💡 요약
- abstract: 컨테이너화된 환경을 위해 설계된 IO 제어 솔루션에 관한 연구
- introduction: 블록 스토리지를 위한 기존의 IO 제어 메커니즘은 스토리지 디바이스의 하드웨어 이질성과 데이터센터에 배포된 워크로드의 특수성을 고려하면서 최신 SSD에 알맞게 낮은 오버헤드로 실행되지 못한다는 문제가 있다.
- related works:
- IO 제어 및 공정성 분야의 다양한 관련 연구
- 프로덕션 스토리지 디바이스 전반의 성능 변동성, SSD 성능 예측을 위한 모델링 접근법, 가상 머신 모니터를 위한 IO 솔루션에 대한 연구
- IO 스택의 여러 계층에 걸친 정보를 고려해야 할 필요성
- 컨테이너를 위한 리소스 관리 솔루션과 아키텍처 확장
- method: 디바이스별 모델을 사용하여 각 IO 요청의 디바이스 점유율을 추정하는 방식으로 작동한다. => 오프라인 프로파일링, 디바이스 모델링, 새로운 작업 절약형 예산 기부 알고리즘을 활용하여 데이터센터의 다양한 워크로드와 이기종 스토리지 디바이스에 대해 확장 가능하고 작업을 절약하며 오버헤드가 낮은 IO 제어 기능을 제공함
- experiment: Meta의 모든 컨테이너에 IOCost를 배포하여 평가한 결과, IOCost는 최소한의 오버헤드로 비례적이고 작업을 절약하며 메모리 관리를 인식하는 IO 제어 성능이 뛰어났다.
- conclusion & discussion: IOCost는 ZooKeeper 배포, AWS Elastic Block Store/Google Cloud Persistent Disk 등의 원격 스토리지에서도 사용 가능하다.
Introduction
최근 주요 클라우드 업체들에서 컨테이너 기반 솔루션을 제공하고 있으며,
- https://aws.amazon.com/ko/containers/
- https://cloud.google.com/containers?hl=ko
- https://azure.microsoft.com/en-us/products/container-instances/
프라이빗 데이터센터에서도 컨테이너로 운영되는 추세이다. (Facebook도 전체 데이터센터가 컨테이너로만 운영되고 있다고 함)
기존에는 컴퓨팅, 메모리, 네트워크에 대한 리소스 격리에 대해 많은 연구가 이루어져왔는데, 블록 스토리지에 대한 기존 IO 제어 메커니즘도 개선이 필요하다.
- IO 제어는 데이터센터의 하드웨어 이질성을 고려해야 한다. 디바이스 종류 뿐만 아니라 한 유형 내에서도 지연 시간 및 처리량 측면에서 크게 다른 성능 특성을 가지기도 함.
- 특히 짧은 순간에 성능을 과도하게 발휘한 후 급격히 느려져 스택 환경에 악영향을 미칠 수 있는 SSD 특성을 고려해야
- IO 제어는 다양한 애플리케이션의 이질성을 고려해야 한다.
- 지연 시간에 민감 vs 처리량 vs 순차적 또는 무작위 액세스를 버스트 또는 연속적으로 수행
=> 하드웨어 + 애플리케이션 이질성으로 인해 지연 시간과 처리량 간의 균형점을 파악하는 것이 어렵다
- IO 격리는 페이지 회수 및 스왑과 같은 메모리 관리 작업과 잘 상호 작용 할 수 있도록 고려되어야 한다.
Background
1) cgroup: 컨테이너별 리소스 할당을 구성하기 위한 기술
컨테이너 런타임은 리소스 제어 및 격리를 위해 cgroup을 사용한다.
- cgroup: 컨테이너가 프로세스를 계층적으로 구성하고 계층을 따라 시스템 리소스를 제어 및 구성 가능한 방식으로 배포하기 위한 기본 메커니즘
- 개별 cgroup이 계층 구조를 형성하고, 프로세스는 하나의 cgroup에 속한다.
- cgroup 컨트롤러는 주로 가중치를 활용하여 CPU, 메모리 및 IO와 같은 특정 시스템 리소스를 트리를 따라 배포한다.
- 모든 형제 cgroup의 가중치를 합산하고 각각에 합계에 대한 가중치의 비율을 부여하여 리소스를 배포
2) Linux 블록 레이어와 기존 IO 제어 솔루션

애플리케이션과 파일시스템은 블록 계층을 사용하여 블록 디바이스에 접근한다.

그림과 같이 userspace에서 시스템 호출을 통해 커널과 상호 작용하며, 파일시스템에 대한 읽기 및 쓰기 작업은 파일시스템 IO(FS IO)로 블록 레이어로 전달된다.

블록 레이어는 bio 데이터 구조를 사용하여 아래와 같은 다양한 정보를 전달한다.
- 요청 유형: read/write
- 크기
- 대상 장치
- 장치의 섹터 오프셋
- 요청한 cgroup
- 데이터를 복사하거나 복사할 메모리 등의 정보
Linux 커널에는 활성화할 수 있는 여러 가지 IO 스케줄러가 있다.
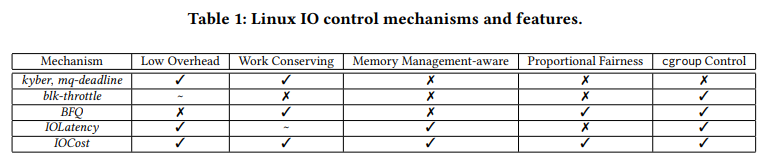
- cgroup 제어가 없는 IO 스케줄링: 컨테이너에 특정 IO 리소스를 보장하기보다는 일반적인 성능 속성을 유지하는 데 우선순위를 둔다. 전체 시스템 성능을 유지하기 위해 일반적으로 느린 비동기 read가 일반적으로 빠르고 즉각적인 응답이 필요한 동기 read보다 우선권을 갖지 못하도록 한다.
- 스케줄러 없는 경우
- mq-deadline
- kyber
- blk-throttle: read/write IOPS 또는 초당 바이트의 형태로 IO 제한을 설정할 수 있으나, 유휴 상태이거나 사용하지 않는 리소스를 필요로 하는 컨테이너 또는 워크로드에 할당할 수 없다는 단점이 있다.
- BFQ: IO 리소스를 비례적으로 제어할 수 있으나, 메모리 관리와의 상호 작용을 간과하여 잠재적으로 격리 문제를 일으킬 수 있다. 요청당 오버헤드가 높고 지연 시간 편차가 크며, 컨테이너당 read/write 섹터를 기반으로 하는 라운드 로빈 스케줄링은 내부 작업이 복잡한 최신 디바이스에는 효과적이지 않다는 단점이 있다.
- IOLatency: 개별 cgroup에 대한 IO 레이턴시 목표를 설정할 수 있으며, 다른 cgroup의 IO가 레이턴시 목표를 초과하면 이전 cgroup이 호출된다. IOLatency는 주로 엄격한 우선순위를 가진 컨테이너 간에 스케줄링은 적합하지만, 동일한 우선순위를 가진 컨테이너에 대해 비례 제어가 부족하여 워크로드 간의 공평성을 보장하기 어렵다는 한계가 있다.
3) 이기종 블록 장치와 워크로드가 있는 최신 데이터센터의 컨텍스트
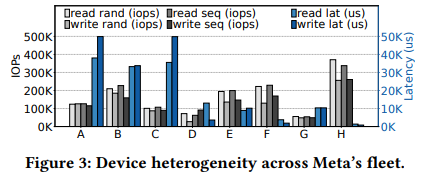
Meta의 데이터센터에는 다양한 SSD가 있고, SSD간에 하드웨어 디바이스적 성능 특성이 매우 이질적이다.
- H: 낮은 레이턴시에서 높은 IOPS를 달성
- G: 낮은 IOPS와 상대적으로 낮은 레이턴시를 제공
- A: 높은 레이턴시와 함께 중간 정도의 IOPS를 제공

Meta의 애플리케이션을 분석해보면 IO 워크로드가 매우 다양함을 알 수 있다.
- Web A /B: 가장 일반적인 Meta 워크로드로, 읽기 및 쓰기가 무작위 및 순차 작업 측면에서 거의 동일하게 혼합되어 있다.
- serverless: 할당용량을 초과하는 경우가 많으며, 읽기 및 쓰기 양이 거의 동일하게 혼합되어 있다.
- Cache A/B: 인메모리 캐시를 위한 백업 저장소로 고속 블록 장치를 사용하는 인메모리 캐싱 서비스로, 두 캐시 모두 많은 양의 순차적 IO로 이루어져있다. (주로 스토리지 관련 작업을 수행)
Related Work
- 기존 연구는 대부분 하이퍼바이저를 개선하기 위함 + VM 기반 가상화 환경에 중점
- 단일 공유 운영 체제, 메모리 하위 시스템과 IO의 상호 작용, 고도로 스택된 배포와 같은 컨테이너의 복잡성을 고려하지 않는다는 한계점이 존재한다.
- Linux 커널의 IO 제어는 BFQ 또는 최대 대역폭 사용량(IOPS 또는 바이트) 기반의 제한에 의존
- BFQ: 우선순위와 요청량에 따라 각 프로세스에 디스크 시간 예산을 할당하여 여러 프로세스 또는 애플리케이션 간에 디스크 대역폭을 공정하게 할당하는 것을 목표로 하는 알고리즘 => 특정 프로세스가 디스크 독점 방지/모든 프로세스가 공평하게 IO 리소스를 할당받을 수 있도록 함
- 디바이스의 유휴 자원을 모두 활용하지 못하거나, 빠른 저장장치에 과도한 성능 오버헤드를 추가하는 한계점
- 기존의 CPU 스케줄링은 가중 공정 큐잉과 같은 기술을 사용하여 CPU 사용 시간을 측정하여 CPU 점유율을 비례적으로 배분했는데, I/O 제어에 사용되는 IOPS나 바이트와 같은 지표는 특히 블록 디바이스의 다양성을 고려할 때 점유율을 측정하기 좋지 않다.
- 최신 블록 디바이스는 내부 버퍼링과 가비지 컬렉션과 같은 복잡한 지연 작업에 크게 의존하므로, 디바이스 시간 공유에 의존하거나 주로 IOPS 또는 바이트를 기반의 공정성 보장 기술에 문제가 있다.
Method
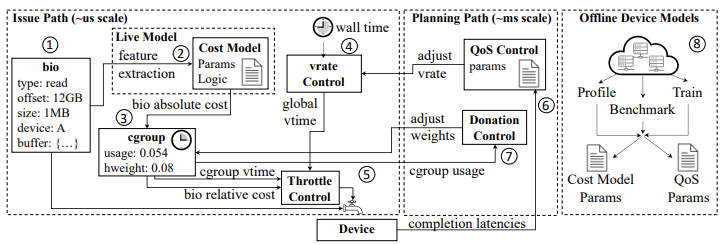
IOCost는 디바이스의 복잡성과 무관하게 워크로드를 구성하기 위해 디바이스와 워크로드 구성을 분리한다.
- 각 디바이스에 대해 IOCost는 비용 모델과 디바이스 동작을 정의하고 규제하는 일련의 서비스 품질(QoS) 파라미터를 설정
- 각 워크로드에 대해 IOCost는 비례 구성을 위해 cgroup 가중치(hweight = 해당 cgroup이 받을 수 있는 IO 디바이스의 최종적인 비중)를 활용
- 지연 시간이 짧은 issue path 와 주기적으로 동작하는 planning path 를 분리
1) IO 디바이스 점유율을 추정하는 모델링: 개별 bio 작업의 점유를 추정 => 이 점유 추정치를 사용하여 각 cgroup에 할당된 가중치에 따라 스케줄링 결정을 내린다.
- 선형 모델을 사용하여 읽기/쓰기 초당 바이트 수, 초당 4kB 순차 및 랜덤 IO(IOPS) 등의 매개변수를 기반으로 IO 작업 비용을 계산한다.
- fio 오픈소스 도구를 이용하여 다양한 블록 크기 및 액세스 패턴(순차 또는 임의), 읽기/쓰기과 같은 다양한 유형의 I/O 워크로드를 시뮬레이션하여 평가함
- 단순한 선형 모델링만으로는 복잡한 캐싱 메커니즘, 요청 재정렬, 가비지 컬렉션이 있는 최신 SSD의 복잡성을 포착하기에 충분하지 않으므로, 모델의 부정확성을 보완하기 위해 IOCost는 cgroup 사용량과 IO 완료 대기 시간에 대한 실시간 통계를 기반으로 IO 제어를 런타임에 조정한다.
- 요청 시 자원부족 및 지연 시간 목표 위반을 추적하여(디바이스 포화 상태를 파악) 디바이스로 전송되는 총 IO를 제한하고 QoS 매개변수를 사용하여 디바이스 동작을 규제함 => 일관된 지연 시간 제어
- QoS 매개변수: 가상 워크로드(ResourceControlBench)를 사용하여 지연에 민감한 서비스의 동작을 관찰하고 그에 따라 QoS 매개변수를 조정하는 체계적인 접근 방식을 개발했다. 다양한 전송률 범위에서 성능을 분석하여 IO 제어를 위한 최적의 지점을 파악 => 일관된 지연 시간을 달성하기 위해 디바이스를 스로틀링하는 방법을 결정
2) 디바이스의 유휴자원을 모두 활용할 수 있는 작업 보존 알고리즘 => 컨테이너가 과도한 메모리를 사용할 때 다른 컨테이너가 불이익을 받는 리소스 격리 문제 해결 = 컨테이너에 대한 블록 IO 제어

- 개별 cgroup에 할당된 IO 용량을 완전히 활용하지 못하는 경우에는 해당 cgroup의 가중치를 동적으로 낮춤으로써 다른 cgroup이 장치를 활용하고 사용하지 않은 리소스를을 공유할 수 있도록 하여 효율적인 리소스 활용을 보장한다.
3) 런타임 오버헤드를 최소화하기 위해 IO 제어를 빠른 IO별 이슈 경로와 느린 주기적 계획 경로로 분리
- wall clock time: 작업을 수행하는 데 걸리는 실제 시간으로, 측정된 작업 완료 시간은 당시 시스템에서 수행 중인 다른 작업(CPU, I/O, Sub Program 등)의 영향을 받을 수 있다.
- vtime(virtual time rate): Wall clock time과 함께 진행되는 글로벌 가상 시간으로, IOCost 시스템에서 각 cgroup 내의 IO 작업의 진행 상황을 추적하고 관리하기 위해 사용되는 개념이다.
- 로컬 vtime: 특정 cgroup 내 IO 작업의 진행 상황을 나타낸다. 각 cgroup의 IO 작업에 따라 증가하며, 증가하는 속도는 해당 IO 작업의 상대적 비용(동일한 cgroup 내의 다른 작업과 비교하여 IO 작업이 얼마나 많은 리소스 또는 시간을 필요로 하는지)에 의해 결정됨
- 글로벌 vtime: 모든 cgroup의 모든 IO 작업에 대한 전반적인 진행 상황을 나타낸다. 이는 가상 시간 속도(vrate)에 의해 결정된 Wall clock time과 함께 진행되는 가상 시간이다.
- 스로틀링 결정은 cgroup의 로컬 vtime과 글로벌 vtime 간의 차이(=cgroup의 현재 IO 예산)를 비교하여 이루어지며, 이를 통해 IO를 즉시 실행할 수 있는지 또는 할당된 예산 내에서 유지하기 위해 추가 진행 상황을 기다려야 하는지를 결정함
- group의 현재 IO 예산이 IO의 상대적 비용을 충당하기에 충분하면 즉시 실행되고, 그렇지 않으면 글로벌 vtime이 더 진행될 때까지 IO가 대기한다.
- issue path: 로컬 및 글로벌 vtime에 따라 IO 작업의 비용을 결정하고, features에 따라 비용모델을 이용하여 bio의 절대 비용을 계산하고, 스로틀링 결정을 내린다. 각 cgroup에는 가중치(형제 그룹에서의 IO 점유 비율)가 할당되며, 이러한 가중치는 hweight로 재계산되어 캐싱된다.
- IOCost는 활성 cgroup과 비활성 cgroup을 구분하여, 유휴 cgroup의 남는 자원을 활성 cgroup에서 사용할 수 있도록 한다. 만약 활성/비활성 cgroup의 상태가 변경되면 hweight 가중치를 재계산한다.
- 활성 cgroup: IO 요청이 있는 경우
- 비활성 cgroup: IO 없이 전체 planning 기간(= IO 제어 결정이 내려지는 전체 기간)이 지나는 경우로, 가중치 계산 시 무시된다.
- IOCost는 활성 cgroup과 비활성 cgroup을 구분하여, 유휴 cgroup의 남는 자원을 활성 cgroup에서 사용할 수 있도록 한다. 만약 활성/비활성 cgroup의 상태가 변경되면 hweight 가중치를 재계산한다.
- planning path: 글로벌 오케스트레이션을 담당하며, 데이터센터의 각 cgroup 운영을 조정하여 IO 리소스를 효율적이고 공정하게 분배할 수 있도록 한다. 주기적으로 각 cgroup의 IO 사용량을 평가하고, 그에 따라 가중치를 조정한다. 또한 서비스 품질(QoS) 매개변수를 통해 vrate를 수정하여 cgroup 당 발생하는 IO 요청량을 조정한다.
Evaluation
다양한 유형의 SSD가 장착된 단일 소켓 64GB 서버에서 테스트 수행
1) 데이터 센터의 고속 SSD에 대한 IO를 제어할 때는 오버헤드를 최소화하는 것이 중요하다.
=> 최대 초당 입출력 작업 수(IOPS)를 측정하는 실험
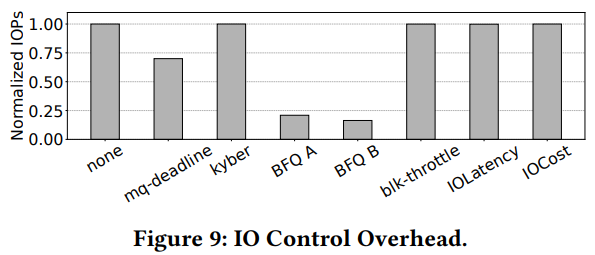
- none = 소프트웨어 스케줄러나 컨트롤러가 실행되지 않은 상태로, 디바이스에서 블록 레이어의 달성 가능한 최대 처리량
- IOCost: issue path/planning path로 분할하므로, 복잡한 스로틀링 로직을 가지고 있음에도 오버헤드가 발생하지 않는다.
2) 유휴 자원의 효율적 활용을 보장하는 것이 중요하다.
=> 서로 다른 우선순위를 가진 워크로드에 대해 요청 지연 시간의 특정 임계값을 초과하지 않고 원활하게 실행되는지 평가

- cgroup 인식 IO 제어 메커니즘의 성능 => High:Low = 2:1 이 최적의 분배일때
- IOCost: 예상되는 2:1 비율과 정확히 일치하여 비례 제어에 효과적임을 입증
=> 서로 다른 우선순위를 가진 워크로드에 대해 우선순위 및 지연 시간 요구 사항을 고려하면서, 얼마나 리소스를 비례적으로 잘 배분할 수 있는지 평가
** think time: 다음 연속적인 요청을 실행하기까지 대기/지연 시간 = 새로운 요청이 발생하지 않는 유휴시간
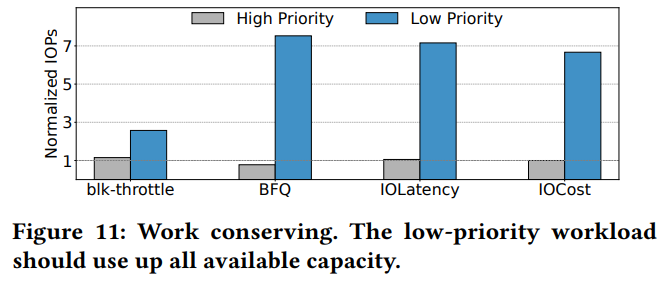
- IOCost: 우선순위가 높은 워크로드의 레이턴시를 효과적으로 관리하면서, 우선순위가 낮은 워크로드가 유휴자원을 활용할 수 있도록 허용함을 입증
3) 다양한 워크로드 간의 공정성과 적절한 격리를 보장하는 것이 중요하다.
=> 각 메커니즘이 디바이스 점유 측면에서 얼마나 공정성을 제공하고 우선순위가 높은 워크로드와 낮은 워크로드 간에 원하는 비율을 유지하는지를 평가

- IOCost: random/sequential IO의 비용을 모델링하고 디바이스 점유 측면에서 공정성을 보장함으로써 모든 시나리오에서 원하는 2:1의 비율을 유지한다.
4) 최신 SSD의 경우, 단순한 모델링 접근 방식은 부정확하기 때문에 이를 효과적으로 보정하는 것이 중요하다.
=> SSD 워크로드에 대해 원하는 서비스 품질(QoS)을 유지하는 데 있어 IOCost의 동적 조정(vrate)의 효과를 평가
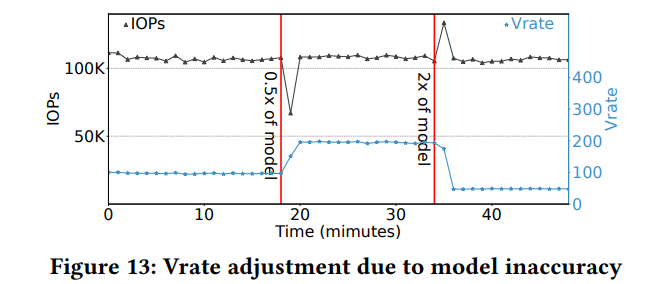
- 처음에는 vrate가 약 100으로 유지
- 0.5x of model(모델 매개변수 값을 감소 = 장치의 점유량이 이전보다 절반으로 줄어드는 경우): IOPs(읽기 속도)가 떨어지지만, QoS를 유지하며 발급 속도를 약 두 배로 상승시켜 IOPs를 유지한다.
- 2x of model(모델 매개변수 값을 증가 = 디바이스의 점유량이 이전보다 두 배로 늘어나는 경우): 처음에는 디바이스를 과도하게 포화시켜 지연 시간이 급증하지만, QoS를 유지하기 위해 vrate가 초기 값의 약 절반으로 떨어지면서 지연 시간이 감소한다.
5) 효율적인 리소스 확보를 위해 메모리 관리 통합이 중요하다. (우선순위가 높은 워크로드에 리소스를 보장하면서 우선순위가 낮은 워크로드가 나머지 리소스를 활용할 수 있도록 리소스를 적절하게 회수하기 위해)
=> 여러 조건에서 웹 서버 처리량을 평가

- IOCost: 메모리 누수 프로세스와 같은 까다로운 조건에서도 웹 서버 처리량을 일정하게 유지
=> 오버커밋 환경에서 IOCost의 성능을 평가

- ramp up time: 본 실험에서 최대 부하의 40% -> 80%로 확장하는 데 걸리는 시간
- IOCost: BFQ보다 약 5배 빠르게 스케일업을 완료할 수 있다
6) 여러 컨테이너 간에 IO 서비스의 공정한 할당이 중요하다.
=> Zookeeper와 유사한 워크로드에서 노이즈가 많은 이웃 앙상블과 스냅샷의 영향을 얼마나 잘 차단하는지, 그리고 읽기 및 쓰기 작업에 대한 레이턴시 서비스 수준 목표(SLO)를 충족할 수 있는지 평가

- IOCost: 노이즈가 많은 이웃 앙상블과 스냅샷의 영향을 효과적으로 격리하여 서비스의 레이턴시 SLO 위반을 최소화한다.
- SLO 위반이 1.5s, 1.04s 두번만 발생함
7) 퍼블릭 클라우드와 같은 원격 블록 스토리지 환경에도 적용 할 수 있어야한다.
=> 로컬 스토리지와 원격 연결 스토리지를 포함한 다양한 구성에서(AWS 및 Google Cloud와 같은 퍼블릭 클라우드) IOCost가 IO를 얼마나 잘 격리할 수 있는지 평가
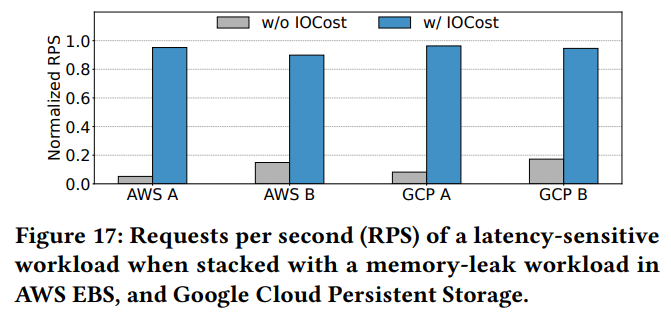
- 지연 시간에 민감한 워크로드(ResourceControlBench)를 AWS Elastic Block Store(gp3-3000iops, io2-64000iops) 및 Google Cloud persistent disk(balanced, SSD)를 사용하여 다양한 구성에서 메모리 누수 워크로드와 함께 배치
- IOCost를 적용하지 않은 경우: 두 워크로드 간에 간섭이 발생하여 RPS(초당 요청)가 감소
- IOCost가 적용된 경우: 메모리 누수 워크로드로 인한 간섭으로부터 ResourceControlBench를 효과적으로 격리하고 보호하여 RPS가 높은 값으로 나타난다.
8) 경합이 심한 조건에서도 시스템 서비스 및 워크로드 간에 IO 리소스를 공정하게 분배(비례 제어 기능)할 수 있어야한다.
** IO 고갈로 인한 통신 장애 및 성능 저하가 발생할 수 있는 데이터센터의 패키지 가져오기 장애/컨테이너 정리 장애에 유용
=> 비례 제어 기능을 갖춘 IOCost가 이러한 장애 발생을 크게 줄이고 시스템 안정성과 리소스 관리를 개선할 수 있음을 입증
- package fetching: 컨테이너화된 애플리케이션에 필요한 소프트웨어 패키지 또는 종속성을 검색하는 프로세스 => IO 고갈(충분한 입출력 리소스 부족)이 발생하면 패키지 검색에 실패하고 후속 컨테이너 업데이트에 실패할 수 있다.
- IOCost가 활성화되면 해당 리전에서 package fetching 오류의 비율이 감소하여 IOLatency와 비교했을 때 오류가 10배 감소
- container cleanup: 데이터센터 환경에서 오래된 컨테이너를 제거하거나 삭제하는 프로세스 => 리소스 경합이나 기타 요인으로 인해 이 작업 중에 IO 고갈이 발생하면 오래된 컨테이너 정리가 지연되어 성능이 저하되거나 충분한 디스크 공간을 확보할 수 없을 수 있다.
- IOCost가 활성화되면 container cleanup 실패 발생이 IOLatency에 비해 3배 감소
Discussion
요즘 연구해보고 싶은 분야와 비슷해서 정말 많이 도움됐다.
컨테이너 기술 동향에 대해서도 살펴볼 수 있었다.
** 컨테이너를 위한 아키텍처 및 OS 확장에 관한 연구
- D. Skarlatos, Q. Chen, J. Chen, T. Xu and J. Torrellas, "Draco: Architectural and Operating System Support for System Call Security," 2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Athens, Greece, 2020, pp. 42-57, doi: 10.1109/MICRO50266.2020.00017.
- D. Skarlatos, U. Darbaz, B. Gopireddy, N. Sung Kim and J. Torrellas, "BabelFish: Fusing Address Translations for Containers," in IEEE Micro, vol. 41, no. 3, pp. 57-62, 1 May-June 2021, doi: 10.1109/MM.2021.3073194.