열 객체가 자기 자신을 참조하므로 배열 객체의 참조 횟수는 영원히 0이 되지 않으며, 참조 횟수 기반 가비지 컬렉션에 의해서는 수집될 수 없다.
다른 예시를 살펴보면:
각각 ClassA 및 ClassB 클래스의 두 객체 object_a 및 object_b를 정의한다고 하자. object_a 는 변수 A 에서 참조하고 object_b 는 변수 B에서 참조 할 때, object_a 에는 object_b 를 가리키는 속성 ref_b 가 있다. 마찬가지로 객체 object_b 에는 object_a 를 가리키는 속성 ref_a 가 있다. 즉, object_a 와 object_b 는 각각 변수 A 와 B 를 이용하여 Python 코드에서 접근 할 수 있다.
만약 변수 A 와 B 를 삭제할 경우,
del A
del B
위 코드와 같이 변수 A 와 B 를 삭제하면, object_a 와 object_b 는 Python 에서 접근할 수 없지만 메모리에는 계속 남아있게 된다.
이렇게 객체는 서로 가리키고 있는 상태이므로(ref_a 및 ref_b 속성에 의해) 참조 횟수는 결코 0 이 될 수 없다. 따라서 이러한 객체는 참조 카운트 기반 가비지 컬렉터에 의해 수집되지 않는다. 따라서 이러한 경우 Python 은 세대별 가비지 컬렉션이라는 또 다른 가비지 컬렉션 알고리즘을 제공한다.
Generational Garbage Collection in Python
세대별 가비지 컬렉션 알고리즘은 순환 참조를 가지는 객체를 가비지 컬렉션하는 문제를 해결할 수 있다.
순환 참조는 컨테이너 객체에서만 가능하므로, 이 알고리즘은 모든 컨테이너 객체를 스캔하여 순환 참조를 가지는 객체를 검출한 다음, 가비지 컬렉션이 가능한 경우 제거한다.
스캔되는 객체 수를 줄이기 위해, 세대별 가비지 컬렉션은 불변 타입(예: int 및 문자열)만 포함하는 튜플을 무시한다.
객체를 탐색하고 순환 참조를 감지하는 것은 시간이 많이 걸리는 작업이므로 세대별 가비지 컬렉션 알고리즘은 실시간으로 작동하지 않으며 주기적으로 실행된다. 세대별 가비지 컬렉션 알고리즘이 실행되면 다른 모든 것이 중지된다. 따라서 세대별 가비지 컬렉션 알고리즘이 트리거되는 횟수를 줄이기 위해 CPython 은 컨테이너 객체를 여러 세대로 분류하고, 각 세대에 속할 수 있는 컨테이너 객체 수에 대한 임계값을 정의함으로써 지정된 세대의 객체 수가 정의된 임계값을 초과하면 세대별 가비지 컬렉션이 실행된다.
CPython 은 객체를 3세대(0, 1, 2세대) 로 분류한다. 새 객체가 생성되면 먼저 0 세대에 속하며, CPython 이 세대별 가비지 컬렉션 알고리즘을 실행할 때 이 객체가 수집되지 않으면 1 세대로 이동한다. CPython이 세대별 가비지 컬렉션을 다시 실행할 때 개체가 수집되지 않으면 2 세대로 이동한다. 이것은 마지막 세대이며 객체는 그대로 유지된다. 일반적으로 대부분의 객체는 1 세대에서 수집된다.
주어진 세대에 대해 세대별 가비지 컬렉션이 실행되면, 그동안 더 어린 세대들도 함께 가비지 컬렉션이 수행된다. 예를 들어 1 세대에 대해 가비지 컬렉션이 트리거되면, 0세대에 있는 객체들도 함께 수집된다. 모든 세 세대(0, 1, 2)가 가비지 컬렉션이 수행되는 상황을 풀 컬렉션(full collection) 이라고 한다. 풀 컬렉션은 대량의 객체를 스캔하고 순환 참조를 감지하는 것이 포함되므로 CPython 은 가능한 한 풀 컬렉션을 피하려고 한다.
Python 에서 제공하는 gc 모듈을 사용하면 세대별 가비지 컬렉션의 동작을 변경할 수 있다. 세대별 가비지 컬렉션은 gc 모듈을 사용하여 비활성화할 수 있다. 이를 선택적 가비지 컬렉션이라고 한다.
위의 출력값은 0 세대의 임계값이 700, 2 세대 및 3 세대의 임계값이 10임을 나타낸다.
0 세대에 700개 이상의 개체가 있는 경우 0 세대의 모든 개체에 대해 세대별 가비지 컬렉션이 트리거된다.
그리고 1 세대에 10개 이상의 개체가 있는 경우 1 세대와 0 세대 모두에 대해 세대별 가비지 컬렉션이 트리거된다.
2. 각 세대에 속한 객체의 수를 확인하기:
import gc
gc.get_count()
# Output: (679, 8, 0) # Note: Output will be different on different machines
여기서 0 세대는 679개, 1 세대는 8개, 2 세대는 0개이다.
3. 세대별 가비지 컬렉션 알고리즘을 수동으로 실행하기:
import gc
gc.collect()
gc.collect() 는 세대별 가비지 컬렉션을 트리거하며, 초기 설정 상 풀 컬렉션(full collection)을 실행한다.
만약 특정한 세대에 대한 세대별 가비지 수집을 실행하려면 아래와 같이 파라미터를 설정한다.
import gc
gc.collect(generation=1)
가비지 컬렉션 과정이 끝난 후에도 남아 있는 객체의 수를 확인해보면 아래와 같이 나타날 수 있다.
import gc
gc.get_count()
# Output: (4, 0, 0) # Note: Output will be different on different machines
4. 각 세대의 세대 임계값을 업데이트하기:
import gc
gc.get_threshold()
gc.set_threshold(800, 12, 12)
gc.get_threshold()
# Output: (800, 12, 12) # Note: Output will be different on different machines
5. 세대별 가비지 컬렉션을 비활성화/활성화 하기
gc.disable() # disable generational garbage collection
gc.enable() # enable it again
Conclusion
이 글에서는 Python 이 규칙과 스펙들의 집합이며, CPython 은 C 로 구현된 Python 의 참조 구현체임을 배웠다.
또한 Python 이 메모리를 효율적으로 관리하기 위해 사용하는 여러 메모리 할당자, 예를 들어 Object Allocator, Object-specific Allocator, Raw memory allocator, General purpose Allocator 등을 배웠다. 그리고 Python 메모리 관리자가 소규모 객체(512 byte 이하)에 대한 메모리 할당/해제를 최적화하는 데 사용하는 Arena, Pool, Block 에 대해 배웠다. 마지막으로 참조 횟수 및 세대 기반의 가비지 컬렉션 알고리즘에 대해서도 배웠다.
메모리 관리는 컴퓨터 메모리(RAM)를 효율적으로 관리하기 위한 과정으로, 프로그램 요청 시 런타임에 메모리 조각을 프로그램을 할당하고 프로그램이 더 이상 메모리를 필요로 하지 않을 때 할당했던 메모리를 재사용하기 위해 할당된 메모리를 해제하는 작업을 포함한다.
C 또는 Rust 의 경우 프로그램에서 메모리를 사용하기 전에 수동으로 메모리를 할당하고 프로그램이 더 이상 필요하지 않을 때 메모리를 해제해야 한다. 즉, 메모리 관리는 프로그래머의 책임이다. Python 에서는 자동으로 메모리 할당 및 할당 해제를 처리한다.
이 글에서는 Python 의 메모리 관리 내부적인 동작에 관해 설명한다. 또한, 객체와 같은 기본 단위가 메모리에 저장되는 방법, Python 의 다양한 메모리 할당자 유형, Python 의 메모리 관리자가 메모리를 효율적으로 관리하는 방법에 대해 설명한다.
Python 메모리 관리의 내부 동작을 이해하면, 메모리 효율적인 애플리케이션을 설게하는 데 도움이 될것이다. 또한 애플리케이션의 메모리 문제를 더 쉽게 디버깅할 수 있다.
Pythond 의 언어 사양에 대해 이해하는 것부터 시작하여 CPython 에 대해 자세히 살펴보자!
Python as a Language Spectification
Python 은 프로그래밍 언어로, 이 문서는 Python 언어에 대한 규칙 및 사양을 명시한 Python 참조 문서이다.
예를 들어, Python 언어 사양에 따르면 함수를 정의하기 위해서는 def 키워드를 사용해야 한다고 명시되어 있다.
이는 사양일 뿐이며 컴퓨터가 deffunction_name 을 사용하면 => function_name 이라는 이름의 함수를 정의하려고 한다는 것을 컴퓨터가 이해할 수 있도록 규칙과 사양에 따라 프로그램을 작성해야 한다.
Python 의 언어 규칙 및 사양은 C, Java, 그리고 C# 과 같은 다양한 프로그래밍 언어로 구현된다.
C로 Python 언어를 구현한 것을 CPython 이라고 하고, Java 와 C# 으로 Python 언어를 구현한 것을 각각 Jython 과 IronPython 이라고 한다.
What is CPython?
CPython 은 Python 언어의 기본이자 가장 널리 사용되는 구현이다. Python 이라고 하면 대부분 CPython을 의미한다.
python.org 에서 Python 을 다운로드 하면 기본적으로 CPython 코드가 다운로드 된다. 따라서 CPython 은 C 언어로 작성된 프로그램으로, Python 언어에 정의된 모든 규칙과 사양을 구현한다.
CPython 은 Python 프로그래밍 언어의 참조구현이다. CPython 은 Python 코드를 바이트 코드로 컴파일 후 한 줄씩 실행하기 때문에, 인터프리터와 컴파일러 둘 다로 정의될 수 있다. - Wikipedia
CPython 은 참조 구현이므로 Python 언어의 모든 새로운 규칙과 사양은 먼저 CPython 을 통해 구현된다.이 글에서는 CPython 의 메모리 관리 내부에 대해 설명한다.참고로 JPython 및 IronPython 과 같은 다른 구현에서는 메모리 관리는 다른 방식으로 할 수도 있다. CPython 은 C 프로그래밍 언어로 구현되었으므로 먼저 C 의 메모리 관리와 관련된 두가지 중요한 기능: malloc 과 free 에 대해 알아보자.
What aremallocandfreeFunctions in C?
malloc 은 런타임에 운영 체제에서 메모리 블록을 요청하기 위해 C 프로그래밍 언어에서 사용되는 방법니다. 프로그램이 런타임에 메모리가 필요할 때, 필요한 메모리를 얻기 위해 malloc 메서드를 호출한다.
free 는 프로그램이 더 이상 메모리를 필요로 하지 않을 때, 프로그램에 할당된 메모리를 다시 운영체제로 해제하기 위해 C 프로그래밍 언어에서 사용되는 방법이다.
Python 프로그램에 메모리가 필요한 경우는 CPython 이 내부적으로 malloc 메서드를 호출하여 메모리를 할당한다. 만약 프로그램에 더 이상 메모리가 필요하지 않으면 CPython 은 free 메서드를 호출하여 메모리를 해제한다.
이제 파이썬에서 서로 다른 객체에 메모리가 어떻게 할당되는지 살펴보자!
Objects in Python
Python 에서는 모든것이 객체이다. 클래스, 함수, 그리고 integer, floats, string 과 같은 간단한 데이터 유형도 객체이다.
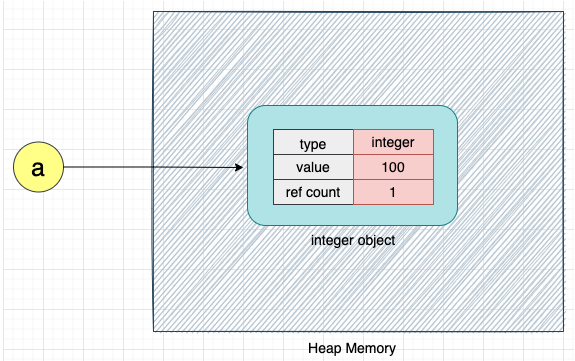
예를 들어, Python 에서 정수를 정의하면 CPython은 내부적으로 정수 유형의 객체를 생성한다. 이러한 개체는 힙 메모리에 저장된다.
각 객체는 value, type, reference count 세 필드를 가진다.
a = 100
위 코드가 실행되면, CPython 은 정수 유형의 객체를 생성하고 이 객체에 대한 메모리를 힙 메모리에 할당한다.
type 은 CPython 에서 객체의 타입을 나타내며, value 필드는 이름에서 알 수 있듯이 객체의 값(100) 을 저장한다.
이 글 뒷부분에서 ref count 필드에 관해 더 자세히 설명할 것이다.
Variables in Python
Python 의 변수는 메모리의 실제 객체에 대한 참조일 뿐이다. 변수들은 메모리에 있는 실제 객체를 가리키는 이름이나 레이블이며, 어떤 값도 저장하지는 않는다. 위 그림과 같이 변수 a 를 사용하여 Python 프로그램에서 정수 객체에 접근할 수 있다.
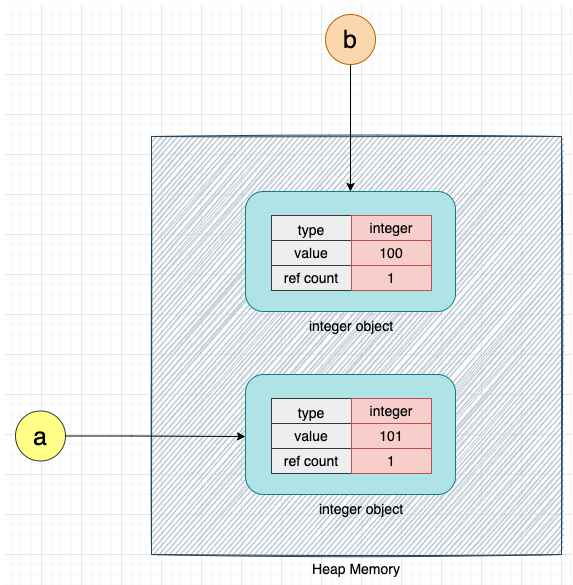
a = 100
b = a
그렇다면 이 정수 객체를 다른 변수 b 에 할당해보자
그리고 정수 객체의 값을 1 증가해보면,
# Increment a by 1
a = a + 1
위 코드가 실행되면 CPython은 값이 101 인 새 정수 객체를 만들고 변수를 이 새 정수 객체를 가리키도록 한다. 변수 b는 100인 정수 개체를 계속 가리킨다.
여기서 우리는 100 의 값을 101 로 덮어쓰지 않고 CPython 이 값 101 의 새 객체를 생성하는 것을 확인할 수 있다.
즉, 일단 생성되면 수정할 수 없으며, 부동 소수점 및 문자열 데이터 유형 또한 Python 에서 변경할 수 없다.
이 개념을 더 자세히 설명하기 위해 간단한 Python 프로그램을 살펴보자
# 변수 i 값이 100 미만이 될 때까지 증가시키는 while 루프
i = 0
while i < 100:
"""
# 변수 i 가 증가할 때마다 CPython은 증가된 값으로 새로운 정수 객체를 생성하고
# 이전 정수 객체는 메모리에서 삭제 대상이 된다.
"""
i = i + 1
CPython 은 이와 같이 각각의 새 객체에 대해 malloc 메서드를 호출하여 해당 객체에 대한 메모리를 할당하고, free 메서드를 호ㅗ출하여 메모리에서 이전 객체를 삭제한다.
위의 코드를 malloc 과 free 를 사용한 코드로 변환해보면 아래와 같다.
i = 0 # malloc(i)
while i < 100:
# malloc(i + 1)
# free(i)
i = i + 1
우리는 CPython 이 이렇게 간단한 프로그램에도 많은 수의 객체를 생성하고 삭제하는 것을 확인할 수 있다.
각 객체 생성 및 삭제에 대해 매번 malloc 과 free 메서드를 호출하면 프로그램의 실행 성능이 저하되고 프로그램이 느려진다.
따라서 CPython 은 각각의 작은 객체 생성 및 삭제에 대해 malloc 및 free 호출 횟수를 줄이기 위해 다양한 기술을 도입한다.
이제 CPython 이 메모리를 관리하는 방법에 대해 이해해보자
Memory Management in CPython
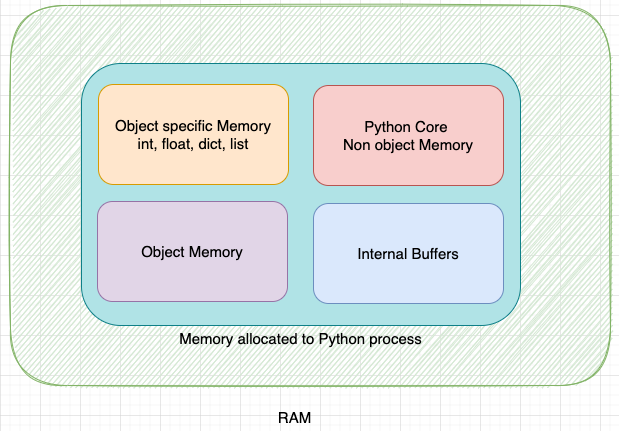
Python 의 메모리 관리에는 프라이빗 힙 관리가 포함된다. 프라이빗 힙은 Python 프로세스의 전용 메모리 영역이다.
모든 Python 객체 및 데이터 구조는 프라이빗 힙에 저장된다.
운영체제는 이 메모리 영역을 다른 프로세스에 할당할 수 없으며, 프라이빗 힙의크기는 Python 프로세스의 메모리 요구 사항에 따라 늘어나고 줄어들 수 있다. 프라이빗 힙은 CPython 코드 내부에 정의된 Python 메모리 관리자에 의해 관리된다.
CPython 의 프라이빗 힙은 아래 그림과 같이 여러 부분으로 나뉜다.
이러한 각 부분의 경계는 고정되어 있지 않으며, 요구 사항에 따라 확장되거나 축소될 수 있다.
Python Core Non-object memory: Python Core Non-Object 데이터에 할당된 메모리 부분이다.
Internal Buffers: 내부 버퍼에 할당된 메모리 부분이다.
Object-specific memory: 객체별 메모리 할당자가 있는 객체에 할당된 메모리 부분이다.
Object memory: 객체에 할당된 메모리 부분이다.
프로그램이 메모리를 요청하면, CPython 은 malloc 메서드를 사용하여 운영체제에서 해당 메모리를 요청하고, 프라이빗 힙의 크기가 커진다. 그리고 CPython에서는 각각의 작은 객체 생성 및 삭제를 위한 malloc과 free를 호출하지 않도록 다양한 할당자와 해제자를 정의한다. 다음 섹션에서 각각 상세히 알아보자!
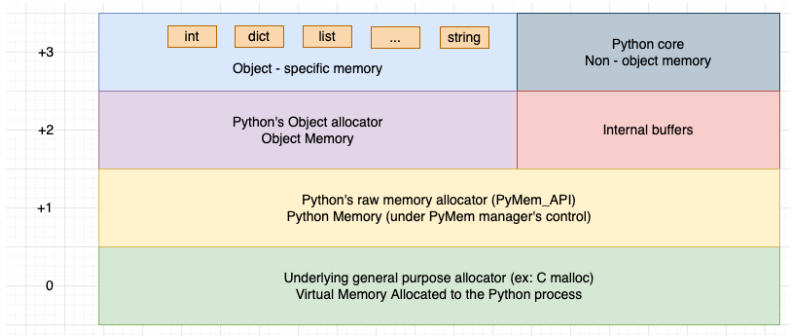
Memory Allocators
malloc 및 free 메서드를 자주 호출하지 않기 위해 CPython은 아래와 같이 할당자의 계층 구조를 정의한다.
그림의 메모리 계층 구조의 아래에서부터,
General Purpose Allocator (CPython 의malloc 메서드): 메모리 계층 구조의 가장 아래에는 General Purpose Allocator 가 있다. 범용 할당자는 CPython 용 `C 언어의 malloc` 메서드이다. 이는 운영 체제의 가상 메모리 관리자와 상호작용하여 Python 프로세스에 필요한 메모리를 할당한다. 또한, 운영체제의 가상 메모리 관리자와 통신하는 유일한 할당자이다.
Raw memory Allocator (512 byte 보다 큰 객체용): General Purpose Allocator 위에는 Python 의 Raw memory Allocator 가 있다. Raw memory Allocator 는 General Purpose Allocator(=malloc) 에 대한 추상화를 제공한다. Python 프로세스에 메모리가 필요한 경우, Raw memory Allocator 는 General Purpose Allocator 와 상호작용하여 필요한 메모리를 제공한다. 그리고 Python 프로세스의 모든 데이터를 저장할 충분한 메모리 공간이 있는지 확인한다.
Object Allocator (512 byte 보다 작거나 같은 객체용): Raw memory Allocator 위에는 Object Allocator 가 있는데, 이 할당자는 512 byte 이하의 작은 객체에 대한 메모리 할당에 사용된다. 만약 객체에 512 byte 이상의 메모리가 필요한 경우 Python 의 메모리 관리자는 Raw memory Allocator 를 직접 호출한다.
Object-specific Allocators (특정 데이터 유형에 대한 특정 메모리 할당자): Object Allocator 위에는 Object-specific Allocators 가 있다. 정수, 실수, 문자열 및 리스트와 같은 단순 데이터 유형에는 각각의 객체별 할당자가 있다. 이러한 객체별 할당자는 객체의 요구 사항에 따라 메모리 관리 정책을 구현한다. 즉, 정수에 대한 객체별 할당자는 실수에 대한 객체별 할당자와 구현 방식이 다르다.
Object Allocator 와 Object-specific Allocators 모두 Raw memory Allocator 에 의해 Python 프로세스에 이미 할당된 메모리에서 작동한다. 이러한 할당자는 운영 체제에서 메모리를 직접 요청하지 않고, 프라이빗 힙에서 작동한다. Object Allocator 와Object-specific Allocators 에 더 많은 메모리가 필요한 경우 Python 의 Raw memory Allocator 가 General Purpose Allocator 와 상호작용하여 메모리를 제공한다.
Hierarchy of Memory Allocators in Python
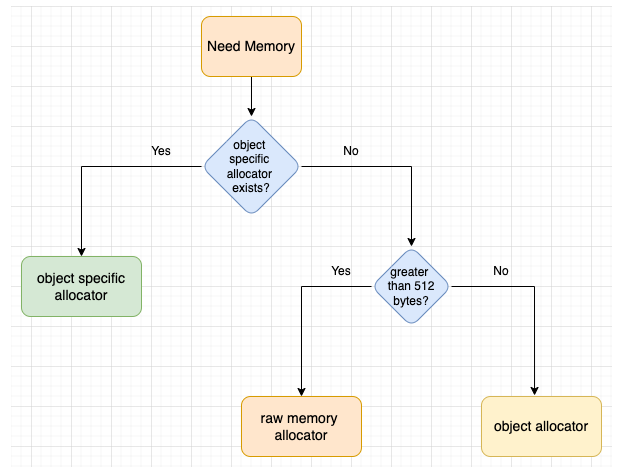
객체가 메모리를 요청하고 객체에 object-specific allocator 가 정의되어 있으면, object-specific allocator 가 메모리를 할당하는데 사용된다.
객체에 object-specific allocator 가 없고 512 byte 이상의 메모리가 요청된 경우 Python 메모리 관리자는 Raw memory Allocator 를 직접 호출하여 메모리를 할당한다.
요청된 메모리 크기가 512 byte 미만일 때, Object Allocator 를 사용하여 할당한다.
Object Allocator
object allocator 는 pymalloc이라고도 하며, 크기가 512 byte 미만인 작은 개체에 메모리를 할당하는 데 사용된다.
general-purpose malloc 위에 사용되는 작은 블록을 위한 빠른 특수 목적 메모리 할당자. object-specific allocator 가 독점 할당 체계를 구현하지 않는 한 모든 객체 할당/할당 해제에 대해 호출된다. (예: int 는 간단한 free 리스트를 사용함)
이는 순환 가비지 컬렉터가 컨테이너 객체에서 선택적으로 작동하는 곳이기도 하다.
작은 객체가 메모리를 요청하면 해당 객체에 대한 메모리를 할당하는 대신, 객체 할당자가 운영체제에서 큰 메모리 블록을 요청한다. 이 큰 메모리 블록은 나중에 다른 작은 객체에 메모리를 할당하는 데 사용된다.
CPython 코드베이스에서 발췌한 내용에 따르면
이런식으로 객체 할당자는 각각의 작은 객체에 대해 malloc 을 직접 호출하는 것을 방지한다.
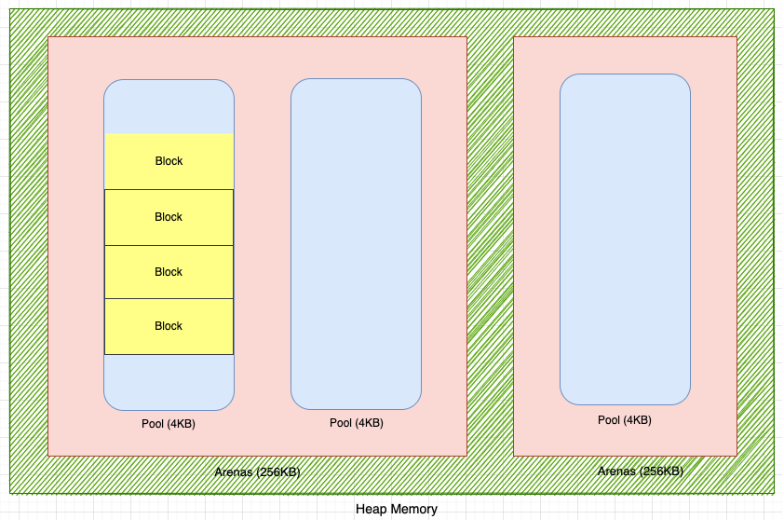
객체 할당자가 할당하는 큰 메모리 블록을 Arena 라고 한다. Arena 의 크기는 256KB 이다.
Arena 를 효율적으로 사용하기 위해서 CPython 은 Arena 를 Pool(4KB) 로 나눈다. 따라서 Arena 는 64개의 Pool 로 구성될 수 있다.
Pool 은 다시 블록으로 나뉜다.
다음 장에서는 이러한 각 구성 요소에 대해 설명한다.
Blocks
블록은 object allocator 가 객체에 할당할 수 있는 가장 작은 메모리 단위이다. 블록은 하나의 객체에만 할당될 수 있고, 객체 또한 하나의 블록에만 할당될 수 있다. 즉, 객체의 일부를 두 개 이상의 개별 블록에 배치하는 것은 불가능하다.
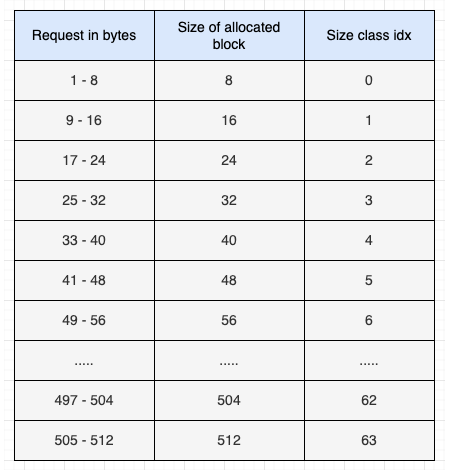
블록은 다양한 크기로 제공된다. 블록의 최소 크기는 8 byte 이고, 최대 크기는 512 byte 이다. 블록 크기는 8의 배수로 8, 16, 24, 32, ..., 504, 512 바이트가 될 수 있다. 각 블록 크기를 Size Class 라고 한다. Size Class 는 아래와 같이 64 개의 등급으로 나뉜다.
이 표에서 볼 수 있듯이 size class 0 블록의 크기는 8 byte 이고, size class 1 블록의 크기는 16 byte 이다.
프로그램은 항상 블록 하나 전체에 할당되거나, 아예 할당이 되지 않거나 두 가지 상태만 존재한다. 즉, 프로그램이 14 byte 의 메모리를 요청하면 16 byte 의 블록이 할당된다. 마찬가지로 프로그램이 35 byte 의 메모리를 요청하면 40 byte 의 블록이 할당된다.
Pools
풀은 size class 가 하나인 블록들로 구성된다. 예를 들어 size class 0 의 블록이 있는 풀은 다른 size class 의 블록을 가질 수 없다.
풀의 크기는 가상 메모리 페이지의 크기와 같다.
가상 메모리 페이지: 페이지, 메모리 페이지, 또는 가상 페이지는 가상 메모리의 고정 길이 연속 블록이다. 가상 메모리 운영 체제에서 메모리 관리를 위한 가장 작은 데이터 단위이다. - Wikipedia
대부분의 경우, 풀 크기는 4KB 이다.
풀은 요청된 size class 의 블록이 있는 사용 가능한 다른 풀이 없는 경우에만 아레나에서 잘라낸다.
풀은 다음 세 가지 상태 중 하나일 수 있다.
Used: 풀에 할당에 사용된 블록이 있는 경우 사용됨 상태에 있다고 한다.
Full: 풀의 모든 블록이 할당된 경우 풀이 가득찬 상태에 있다고 한다.
Empty: 풀의 모든 블록을 할당할 수 있는 경우, 풀이 비어있는 상태라고 한다. 빈 풀에는 size class 개념이 없으며, 모든 size class 등급의 블록을 할당하는 데 사용할 수 있다.
풀은 CPython 코드에서 아래와 같이 정의된다:
/* Pool for small blocks. */
struct pool_header {
union { block *_padding;
uint count; } ref; /* number of allocated blocks */
block *freeblock; /* pool's free list head */
struct pool_header *nextpool; /* next pool of this size class */
struct pool_header *prevpool; /* previous pool "" */
uint arenaindex; /* index into arenas of base adr */
uint szidx; /* block size class index */
uint nextoffset; /* bytes to virgin block */
uint maxnextoffset; /* largest valid nextoffset */
};
szidx: 풀의 size class를 나타낸다. 풀에 대해 szidx 가 0이면 size class 0 의 블록, 즉 8 byte 블록만 포함된다.
arenaindex: 풀이 속한 arena 의 인덱스를 나타낸다.
동일한 size class 의 풀은 이중 연결 리스트를 사용하여 서로 연결된다.
nextpool: 같은 size class 의 다음 풀을 가리키는 포인터
prevpool: 같은 크기 클래스의 이전 풀을 가리키는 포인터
동일한 size class 의 풀이 연결되는 방법은 아래 그림과 같다.
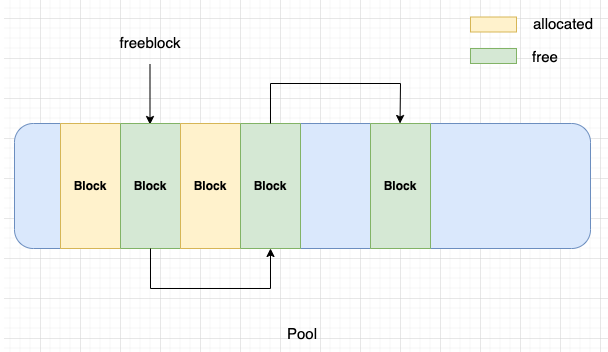
freeblock: 풀 내에서 사용가능한 블록의 단일 연결 리스트의 시작을 가리키는 포인터로, 할당된 블록이 해제되면 freeblock 포인터 앞에 추가된다.
왼쪽 그림에서 볼 수 있듯이, allocated 블록은 객체에 할당된 상태이고, free 블록은 개체에 할당되었지만 이제 새 개체에 할당 가능한 블록이다.
메모리에 대한 요청이 생기면, 요청된 size class 의 블록을 사용할 수 있는 풀이 없는 경우 CPython 은 Arena 에서 새 풀을 만든다고 했다.
그렇다고 해서 새 풀이 만들어지면 전체 풀이 즉시 블록으로 설정되는 것이 아니다. 블록은 필요에 따라 풀에서 만들어질 수 있다.
위 그림에서 풀의 파란색 영역은 해당 부분이 블록으로 아직 만들어지지 않았음을 나타낸다.
CPython 코드베이스에서 발췌한 내용에 따르면
블록조각: 풀에서 사용 가능한 블록은 풀이 초기화될 때 (블록끼리)함께 연결되지 않는다. 대신 가장 낮은 주소를 가지는, 처음 두개 블록만 설정되어 첫 번째 블록을 반환하고, pool->freeblock 을 두 번째 블록을 포함하는 단일 블록 리스트로 설정한다. 이는 pymalloc 이 실제로 필요할 때까지 메모리 조각을 건드리지 않으려고 아레나, 풀 및 블록 등 모든 수준에서 노력하는 것이다.
우리는 아레나에서 새 풀을 만들 때 풀에서 처음 두 블록만 만들어지는 것을 볼 수 있다.
블록 하나는 메모리를 요청한 객체에 할당되고, 다른 블록은 사용 가능하거나 변경되지 않는다. freeblock 포인터가 이 사용되지 않은 블록을 가리킨다.
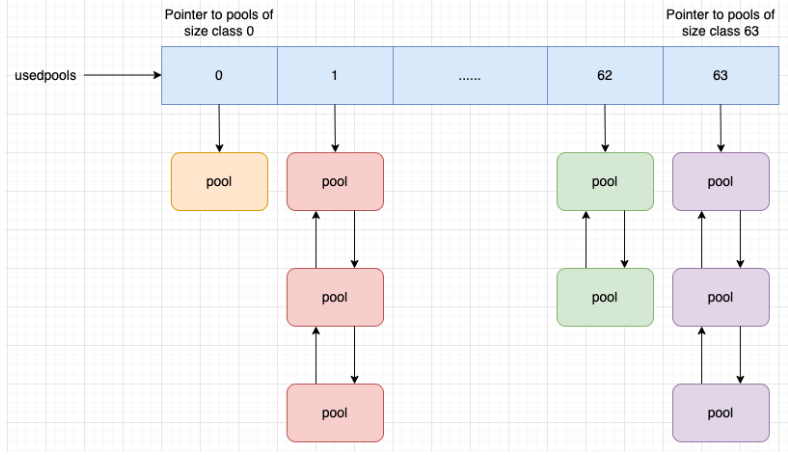
CPython 은 모든 size class 의 used 상태에서 풀을 추적하기 위해 usedpools 라는 배열을 유지 및 관리한다. 이때 used 상태는 할당에 사용되었지만, 현재는 할당에 사용 가능한 상태를 일컫는다.
usedpools 배열의 인덱스는 풀의 size class 인덱스와 동일하다. usedpools 배열의 각 인덱스 i 에 대해 usedpools[i] 는 size class i 의 풀 헤더를 가리킨다.
예를 들어, usedpools[0] 은 size class 0 의 풀 헤더를 가리키고, usedpools[1] 은 size class 1 의 풀 헤더를 가리킨다.
아래 그림을 보면 더 이해하기 쉬울 것 같다:
동일한 size class 의 풀은 이중 연결 리스트를 사용하여 서로 연결되어 있으므로, 각 size class 의 used 상태에 있는 모든 풀은 usedpools 배열을 사용하여 순회할 수 있다.
usedpools[i] == null 이면 used 상태의 size class i 인 풀이 없음을 의미한다. 객체가 size class i 의 블록을 요청하면 CPython 은 size class i 의 새 풀을 만들고 usedpools[i] 가 이 새 풀을 가리키도록 업데이트 한다.
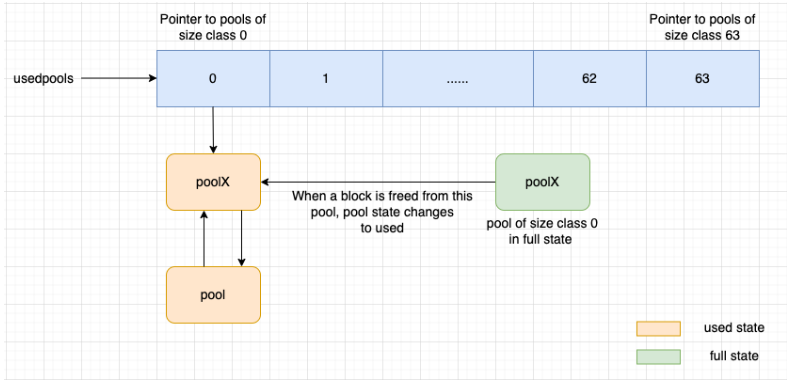
full 상태의 블록이 free 가 되면, 풀 상태는 full 에서 used 상태로 변경된다. CPython 은 이 풀을 size class 풀의 이중 연결 리스트 앞에 추가한다.
그림과 같이, poolX는 size class 0 이며 full 상태이다. 블록이 poolX에서 해제되면, 상태가 full 에서 used 로 변경되는데, 이때 CPython 은 이 풀을 size class 0 의 풀 이중 연결 리스트의 맨 앞에 추가하고, usedpools[0] 이 poolX 를 가리키도록 한다.
Arenas
아레나는 작은 개체에 메모리를 할당하는 데 사용되는 큰 메모리 블록이다.
이들은 raw memory allocator 에 의해 256KB 크기로 할당된다.
작은 객체가 메모리를 요청하되, 이 요청을 처리할 기존 영역이 없는 경우 raw memory allocator 는 운영 체제에서 큰 메모리 블록 256KB 를 요청한다. 이러한 큰 메모리 블록을 아레나라고 한다. (그리고 풀은 필요할 때 아레나에서 만들어진다.)
struct arena_object {
/* The address of the arena, as returned by malloc */
uintptr_t address;
/* Pool-aligned pointer to the next pool to be carved off. */
block* pool_address;
/* The number of available pools in the arena: free pools + never-
* allocated pools.
*/
uint nfreepools;
/* The total number of pools in the arena, whether or not available. */
uint ntotalpools;
/* Singly-linked list of available pools. */
struct pool_header* freepools;
struct arena_object* nextarena;
struct arena_object* prevarena;
};
static struct arena_object* usable_arenas = NULL;
freepools: free 풀 목록을 가리키는 포인터이며, free 풀에는 할당된 블록이 없는 상태이다.
nfreepools: 아레나의 free 풀 수를 나타낸다.
useable_arenas: CPython 은 사용 가능한(empty 또는 used 상태) 풀이 있는 모든 아레나를 추적하기 위해 useable_arena 라는 이중 연결 리스트를 유지 및 관리한다. useable_arenas 리스트는 nfreepools 값의 오름차순으로 정렬된다.
nextarena: 다음 사용 가능한 아레나를 가리키는 포인터
prevarena: useable_arenas 이중 연결 리스트에서 이전 사용 가능한 아레나를 가리키는 포인터
위 그림에서 볼 수 있듯이, useable_arenas 는 nfreepools 를 기준으로 정렬된다.
0개의 free 풀이 있는 아레나가 첫 번째 항목이고, 그 다음에는 1개의 free 풀이 있는 아레나가 위치하는 방식이다.
이는 리스트가 가장 많이 할당된 아레나부터 먼저 위치함을 의미한다. 그 이유는 다음 섹션에서 설명할 것이다.
사용 가능한 아레나 리스트는 어떤 아레나가 가장 많이 할당 되었는지를 기준으로 정렬되므로, 메모리 할당 요청 시 할당이 가장 많은(nfreepools가 가장 적은) 아레나에서 서비스된다.
Does a Python Process Release Memory?
풀에 할당된 블록이 해제되면 CPython은 메모리를 운영체제로 다시 반환하지 않는다. 이 메모리는 계속 Python 프로세스에 속하며, CPython 은 이 블록을 사용하여 새 개체에 메모리를 할당한다.
풀의 모든 블록이 해제되더라도 CPython 은 풀에서 운영체제로 메모리를 반환하지 않는다. CPython 은 자체 사용을 위해 할당되었던 전체 풀의 메모리를 유지한다.
그리고 CPython 은 블록이나 풀 수준이 아닌, 아레나 수준에서 운영체제로 메모리를 해제한다. 이때, 전체 아레나의 메모리를 한 번에 해제함에 유의하자.
메모리는 아레나 수준에서만 해제될 수 있으므로, CPython 은 절대적으로 필요한 경우에만 새로운 메모리 조각에서 아레나를 생성한다. 즉, 항상 이전에 만들었던 블록과 풀에서 메모리를 할당하려고 시도한다.
이것이 useable_arenas 가 nfreepools 의 내림차순으로 정렬된 이유이다.
메모리에 대한 다음 요청은 할당량이 가장 많은(=남은 free 풀 수가 가장 적은) 아레나에 할당됨으로써, 최소한의 데이터가 포함된 아레나의 객체가 삭제되면 빈 공간이 될 수 있으며, 이러한 아레나는 할당 해제되어 운영체제로 메모리를 반환할 수 있다.
운영체제는 컴퓨터 하드웨어 바로 위에 설치되어 사용자 및 다른 모든 소프트웨어와 하드웨어를 연결하는 소프트웨어 계층이다.
그리고 컴퓨터 시스템의 자원을 효율적으로 관리하는데, 이때 자원은 크게 물리적인 자원과 추상적인 자원으로 구분할 수 있다.
물리적인 자원: CPU, 메모리, 디스크, 터미널, 네트워크 등 시스템을 구성하는 요소 및 주변 장치
추상적인 자원:
물리적 자원을 운영체제가 관리하기 위해 추상화 시킨 객체 ex) 태스크(CPU 추상화), 세그먼트와 페이지(메모리 추상화), 파일(디스크 추상화), 통신 프로토콜과 패킷(네트워크 추상화)
물리적인 자원에 대응되지 않으면서 추상적인 객체로만 존재하는 자원 ex) 보안 및 사용자 ID에 따른 접근 제어
운영체제는 일반적으로 커널 뿐만 아니라 각종 주변 시스템 프로그램을 나타내는 개념이지만, 좁은 의미로는 운영체제의 핵심 부분으로 메모리에 상주하는 커널을 의미하기도 한다.
커널은 이러한 자원들을 관리하는 여러 관리자들로 구성되어 있다.
CS746G. Kernel Subsystem Overview
태스크 관리자: 태스크의 생성, 실행, 상태 전이, 스케줄링, 시그널 처리, 프로세스 간 통신 등
메모리 관리자: 물리 메모리 관리, 가상 메모리 관리, 그리고 이들을 위한 세그멘테이션, 페이징, 페이지 폴트 처리 등
파일 시스템: 파일의 생성, 접근 제어, inode 관리, 디렉터리 관리, 수퍼 블록 관리 등
네트워크 관리자: 소켓 인터페이스, TCP/IP 와 같은 통신 프로토콜 등의 서비스 제공
디바이스 드라이버: 디스크나 터미널, CD, 네트워크 카드 등과 같은 주변 장치를 구동하는 드라이버들로 구성된다.
리눅스 소스와 각 디렉터리의 내용을 조금 더 살펴보자면,
linux kernel source
# kernel
커널 핵심 코드를 포함하는 디렉터리로, 태스크 관리자가 구현된 디렉터리이다. 태스크의 생성과 소멸, 프로그램의 실행, 스케줄링, 시그널 처리 등의 기능이 구현되어 있다.
# arch
아키텍쳐 종속적인 코드를 포함하는 디렉터리로, CPU 타입에 따라 하위 디렉터리로 다시 구분된다. /arch/${ARCH} 아래에도 여러 디렉터리가 있다.
/boot: 시스템 부팅 시 사용하는 부트스트랩 코드 구현
/kernel: 태스크 관리자 중에서 문맥 교환이나 스레드 관리 등 구현
/mm: 메모리 관리자 중에서 페이지 폴트 처리 등의 하드웨어 종속적인 부분 구현
/lib: 커널이 사용하는 라이브러리 함수 구현
/math-emu: Floating Point Unit에 대한 에뮬레이터 구현
# fs
리눅스에서 지원하는 다양한 파일 시스템 및 파일 시스템 콜이 구현된 디렉터리로, 다양한 파일 시스템을 사용자가 일관된 인터페이스로 접근할 수 있도록 하는 가상 파일 시스템도 이 디렉터리에 존재한다.
# mm
메모리 관리자가 구현된 디렉터리로, 물리 메모리 관리, 가상 메모리 관리, 태스크마다 할당되는 메모리 객체 관리 등의 기능이 구현되어 있다.
# driver
리눅스에서 지원하는 디바이스 드라이버가 구현된 디렉터리로, 디스크/터미널/네트워크 카드 등 주변 장치를 추상화시키고 관리한다.
블록 디바이스 드라이버: 파일 시스템을 통해 접근
문자 디바이스 드라이버: 사용자 수준 응용 프로그램이 장치 파일을 통해 직접 접근
네트워크 디바이스 드라이버: TCP/IP를 통해 접근
# net
리눅스가 지원하는 통신 프로토콜이 구현된 디렉터리로, 리눅스 커널 소스 중 상당히 많은 양을 차지한다.
# ipc
리눅스 커널이 지원하는 message passing, shared memory, semaphore 등 프로세스 간 통신 기능을 구현한 디렉터리이다.
# init
커널 초기화 부분, 즉 커널의 메인 시작함수가 구현된 디렉터리이다.
하드웨어 종속적인 초기화가 /arch/${ARCH}/kernel 아해의 head.s 와 mics.c에서 이루어진 후,
/init 아래에 구현되어 있는 start_kernel() 으로 커널 전역적인 초기화를 수행한다.
# include
리눅스 커널이 사용하는 헤더 파일들이 구현된 디렉터리로,
헤더 파일들 중에서 하드웨어 독립적인 부분은 /include/linux 아래에 정의되어 있으며
하드웨어 종속적인 부분은 /include/asm-${ARCH} 디렉터리 아래에 정의되어 있다.
# others
documentation: 리눅스 커널 및 명령어들에 대한 자세한 문서 파일 등
lib: 커널 라이브러리 함수들이 구현
scripts: 커널 구성 및 컴파일 시 이용되는 스크립트 정의
리눅스 커널은 위 커널 소스들을 gcc로 컴파일 해서 만들 수 있으며,
리눅스 커널을 만드는 과정은 크게 kernel configuration, kernel compile, kernel installation 세 단계로 이루어진다.
kernel configuration: 새로 만들어질 리눅스 커널에게 현재 시스템에 존재하는 하드웨어 특성, 커널 구성 요소 , 네트워크 특성 등의 정보를 알려주는 과정이다. 커널 구성 단계에서 사용자는 모듈 사용 여부와 시스템 정보, 그리고 시스템에 존재하는 디바이스들의 특성 등에 대한 질문에 답하게 된다. 이러한 선택 사항은 /include/linux/autoconf.h 와 .config 파일에 저장된다.
make config
make menuconfig
make xconfig
커널 구성은 위 명령어 들을 사용해서 할 수 있으며 텍스트 기반 설정인지 gui로 제공되는지 등에 따라 명령어가 나뉜다.
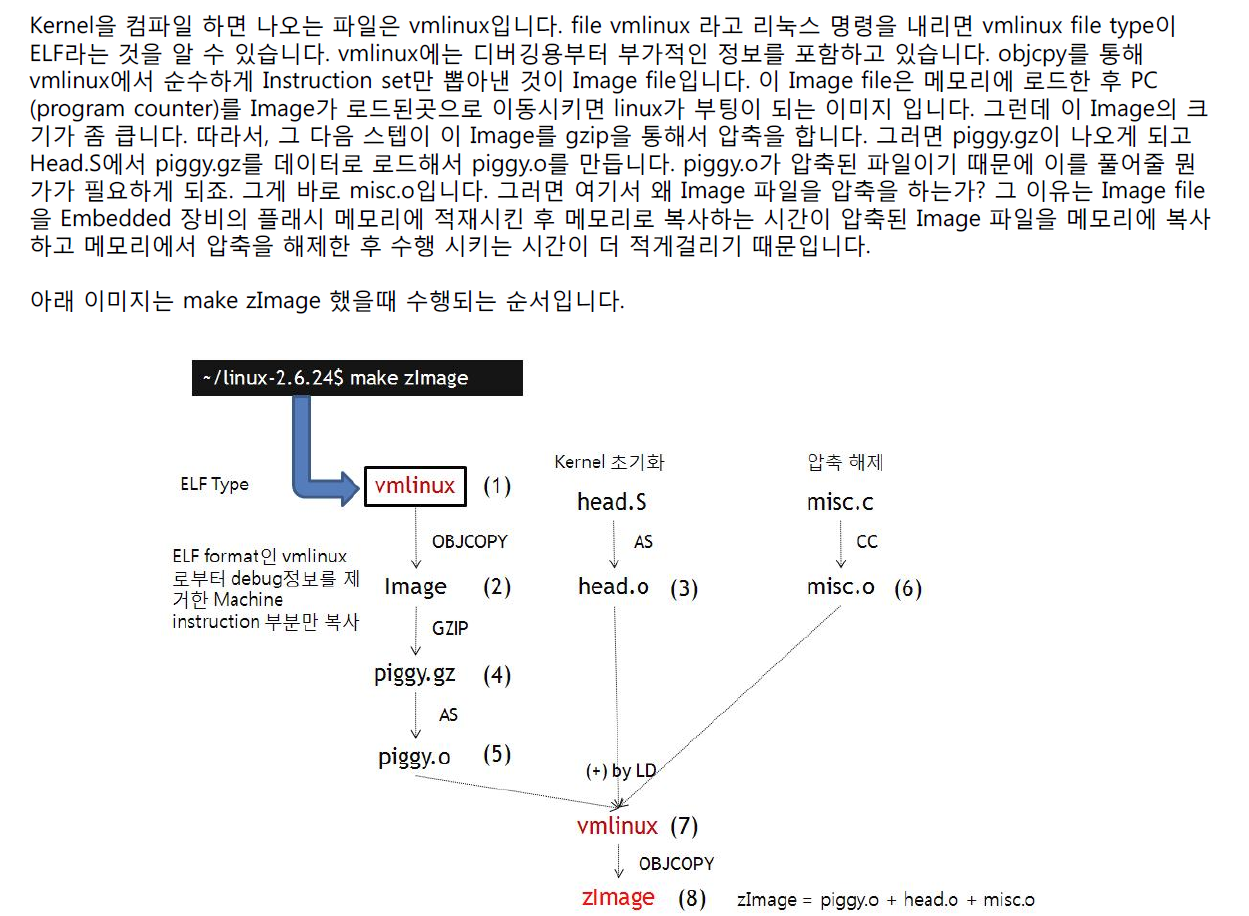
kernel compile: 커널 소스파일을 이용하여 실행가능한 커널을 만들게 되는데, 컴파일 과정에서 아까 만들었던 /include/linux/autoconf.h 와 .config 파일이 사용되며, 커널 컴파일이 끝나면 새로운 커널이 /kernel/arch/${ARCH}/boot 디렉터리에 생성된다.
make bzImage
make zImage
커널 버전 2.6 이후부터는 그냥 `make` 명령어만 사용해도 된다.
bzImage vs zImage? bzImage는 Big zImage를 의미한다.zImage는 최대 크기 512k만 가능한데,커널이 컴파일 후 512k 크기를 넘어가면 bzImage로 만들어야 한다.
kernel installation: 생성된 커널로 시스템이 부팅될 수 있도록 만드는 과정으로, 생성된 커널 이미지를 루트 파일 시스템으로 복사 후 모듈 설치 및 부트 로더 수정을 통해 이루어진다. 이로써 모듈로 구성된 커널 내부 구성 요소를 알려주고, 이후 그 구성 요소들이 사용될 때 자동으로 커널에 적재될 수 있도록 설정하는 단계이다.
make modules: 커널 환경설정에서 모듈로 설정한 기능들을 컴파일
make modules_install: 컴파일 된 모듈을 /lib/modules 아래 설치
아래 그림과 같이 메모리는 각 프로세스가 사용할 뿐만 아니라 커널 자체도 메모리를 사용한다.
메모리의 통계 정보
시스템의 총 메모리의 양과 사용중인 메모리의 양은 `free` 명령어를 통해 확인할 수 있다. (단위는 Kbyte)
free
total: 시스템에 탑재된 전체 메모리 용량
free: 이용하지 않는 메모리
buff/cache: 버퍼 캐시 또는 페이지 캐시가 이용하는 메모리. 시스템의 free 값이 부족하면 커널이 해제한다.
available: 실질적으로 사용 가능한 메모리 = (free) + (buff/cache)
swap
total: 설정된 스왑 총 크기
used: 사용중인 스왑 크기
free: 사용되지 않은 스왑 크기
htop을 사용하면 실시간으로 좀 더 눈에 잘 들어오는 형태로 모니터링 할 수 있다.
htop
메모리 사용량이 늘어나면 free 의 크기가 줄어든다.
이러한 상태가 되면 메모리 관리 시스템은 커널 내부의 해제 가능한 메모리 영역을 해제한다.
이후에도 메모리 사용량이 계속 증하가면 시스템은 메모리가 부족해 동작할 수 없는 메모리 부족 상태가 된다 = Out of Memory
이러한 경우 메모리 관리 시스템에서는 적절한 프로세스를 강제 종료(kill) 시켜 메모리 영역을 해제한다.
메모리 주소의 할당
커널이 프로세스에 메모리를 할당하는 경우는 크게 두 가지 타이밍에 벌어진다.
1. 프로세스를 생성할 때
2. 프로세스를 생성한 뒤 추가로 동적 메모리를 할당할때
좀 더 자세히 살펴보자.
[운영체제 10판] 9장 메인 메모리
c.f. 파이썬의 경우 인터프리터 언어라서 조금 다를 수 있을 것 같아서 찾아보니, https://stackoverflow.com/questions/19791353/linking-and-loading-in-interpreted-languages - 파이썬은 컴파일 과정이 없다. - 실행 파일(예: /usr/bin/python)이 실제로 실행되는 프로그램이고, 실행할 스크립트를 읽으며 한 줄씩 실행하게 된다. - 그 과정에서 다른 파일이나 모듈(예: /usr/python/lib/math.py)에 대한 참조를 만날 수 있으며 그 때, 이를 읽고 해석한다. - 바이너리 라이브러리들은 런타임에 코드에서 요청 시, 해당 라이브러리를 로드한 다음 사용할 수 있다. - 파일을 처음 실행할 때 바이트코드(.pyc 파일)로 컴파일되고, 다음에 모듈을 가져오거나 실행할 때 코드 실행이 향상된다.
물리 주소를 논리 주소로 변환하는 방법
[운영체제 10판] 9장 메인 메모리
Dynamic Loading: 프로세스가 실행되기 위해 프로세스 전체가 메모리에 미리 올라와 있을 필요는 없다. 메모리 공간을 더 효율적으로 이용하기 위해 동적 적재를 할 수 있다. 동적 적재에서 각 루틴은 실제 호출 전까지 메모리에 올라오지 않고 재배치 가능한 상태로 디스크에 대기하고 있다. 동적 적재는 운영 체제로부터 특별한 지원이 필요없으며, 사용자 자신이 프로그램의 설계를 책임져야 한다. 운영체제는 동적 적재를 구현하는 라이브러리 루틴을 제공해 줄 수는 있다.
예: main 프로그램이 메모리에 올라와 실행된다. 이 루틴이 다른 루틴을 호출하게 되면 호출한 루틴이 이미 메모리에 적재됐는지 조사한다. 만약 적재되어 있지 않으면 재배치 가능 연결 적재기(relocatable linking loader)가 불려 요구된 루틴을 메모리로 가져오고, 이러한 변화를 테이블에 기록해둔다. 그 후 CPU 제어는 중단되었던 루틴으로 보내진다.
Dynamic Linking and Shared Library: 동적 연결 라이브러리(DLL)은 사용자 프로그램이 실행될 때, 사용자 프로그램에 연결되는 시스템 라이브러리이다. 동적 연결에서는 linking이 실행 시기까지 미루어진다. 동적 연결은 주로 표준 C 언어 라이브러리와 같은 시스템 라이브러리에 사용된다. DLL은 여러 프로세스 간 공유될 수 있어 메일 메모리에 DLL 인스턴스가 하나만 있을 수 있으며 공유 라이브러리라고도 한다. 프로그램이 동적 라이브러리에 있는 루틴을 참조하면 로더는 DLL을 찾아 필요한 경우 메모리에 적재한다. 그런 다음 동적 라이브러리의 함수를 참조하는 주소를 DLL이 저장된 메모리의 위치로 조정한다. 동적 로딩과 달리 동적 연결과 공유 라이브러리는 일반적으로 운영체제의 도움이 필요하다. 메모리에 있는 프로세스들이 각자의 공간을 자기만 엑세스 할 수 있도록 보호된다면 운영체제만이 메모리 공간에 루틴이 있는지 검사해 줄 수 있고, 운영체제만이 여러 프로세스가 같은 메모리 주소를 공용할 수 있도록 해줄 수 있다.
c.f. 정적 연결(static linking): 라이브러리가 프로그램의 이진 프로그램 이미지에 끼어 들어간다.
동적 메모리를 할당할 때, 추가적으로 메모리가 필요한 경우 프로세스는 커널에 메모리 확보용 시스템 콜을 호출하여 메모리 할당을 요청한다. 커널은 메모리 할당 요청을 받으면 필요한 사이즈를 빈 메모리 영역으로부터 잘라내, 그 영역의 시작 주소값을 반환한다.
논리 주소를 물리 주소로 변환하는 방법
가상 주소를 물리 주소로 변환하는 과정은 커널 내부에 보관되어 있는 `페이지 테이블`을 사용한다.
가상 메모리는 전체 메모리를 페이지 단위로 나누어 관리하고 있으므로 변환은 페이지 단위로 이루어진다.
(c.f. 물리 메모리는 프레임 단위로 불리는 동일한 크기의 블록으로 나누어진다.)
이때, 페이지 사이즈는 CPU 구조에 따라 다른다. 흔히 사용하는 x86_64의 페이지 사이즈는 4kb이다.
리눅스 시스템에서 페이지 크기를 알아내고 싶다면 `getconf PAGESIZE` 명령을 입력하면 된다. (단위는 바이트)
CPU 에서 나오는 모든 주소는 (페이지 번호) + (페이지 오프셋) 두 개의 부분으로 나누어진다.
페이지 번호: 페이지 테이블 접근 시 사용된다. 페이지 테이블은 물리 메모리의 각 프레임 시작 주소를 저장한다.
페이지 오프셋: 참조되는 프레임 안에서의 위치를 나타낸다.
만약 페이지 테이블에 매핑되지 않은 영역대의 가상 주소에 접근하게 되면 CPU 에는 `페이지 폴트` 인터럽트가 발생한다.
페이지 폴트에 의해 현재 실행 중인 명령이 중단되고, 커널 내의 `페이지 폴트 핸들러` 라는 인터럽트 핸들러가 동작하게 된다.
커널은 프로세스로부터 메모리 접근이 잘못되었다는 내용을 페이지 폴트 핸들러에 알려준 후, `SIGSEGV` 시그널을 프로세스에 통지한다. (이 시그널을 받은 프로세스는 강제 종료된다.)
실제 메모리 할당(Linux)
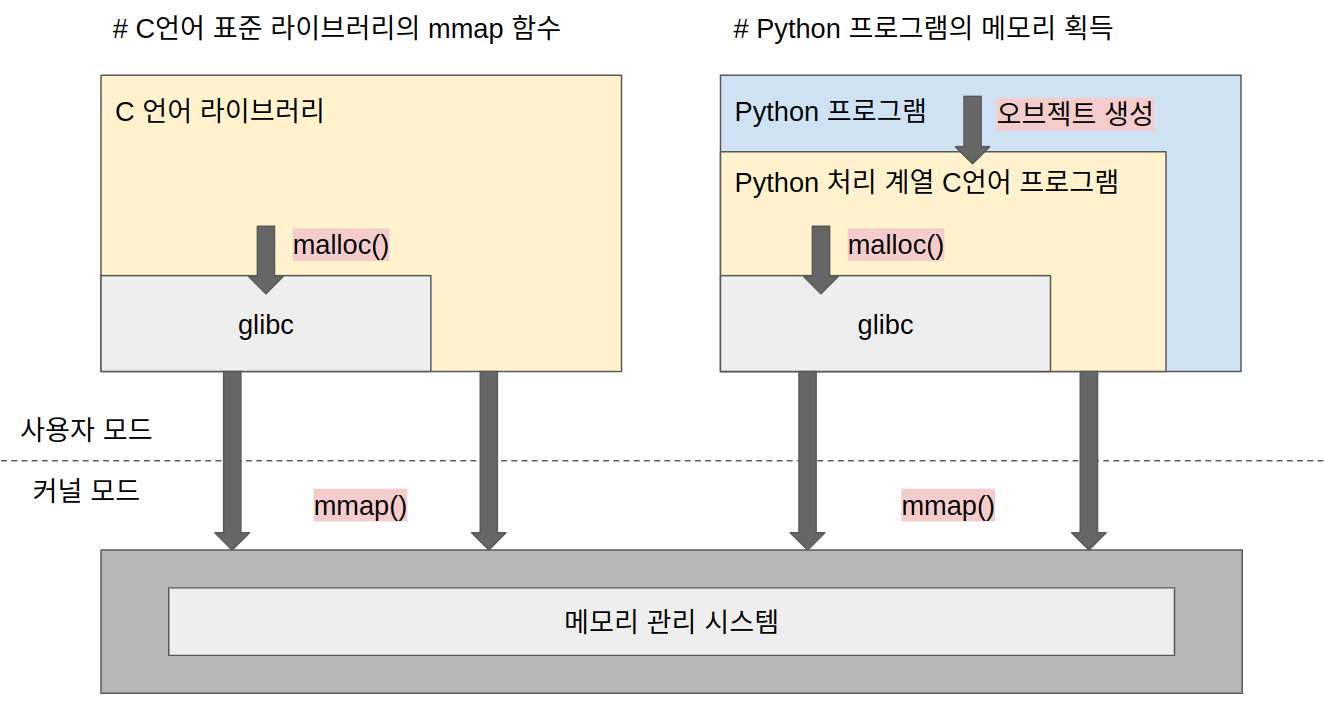
## C
C언어에서는 표준 라이브러리에 있는 `malloc()` 함수가 메모리 확보 함수이다.
리눅스에서는 내부적으로 `malloc()` 함수에서 `mmap()` 또는 `brk()` 함수를 호출하여 메모리 할당을 구현한다.
## Python
파이썬같이 직접 메모리 관리를 하지 않는 스크립트 언어의 오브젝트 생성에도
최종적으로는 내부에서 C언어의 malloc 함수를 사용하고 있다.
mmap 함수는 페이지 단위로 메모리를 확보하지만, malloc 함수는 바이트 단위로 메모리를 확보한다.
즉, glibc에서는 사전에 mmap 시스템 콜을 이용하여 메모리 풀을 확보한 뒤, 프로그램에서 malloc이 호출되면 메모리 풀로부터 필요한 양을 바이트 단위로 잘라내어 반환하는 처리를 한다. 풀로 만들어 둔 메모리에 더 이상 빈 공간이 없으면 다시 mmap 을 호출하여 새로운 메모리 영역을 확보한다.
glibc의 메모리 풀
사용하는 메모리 양을 체크하여 알려주는 기능의 프로그램들이 있으나, 그 프로그램이 알려주는 사용량과 실제 리눅스에서 사용하는 메모리의 양이 서로 다른 경우가 매우 많다. (일반적으로 리눅스에서 프로세스가 사용하는 메모리 양이 더 많음)
왜냐하면 리눅스에서 측정한 메모리 양은 프로세스가 생성될 때, mmap 함수를 호출했을 때 할당한 메모리 전부를 더한 값을 나타내고, 프로그램이 체크한 메모리 사용량은 malloc 함수 등으로 획득한 바이트 수의 총합을 나타내기 때문에 서로 다르게 표시되기 때문이다. 이러한 프로그램이 체크한 메모리 사용량이 정확히 무엇을 나타내는지는 프로그램에 따라 다르므로 확인해봐야 한다.
분산 된 협업 하이퍼 미디어 정보 시스템을위한 애플리케이션 수준 프로토콜, 쉽게 말하면 인터넷(W3) 상에서 정보를 주고 받는 약속이다.
HTTP 프로토콜은 요청/응답 프로토콜로, 클라이언트는 요청 메서드, URI 및 프로토콜 버전의 형태로 서버에 요청을 보낸 다음 서버와의 연결을 통해 요청 수정 자, 클라이언트 정보 및 가능한 본문 내용을 포함하는 MIME 유사 메시지를 보낸다. 서버는 메시지의 프로토콜 버전과 성공 또는 오류 코드를 포함한 상태 표시 줄로 응답 한 다음 서버 정보, 엔티티 메타 정보 및 가능한 엔티티 본문 내용이 포함 된 MIME와 유사한 메시지를 표시한다.
HTTP 프로토콜의 경우는 이론적으로 신뢰성 있는 연결만 해 줄 수 있다면 전송 프로토콜을 어떤 것을 써도 괜찮다고 한다.
HTTP 프로토콜의 특성을 알아보기 위해 먼저 전송 프로토콜에 대해 알아보자면
TCP(Transmission Control Protocol)
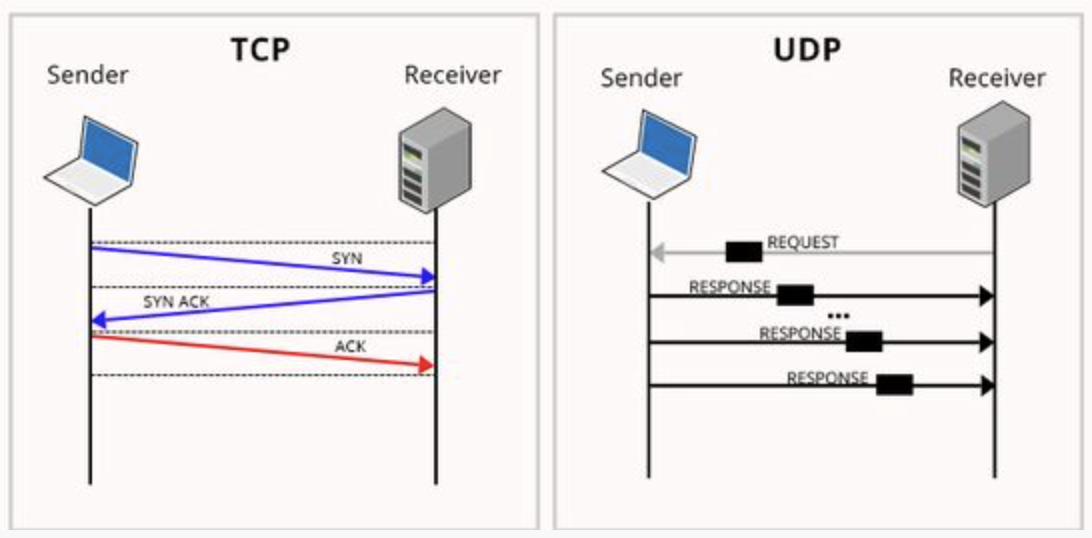
tcp는 신뢰성 있는 connection을 만들기 위해 먼저 3way handshaking을 한다. (연결형 서비스)
패킷 교환 방식은 가상 회선 방식(virtual circuit)이다.
경로를 먼저 설정하고 패킷을 보낸다.
각 패킷에는 가상회선 식별 번호(VCI)가 포함되고, 모든 패킷을 전송하면 가상회선이 해제되고 패킷들은 전송된 순서대로 도착한다. ⇒ 전송 순서를 보장
데이터를 전송하기 전에 논리적 연결이 설정되지 않으며 패킷이 독립적으로 전송(데이터 그램)된다.
패킷을 수신한 라우터는 최적의 경로를 선택하여 패킷을 전송하는데 하나의 메시지에서 분할된 여러 패킷은 서로 다른 경로로 전송될 수 있다.
송신 측에서 전송한 순서와 수신 측에 도착한 순서가 다를 수 있다. ⇒ 전송 순서 보장X
신뢰성을 전혀 신경쓰지 않고 일단 보낸다. 그 때문에 전송 속도가 빠르다.
HTTP/0.9 ~ HTTP/2까지는 TCP 전송 프로토콜을 사용한다.
1. HTTP/0.9: 인터넷을 통한 원시 데이터 전송을위한 간단한 프로토콜
1) 요청은 GET이 유일하다
GET /mypage.html
2) HTTP 헤더가 없다. 즉, HTML 파일만 전송 가능하며 다른 유형의 문서는 전송 될 수 없다
3) 상태/오류 코드가 없었기 때문에 특정 HTML 파일이 사람이 처리할 수 있도록, 해당 파일 내부에 문제에 대한 설명과 함께 되돌려 보내졌다.
<HTML>
A very simple HTML page
</HTML>
2. HTTP/1.0
1) 통신을 할 때마다 3 way handshaking
2) 버전 정보가 각 요청 사이내로 전송 되었다. HTTP 헤더도 보낼 수 있게 되었다.
HTTP 헤더: 요청/응답 모두를 위해 도입되어, 메타데이터 전송을 허용하고 프로토콜을 유연하고 확장 가능하도록 했다.
Content-Type 응답 헤더: HTML 파일들 외에 다른 문서들을 전송하는 기능이 추가됨
GET /mypage.html HTTP/1.0
User-Agent: NCSA_Mosaic/2.0 (Windows 3.1)
3) 상태 코드 라인 또한 응답의 시작 부분에 붙어 전송되어, 브라우저가 요청에 대한 성공과 실패를 알 수 있으며, 그 결과에 대한 동작(특정 방법으로 그것의 로컬 캐시를 갱신하거나 사용하는 것과 같은)을 할 수 있게 되었다.
200 OK
Date: Tue, 15 Nov 1994 08:12:31 GMT
Server: CERN/3.0 libwww/2.17
Content-Type: text/html
<HTML>
A page with an image
<IMG SRC="/myimage.gif">
</HTML>
각각의 HTTP 요청은 각각의 커넥션 상에서 실행된다. 이는 TCP handshake는 각 HTTP 요청 전에 발생하고, 각 요청은 순서대로 실행됨을 알 수 있다.
TCP handshake는 그 자체로 시간을 소모하기는 하지만, 지속적으로 연결되었을 때 부하에 맞춰 예열되어 더욱 효율적으로 작동한다. 단기 커넥션들은 TCP의 이러한 효율적인 특성을 사용하지 못하며 예열되지 않은 새로운 연결을 통해 지속적으로 전송함으로써 성능이 저하된다.
이 모델은 HTTP/1.0에서 사용된 기본 모델이며, (Connection헤더가 존재하지 않거나, 그것의 값이 close로 설정된 경우) HTTP/1.1에서 short-lived 모델은 Connection헤더가close 값으로 설정되어 전송된 경우에만 사용된다.
단점 = 새로운 연결을 맺는데 드는 시간이 상당하다 + TCP기반 커넥션의 성능은 오직 커넥션이 예열된 상태일 때만 나아지는데, 한 커넥션에 한 요청&응답만 이루어진다.
⇒ 암튼 HTTP/1.0은 매번 새로운 연결로 성능 저하, 서버 부하 비용 UP
HTTP/1.1
HTTP/1.0보다 더 엄격한 요구 사항을 포함한다.
또한, HTTP/1.0 커넥션은 기본적으로 영속적이지 않다. Connection를 close가 아닌 다른 것(ex. retry-after)으로 설정하면 영속적으로 동작할 수 있다.
HTTP/1.1에서는 기본적으로 영속적이며 헤더도 필요하지 않다(단, HTTP/1.0으로 동작하는 경우(fallback)에 대비해서 종종 추가하기도 함)
1) 요청의 목적을 나타내는 개방형 메소드 및 헤더 세트를 허용하며 메시지는 MIME 타입
GET /en-US/docs/Glossary/Simple_header HTTP/1.1
Host: developer.mozilla.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:50.0) Gecko/20100101 Firefox/50.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br
Referer: https://developer.mozilla.org/en-US/docs/Glossary/Simple_header
2) 자원을 나타 내기 위해 위치(URL) 또는 이름(URN)으로 URI (Uniform Resource Identifier)에서 제공하는 참조 분야를 기반으로 한다.
3) HTTP는 또한 SMTP, NNTP, FTP, Gopher, WAIS에서 지원하는 것을 포함하여 사용자 에이전트와 프록시/게이트웨이 간의 다른 인터넷 시스템 간의 통신을위한 일반 프로토콜로 사용된다.
4) HTTP/1.1에는 두 가지 모델이 추가되었다.
Persistent connection 모델(keep-alive connection): 지정한 타임 아웃 동안 커넥션을 닫지 않는 방식으로, 연속적인 요청 사이에 커넥션을 유지하여 재사용, 새 커넥션을 여는데 필요한 시간을 줄인다.
새로운 TCP 핸드셰이크를 하는 비용을 아끼고, TCP의 성능 향상 기능을 활용할 수 있다.
커넥션은 영원히 열려있지는 않다(서버는Keep-Alive헤더로 연결이 최소한 얼마나 열려있어야 할지를 설정할 수 있다)
단점: 아무것도 보내지 않는 상태일때에도 서버 리소스를 소비하며, 과부하 상태에서는DoS attacks을 당할 수 있다.
HTTP 파이프라이닝: 한 단계 더 나아가, 하나의 커넥션에서 응답조차도 기다리지 않고 순차적인 여러 요청을 연속적으로 보낸 후 그 순서에 맞추어 응답을 받는 방식으로 네트워크 지연을 더욱 줄인다. 커넥션이 재사용될 수 있게 하여, 탐색된 단일 원본 문서 내로 임베드된 리소스들을 디스플레이하기 위해 사용된 커넥션을 다시 열어 시간을 절약하게 했다. 첫번째 요청에 대한 응답이 완전히 전송되기 이전에 두번째 요청 전송을 가능케 하여, 커뮤니케이션 latency를 낮췄다.
모든 종류의 HTTP 요청이 파이프라인으로 처리될 수 있는 것은 아니다:GET,HEAD,PUT그리고DELETE와 같은idempotent메서드만 가능하다. 실패가 발생한 경우에는 단순히 파이프라인 컨텐츠를 다시 반복하면 된다.
이 때, HTTP 내 커넥션 관리가 end-to-end가 아닌 hop-by-hop라는 점. 따라서 클라이언트와 첫 번째 프록시 사이의 커넥션 모델은 프록시와 최종 목적 서버(혹은 중간 프록시들) 간의 것과는 다를 수도 있다. Connection과 Keep-Alive와 같이 커넥션 모델을 정의하는 데 관여하는 HTTP 헤더들은 hop-by-hop 헤더이며, 중간 노드에 의해 그 값들이 변경될 수 있다.
5) Content-Length - 청크된 응답이 지원된다. 즉, 서버측에서 html을 전부 생성한 후에 클라이언트에게 보내는 것이 아니라 html을 덩어리(chunk) 단위로 쪼개서 보낼 수 있다. 브라우저에게 전체 컨텐츠 크기가 얼마나 큰지 알려주지 않아도된다. 따라서, 동적인 크기의 컨텐츠나 스트리밍에 적합하다. 이러한 방식의 응답은 Chunked transfer encoding을 사용해야함.
6) 추가적인 캐시 제어 메커니즘이 도입되었다.
7) 언어, 인코딩, 타입 등으로 클라이언트와 서버로 교환하려는 가장 적합한 컨텐츠에 대해 서로 알 수 있게 해 준다.
8) Host 헤더 덕분에, 동일 IP 주소에 다른 도메인을 호스트하는 기능이 서버 colocation을 가능하도록 한다.
이론적으로는 모든 HTTP/1.1 호환 프록시와 서버들이 파이프라이닝을 지원해야 하지만, 파이프라이닝 방식에는 치명적인 문제점이 있다.
파이프라이닝은 정확히 구현해내기 복잡하다: 전송 중인 리소스의 크기, 사용될 효과적인 RTT, 그리고 효과적인 대역폭은 파이프라인이 제공하는 성능 향상에 직접적으로 영향을 미친다. 이런 내용을 모른다면, 중요한 메시지가 덜 중요한 메시지에 밀려 지연될 수 있다.
파이프라이닝은 HOL 문제에 영향을 받는다.
HOL (Head Of Line) Blocking -특정 응답의 지연
이전 요청이 서버에서 처리하는 시간이 길 경우 그 이후의 요청도 기다려야 한다는 점이다.
즉, 네트워크에서 같은 큐에 있는 패킷이 첫번째 패킷에 의해 지연될 때 발생하는 성능 저하 현상으로, 이 때문에 패킷의 처리 속도는 지연 되고, 최악의 경우 드랍까지 발생할 수 있다.
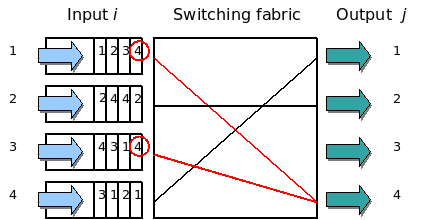
그림을 자세히 보면 보통의 스위치는 패킷을 받는 input, input을 지난 후의 Switching fabric, Switching fabric을 지난 후의 output, 총 세 부분으로 나누어져 있다. 패킷이 input에 들어오면 Switching fabric을 거쳐 output에 도달하게 된다. 첫번째 input과 세번째 input은 동일한 인터페이스(output 4)로 패킷을 보내려고 하는데, 만약 이 경우 Switching fabric에서 세번째 input의 패킷을 먼저 처리를 해버리면, 첫번째 input의 패킷을 인터페이스(output 4)로 보내지 못하게 된다.
또 다른 문제점은 Header 구조의 중복이다.
연속된 요청의 경우에는 헤더의 값이 같은 경우가 많음에도 불구하고, 중복된 헤더 값을 그냥 전송하게 된다.
HTTP/2
이런 이유들로, 파이프라이닝은 더 나은 알고리즘인 멀티플렉싱으로 대체되었는데, 이는 HTTP/2에서 사용된다.
2010년 전반기에, Google은 실험적인 SPDY 프로토콜을 구현하여, 클라이언트와 서버 간의 데이터 교환을 대체할 수단을 실증하였습니다. 그것은 브라우저와 서버 측 모두에 있어 많은 관심을 불러일으켰습니다. 응답성 증가 능력을 입증하고 전송된 데이터 중복에 관한 문제를 해결하면서, SPDY는 HTTP/2 프로토콜의 기초로써 기여했습니다.
1) 메세지 전송 방식에 변화가 생겼다. 기존에는 일단 텍스트 형식의 메세지를 사용했다면,
HTTP/2에서는 메세지를 프레임이라는 단위로 분할하고 바이너리로 인코딩을 하게 된다.
⇒ 클라이언트와 서버는 서로를 이해하기 위해 새 바이너리 인코딩 메커니즘을 사용해야 한다.
⇒ HTTP/1.x ↔ HTTP/2 서로를 이해하지 못함
⇒ 컴퓨터는 바이너리를 텍스트보다 더 잘 처리할 수 있기 때문에, 파싱/전송속도는 높아지고 오류 발생 가능성은 낮아지게 된다.
2) 새 바이너리 프레이밍 메커니즘이 도입됨에 따라 클라이언트와 서버 간에 데이터 교환 방식이 바뀌었다.
⇒요청과 응답이 다중화가 가능해 졌다.
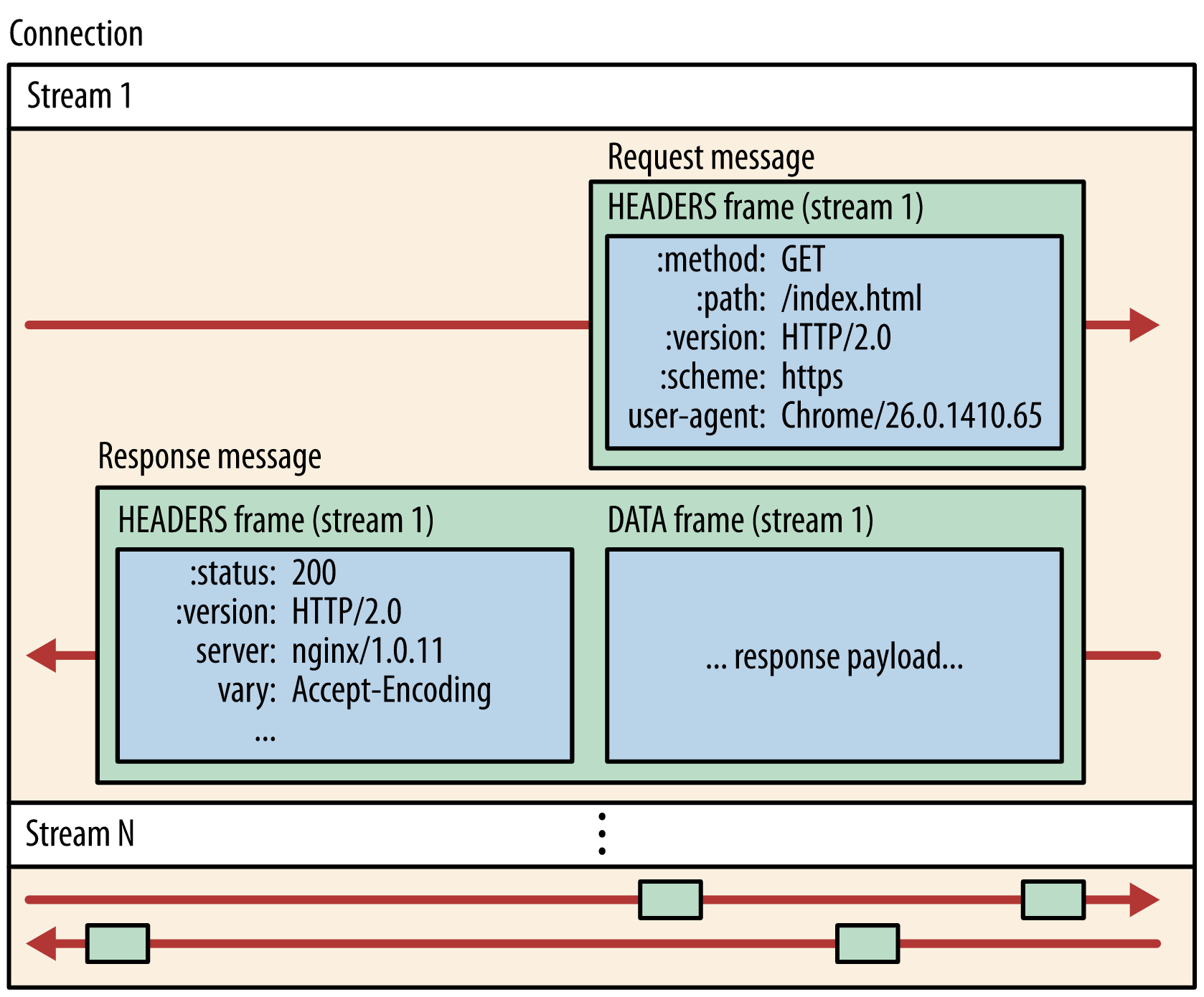
아래 그림과 같이 만든 프레임을 클라이언트와 서버 안에 연결되는 커넥션 안에 스트림이라는 데이터 양방향 흐름이 있는데,
그 안에 프레임들이 들어가서 조각 조각이 요청이나 응답 메세지가 되는 것이다.
프레임으로 쪼개졌기 때문에 메세지 간의 순서라는 것이 사라졌다.
또한 프레임이 인터리빙이라는 끼어드는 방식이 가능하기 때문에 ⇒ HOL 블로킹 해결
정리하면, 클라이언트와 서버가 HTTP 메시지를 독립된 프레임으로 세분화하고, 이 프레임의 순서를 바꿈으로서(인터리빙), 다른 쪽에서 다시 조립하도록 허용한다.
위 그림을 보면 한 커넥션 안에 여러 스트림이 있을 수 있다는 것을 알 수 있다. 클라이언트는 데이터 프레임(스트림 5)을 서버로 전송 중인 반면, 서버는 스트림 1과 스트림 3의 인터리빙된 프레임 시퀀스를 클라이언트로 전송 중이다. 따라서 3개의 병렬 스트림이 존재한다.
3) Stream Priortization이라는 리소스 간 우선 순위를 설정할 수 있다.(스트림에 가중치를 둘 수 있다)
스트림의 종속성 및 가중치 조합을 이용하여 클라이언트가 '우선순위 지정 트리'를 구성하고 통신할 수 있다. 이 트리는 클라이언트가 선호하는 응답 수신 방식을 나타내는데, 서버가 이 정보를 사용하여 CPU/메모리/기타 리소스의 할당을 제어함 으로써 스트림 처리의 우선순위를 지정한다.
응답 데이터가 있는 경우, 서버는 우선순위가 높은 응답이 먼저 전달되도록 대역폭을 할당한다.
HTTP/2 내에서 스트림 종속성은 상위 요소로 참조하는 방식으로 선언된다. 아무것도 없으면 '루트 스트림' 이다. 이 그림에서는 예를 들어 '응답 C보다 먼저 응답 D를 처리하고 전달해야 한다'는 의미를 가진다
4) Server Push라는 기능도 생겼다.
클라이언트가 요청하지도 않은 리소스를 서버에서 알아서 보내줄 수 있는 기능이다.
즉, 서버는 원래 요청에 응답할 뿐만 아니라 클라이언트가 명시적으로 요청하지 않아도 서버가 추가적인 리소스를 클라이언트에 푸시할 수 있다
위 그림에서 page.html 안에는 script.js와 style.css가 포함되어 있다고 하자.
서버는 page.html을 요청받으면 그 내부에 필요한 script.js, style.css도 함께 캐싱해둔다.
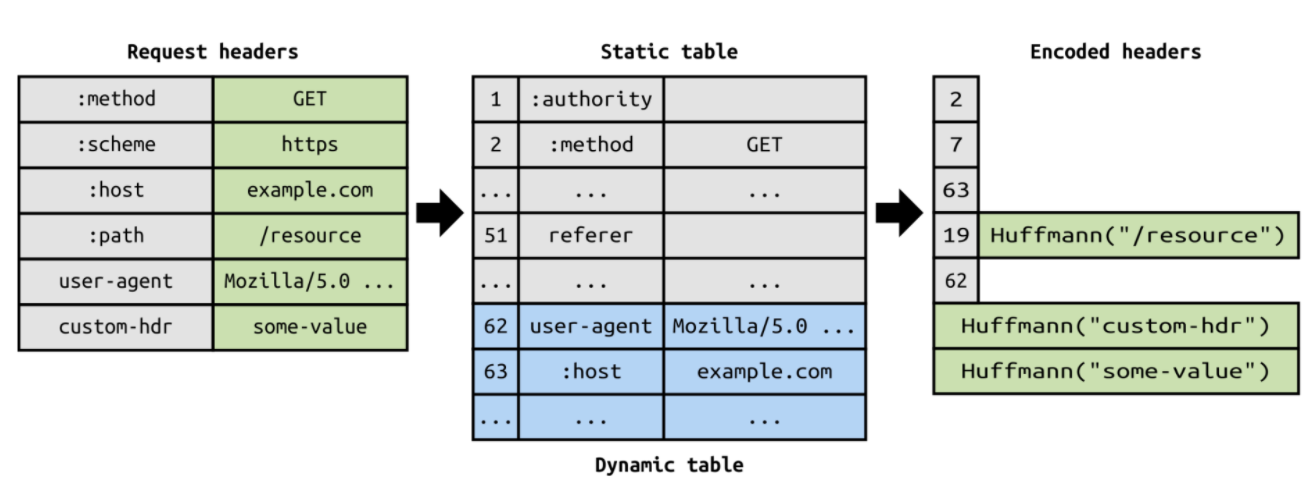
5) Header Compression, 즉 헤더의 크기를 줄여 페이지 로드 시간을 줄이는 기능이 있다
헤더를 압축하기 위한 방법은 아래와 같다. Static Dynamic Table이라는 개념을 도입하여 중복을 검출해서 중복된 것은 인덱스만 뽑고, 중복되지 않은 것은 허프만 인코딩을 해서 위와 같이 압축하게 된다.
결론) 차이점을 정리해 보면...
HTTP/2는 HTTP/1.1을 완전하게 재작성한 것이 아니라 프로토콜의 성능에 초점을 맞추어 수정한 버전이라고 생각하면 된다.
특히 End-user가 느끼는 latency나 네트워크, 서버 리소스 사용량 등과 같은 성능 위주로 개선했다.
1) HTTP/1.1는기본적으로Connection당하나의요청을처리하도록설계했고, 그 때문에 동시전송이 불가능하고 요청과응답이순차적으로이루어 진다. Persistent Connection과 Pipelining 구조를 도입했으나 다수의 리소스(Images, CSS, Script 등)를 처리하려면 요청할리소스개수에비례해서 대기시간이길어진다.
HTTP/2의 경우 한 커넥션으로 동시에 여러 개의 메세지를 주고 받을 있으며, 응답은 순서에 상관없이 stream으로 주고 받는다.
⇒ HTTP/1.1의 Connection Keep-Alive, Pipelining의 개선
2) HTTP/1.1은 텍스트 기반 프로토콜이고,
HTTP/2는 바이너리 프로토콜이다 (애플리케이션 헤더에 무엇을 어떻게 쓸지에 대한 차이)
텍스트 프로토콜
장점: 요구조건 구현이 용이하며, 관리 및 디버깅이 쉽다. 기존의 텍스트 기발 프로토콜에 내장하기 쉽기 때문에 확장성이 좋다
단점: 바이너리 데이터의 내장이 어려울 수 있다. 더 많은 공간을 요구하며, 네트워크 대역폭을 많이 차지한다. 파싱 속도가 느리다.
바이너리 프로토콜:
장점: 적은 공간을 차지하므로 네트워크 대역폭을 적게 차지하고, 파싱 속도가 빠르다. 바이너리 데이타의 내장이 용이하다.
단점: 텍스트 프로토콜에 비해 구현이 어려울 수 있고 확장성, 가독성이 떨어지기 때문에 관리와 디버깅이 어렵다. 기존의 텍스트 기반 프로토콜에 내장하기 힘들다.
3) HTTP/1.1 커넥션은 올바른 순서로 전송되는 요청을 필요로 한다. 몇몇 병렬 커넥션이 이론적으로 사용 가능한 경우도 여전히 많은 양의 오버헤드와 복잡도가 남아 있다. (ex)HTTP 파이프라이닝, Head Of Line Blocking의 발생 가능성)
HTTP/2의 경우 병렬 요청이 동일한 커넥션 상에서 다루어질 수 있는 다중화 프로토콜로, 순서를 제거해주고 HTTP/1.x 프로토콜의 제약사항을 막아준다. 리소스간 우선 순위를 설정 할 수 있다. TCP 기반이기 때문에 TCP의 HOL blocking은 여전히 존재한다.
4) HTTP/1.1 헤더에는 많은 메타정보들이 저장되는데, 사용자가 방문한 웹페이지는 다수의 HTTP 요청이 발생하게 된다. 이 경우 매 요청 시마다 중복된 헤더값을 전송하게 되고, 해당 도메인에 설정된 cookie 정보도 매 요청시 헤더에 포함되므로 전송하려는 값보다 헤더 값이 더 클 수가 있다.
HTTP/2의 경우는 전송된 데이터의 분명한 중복과 그런 데이터로부터 유발된 불필요한 오버헤드를 제거하면서, 연속된 요청 사이의 매우 유사한 내용으로 존재하는 헤더들을 압축시킨다.
5) 클라이언트가 HTML 문서를 요청할 시 해당 HTML에 여러개의 리소스(CSS, Image 등)가 포함될 경우
HTTP/1.1는 HTML문서를 해석하기 위해 필요한 리소스를 재 요청할 수 있다.
HTTP/2는 서버로 하여금 사전에 클라이언트 캐시를 서버 푸쉬라고 불리는 메커니즘에 의해, 재 요청 없이 필요하게 될 데이터로 채워넣도록 허용한다.
6) HTTP/1.1 커넥션이 TLS/1.0이나 WebSocket, 혹은 평문 HTTP/2와 같은 다른 프로토콜로 업그레이드 되었다고 보면 된다.
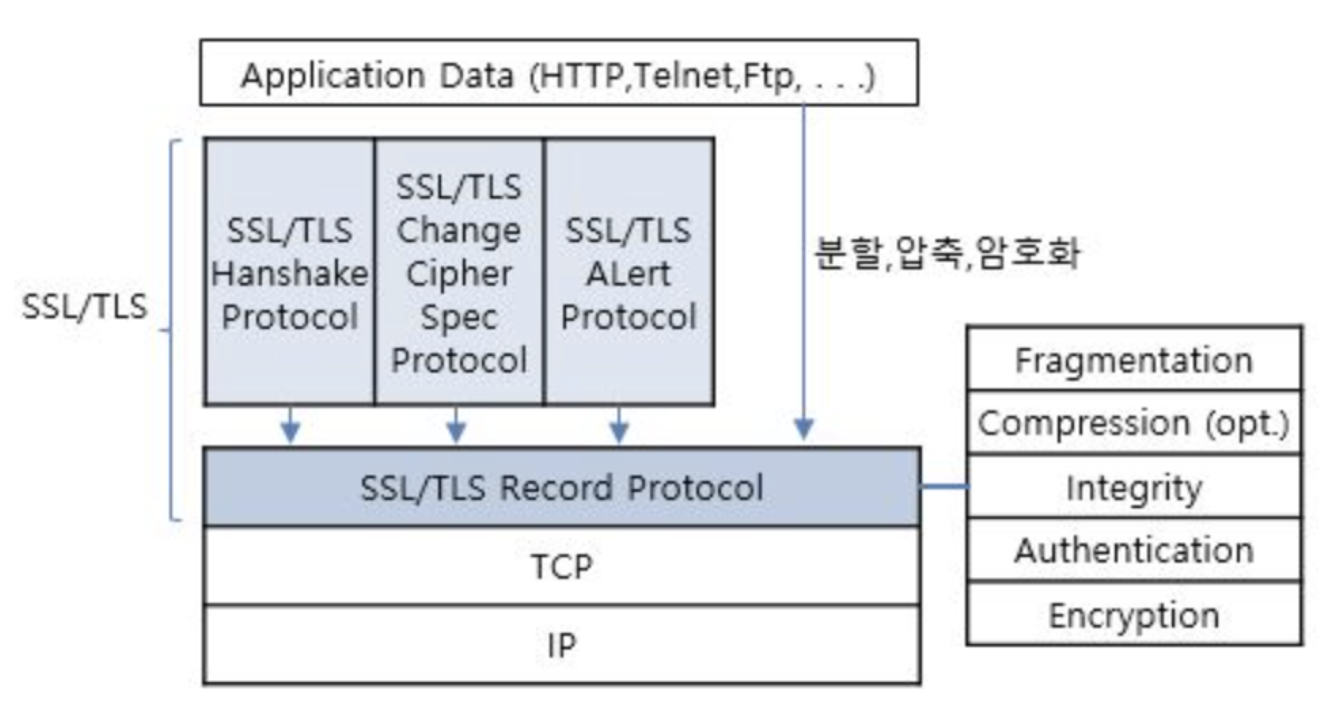
TLS(Transport Layer Security: 전송 계층 보안)
TLS가 도입되게 된 배경
1) 호스트 사이에 거쳐야 할 부분이 너무 많다. 이 거치는 지점(프록시 서버, 공유기, 네트워크 장비 등)에서도 요청&응답을 볼 수 있다는 문제점
2) 내가 통신하고 있는 상대방이 진짜 내가 원했던 상대방인지 알 수 없다. (중간에 있는 서버가 호스트인 것처럼 속이고 요청을 가로채서 응답하는 경우)
3) 요청을 보내서 상대방이 받는 도중 요청이 변조될 수 있고, 이 변조가 발생했는지 당사자들이 알 수 없다.
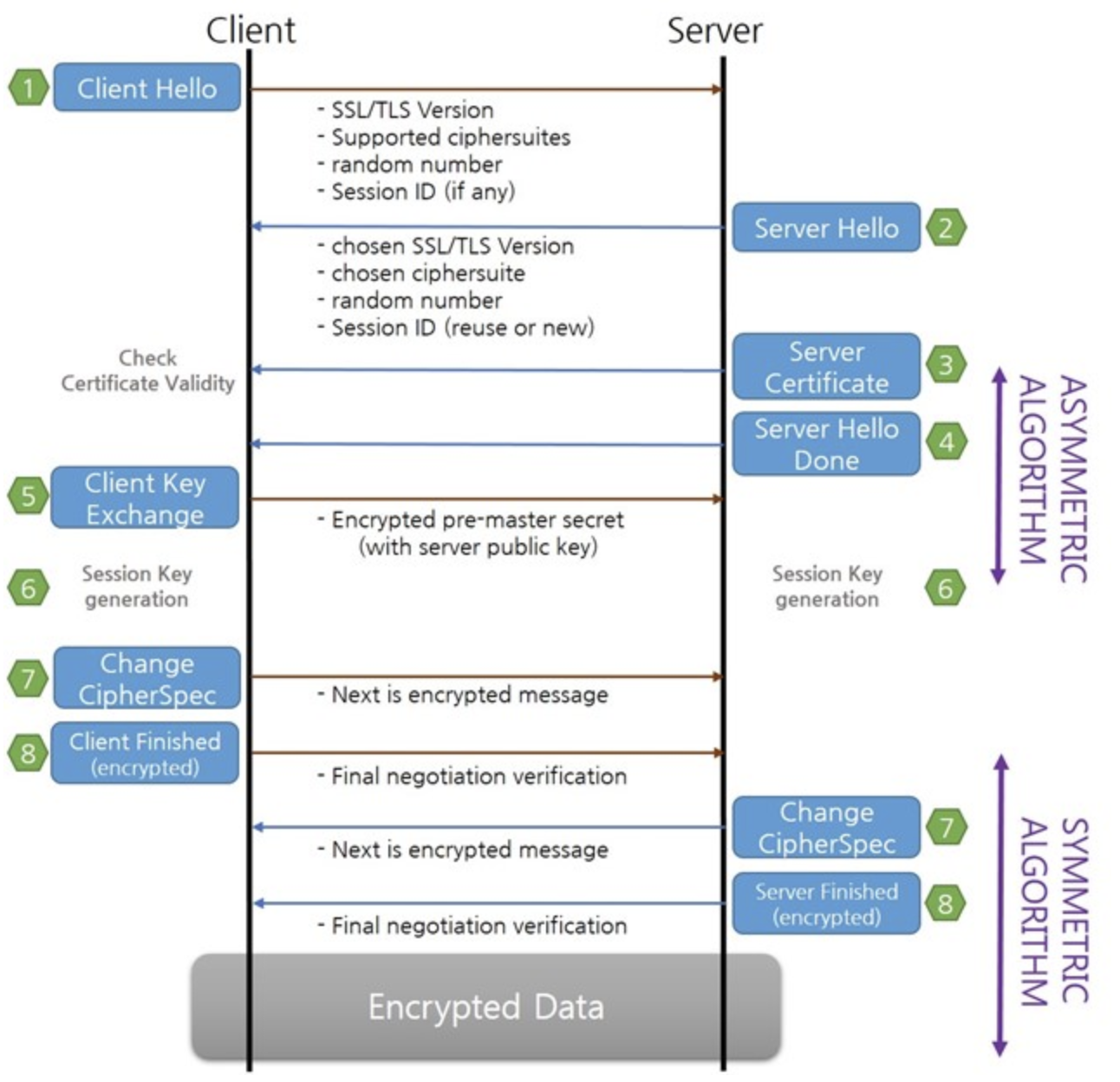
SSL/TLS Version(최종적으로 서버가 클라이언트가 보낸 Version 정보중에서 적합한 Version을 선택)
CipherSuite를 선택한다. 기본적으로는 가장 암호화 알고리즘이 강력한 것을 선택하나, Prefer CipherSuite 를 통해서 우선순위를 정의할 수 있다.
Session Key 생성을 위한 random number
클라이언트가 기존 Session ID를 가지고 요청하는 경우 서버의 Session Cache에 해당 정보가 있을 경우, 해당 Session ID 정보를 이용하여, Client Key Exchange 과정을 Skip할 수 있다. 클라이언트가 Session ID 정보를 Client Hello 패킷에 전송하지 않는 경우 새로운 Session ID를 생성하여 클라이언트에게 전달한다.
Server Certificate(서버 인증서)를 전달, 항상 서버인증서를 전달하지는 않는다.
예를 들면 Session Reuse일 경우 서버인증서를 전달하지 않을 수 있다.
클라이언트는 전달 받은 서버인증서의 유효성(유효기간,발행자,Common Name) 및 CA인증서를 통해서 서버인증서의 Public Key 추출한다.
Server Hello 패킷 전달이 종료되었다는 Server Hello Done 패킷을 전달한다.
클라이언트는 pre-master secret 키를 생성하고, 추출한 Public Key로 Encryption하여 서버에게 전달한다. 서버는 전달받은 데이터를 서버개인키를 이용하여 Decryption한다.
클라이언트/서버는 각각 pre-master secret키로부터 Master Key 및 Session Key를 생성한다.
다음메세지부터 암호화된 메시지를 전달한다고 각각 서버 및 클라이언트에게 전달한다.
생성한 sessioin key를 이용하여 현재까지의 Handshake 정보의 MAC정보를 각각 클라이언트/서버에게 전달한다.
이후 데이터 부터는 session key로 암호화된 데이터가 전송이 된다.
QUIC
전송계층 프로토콜로, 2013년에 공개 되었으며 현재 구글 관련 제품 대부분의 기본 프로토콜이다. UDP 기반으로 만들었다.
TCP의 경우는 신뢰성을 확보하기 위해 엄청나게 긴 헤더를 가지고 있고, 지연을 줄이기 힘든 구조이다. UDP는 데이터 전송에만 집중했기 때문에 별도의 기능이 없는 대신, 개발자가 원하는 기능을 개발할 수 있다.
QUIC의 특징
1) 전송 속도의 향상: 첫 연결 설정에서 아예 필요한 정보와 함께 데이터를 한번에 보낸다. 그렇게 해서 연결이 성공하게 되면 설정을 캐싱하여 다음 연결 때 handshake가 필요 없이 바로 성립 가능하도록 한다.
Connection UUID라는 고유한 식별자로 서버와 연결시킴으로써 커넥션 재 수립이 필요 없다.
따라서 ip가 바뀌거나 와이파이를 LTE로 바꾸거나 해도 커넥션 UUID로 연결을 하기 때문에 커넥션 재 수립이 필요 없음
2) 보안 측면에서 TLS이 기본 적용 되어 있고, Source Address Token을 필요에 따라 발급해 줌으로써 IP스푸핑/Replay Attack 방지
QUIC 그 자체에서 기본적으로 TLS를 적용하고 있다
HTTP/2에서는 TLS가 필수는 아니지만, TLS와 같은 보안을 적용해야 (브라우저에서) HTTP/2를 사용 가능하게끔 한다.
3) 독립 스트림을 써서 향상된 멀티플렉싱 기능을 지원한다.
사실 TCP 자체에서도 HOL 블로킹 이슈가 있다. 만약 스트림이 순서대로 처리되고 있는데 중간에 데이터가 소실되거나 하면 그 이후의 데이터들은 기다리고 있어야 함(서로 상관이 없는 데이터임에도 불구하고)
quic의 경우 독립된 스트림으로 운영할 수 있도록 설계하여 색이 다른 스트림에 문제가 생겨 대기를 하더라도 다른 색깔의 스트림에는 영향을 주지 않아 향상된 멀티플렉싱 기능을 지원한다.
⇒ QUIC을 바탕으로 HTTP/3이 등장하게 되었다.
HTTP/2 vs HTTP/3
용어
MIME(Multipurpose Internet Mail Extensions): 클라이언트에게 전송된 문서의 다양성을 알려주기 위한 메커니즘으로 type/subtype 으로 구성된다
URI : 통합 자원 식별자(Uniform Resource Identifier)는 인터넷에 있는 자원을 나타내는 유일한 주소이다. URI의 존재는 인터넷에서 요구되는 기본조건으로서 인터넷 프로토콜에 항상 붙어 다닌다. URI의 하위개념으로 URL, URN 이 있다
URL : URL(Uniform Resource Locator)은 네트워크 상에서 자원이 어디 있는지를 알려주기 위한 규약이다. 즉, 컴퓨터 네트워크와 검색 메커니즘에서의 위치를 지정하는, 웹 리소스에 대한 참조이다. URL은 웹 사이트 주소뿐만 아니라 컴퓨터 네트워크상의 자원을 모두 나타낼 수 있다. 그 주소에 접속하려면 해당 URL에 맞는 프로토콜을 알아야 하고, 그와 동일한 프로토콜로 접속해야 한다.
URN : URN(Uniform Resource Name)은 URN은 영속적이고, 위치에 독립적인 자원을 위한 지시자로 사용하기 위해 정의 되었다. 즉, 자원의 이름을 나타내는 말로서 자원 간에 중복되지 않은 유일한 값을 가진다.
멱등성 (Idempotent): Idempotent는 API URL에 요청을 할 경우 항상 같은 값이 나오는지 여부를 나타낸다.
HTTP Method는 GET, PUT, DELETE 그리고 POST가 있는데, POST를 제외한 나머지 HTTP Method를 사용하는 API들은 이 멱등성이 유지되어야 한다.
스트림: 구성된 연결 내에서 전달되는 바이트의 양방향 흐름이며, 하나 이상의 메시지가 전달될 수 있다
메세지: 논리적 요청 또는 응답 메시지에 매핑되는 프레임의 전체 시퀀스
프레임: HTTP/2에서 통신의 최소 단위이며 각 최소 단위에는 하나의 프레임 헤더가 포함 된다. 이 프레임 헤더는 최소한으로 프레임이 속하는 스트림을 식별함