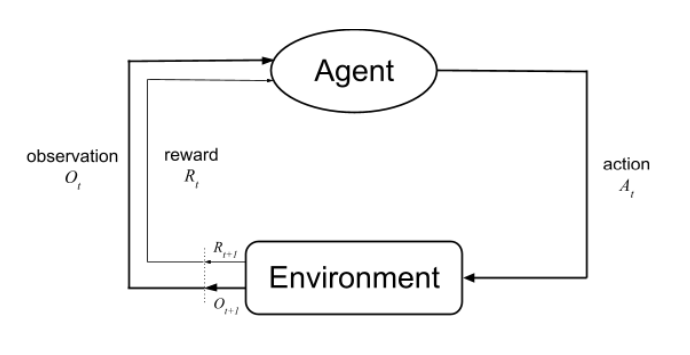
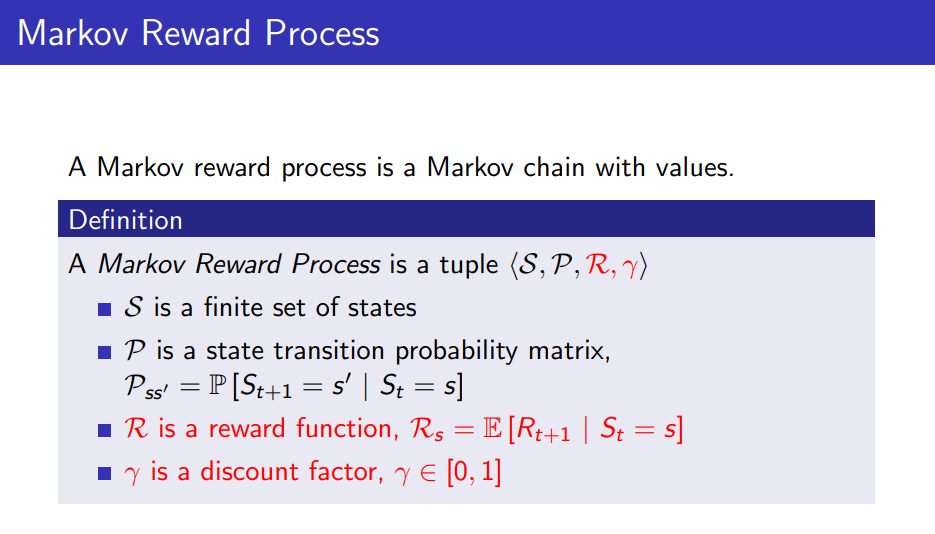
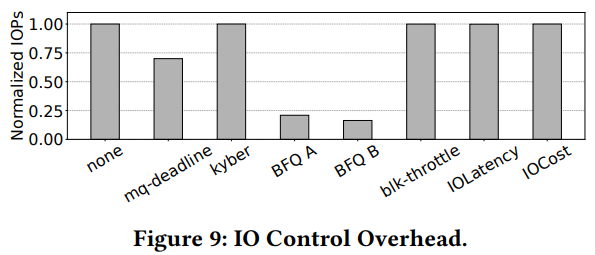
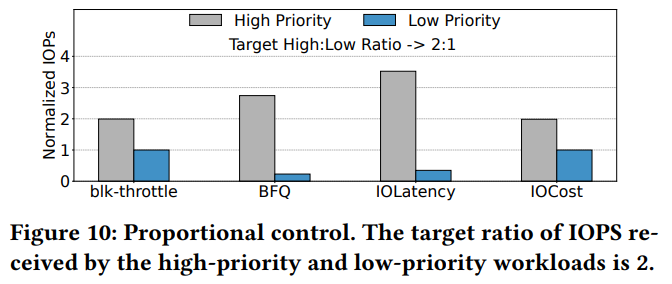
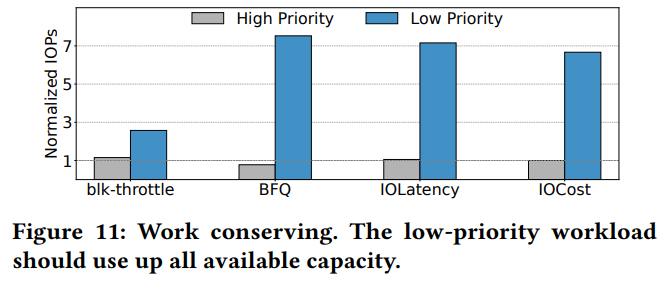
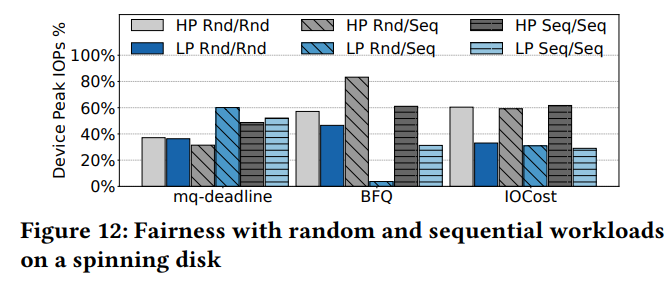
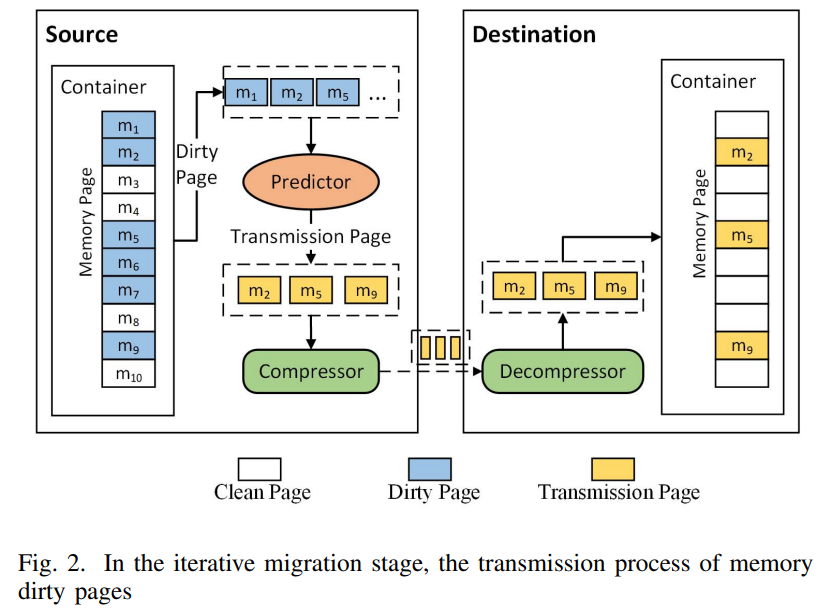
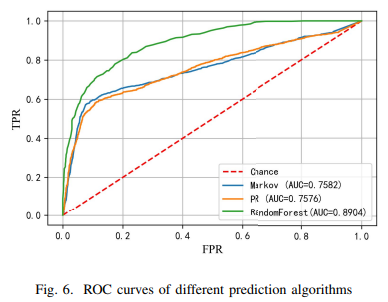
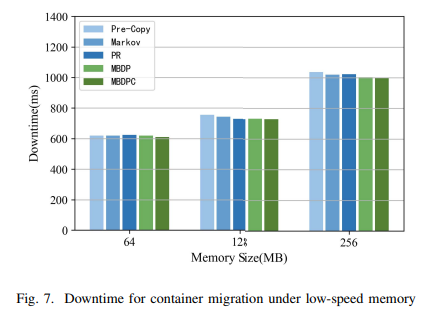
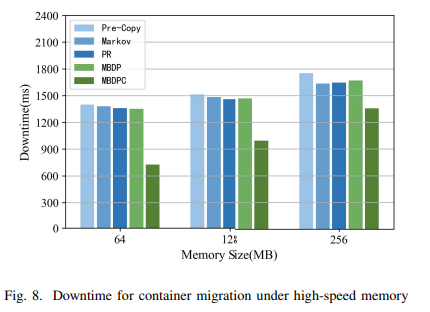
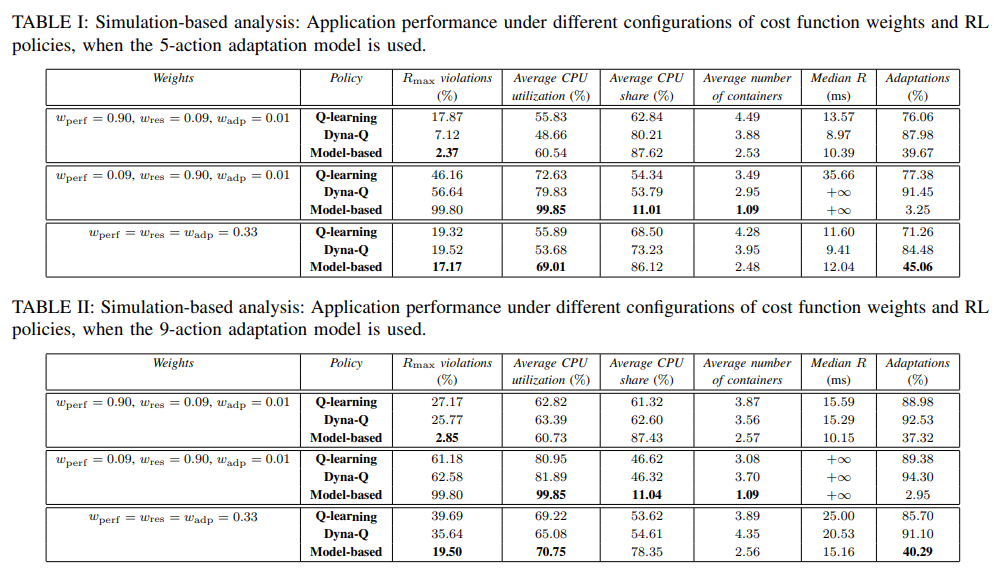
Planning for Dynamic Programming (Model-Based)
- Planning = Model-Based: MDP에 대한 모든 정보를 다 알때(Model이 있을 때) ex. environment, state, state transition, ...
- Dynamic Programming: Planning 문제를 풀기 위한 방법론으로 DP가 되기 위한 조건이 2가지 있다.
- Optimal Substructure: 전체 큰 문제에 대한 optimal solution이 작은 문제들로 쪼갤 수 있어야 한다. = Bellman Eq가 recursive하게 적용 가능
- Overlapping Subproblems: subproblems들을 구하고 캐싱하여 계산적 이득 = value function(작은 문제들의 정답값)들이 저장되고 솔루션을 구할 때 재사용된다.
MDP가 만족되면 DP를 적용하여 "문제를 푼다"
DP는 MDP에 대한 모든 것을 알고 있다고 가정한다.(full-knowledge = Model-Based)
- Prediction을 풀기: MDP & Policy가 주어졌을 때, MDP가 Policy를 따랐을 때 리턴을 얼마 받는지, 즉 value function이 어떻게 되는지 v_π를 찾는 문제 = Value Function을 학습 = Policy Evaluation
- Bellman Expectation Equation을 iterative하게 적용한다.
- random하게 v1 초기화
- 모든 State에 대해 π를 이용하여 v2 구하기 (synchronous backup)
- 2 반복
- v_π에 수렴
- Bellman Expectation Equation을 iterative하게 적용한다.
- Control을 풀기: MDP가 주어졌을 때, optimal policy π*를 찾는 문제 = Optimal Policy를 찾기
- Policy Iteration: 결국 π는 policy iteration을 하면 optimal policy π*로 수렴한다
- Policy π를 평가: v_π(s) = E[R_{t+1} + rR_{t+2} + ... | S_t=s]
- v_π의 값이 가장 좋은 쪽으로 움직임: π' = greedy(v_π)
- 1-2 반복
- Modified Policy Iteration: policy evaluation 단계에서 꼭 v_π가 수렴할 필요 없이 early-stopping도 가능하고, batch 단위로 업데이트도 가능함
- Value Iteration: policy iteration과 달리 explicit한 policy가 없다
- v1 초기화
- Bellman Optimality backup(synchronous) 적용
- 2 반복
- Principle of Optimality: Optimal Policy는 두가지 요소로 나뉠 수 있다
- 첫 action A가 optimal하다 = A*
- 그 action을 해서 어떤 State s'에 도달하면 거기서부터 또 optimal policy를 따라간다
- 즉, Bellman Optimality Equation에 따르면 v*(s) = max_a(R_s^a + r\sum_{s' from State} P_{ss'}^a v*(s'))
- 즉 상태 s의 optimal value를 알기 위해서는 다음 상태 s'까지 진행해봐야 상태 s의 value가 최적인지/아닌지 판단이 가능하다
- S0 -> S1 -> ... ->St(terminate) 인 시퀀스가 있을 때, V(St)를 알아야 비로소 V0(S0)을 알 수 있다.
- Policy Iteration: 결국 π는 policy iteration을 하면 optimal policy π*로 수렴한다

예를 들어 길찾기 문제에서 goal 근처의 value는 goal을 이용하여 계산하게 된다.
*하지만 DP에서 모든 상태에 대한 업데이트를 동시에 진행해야하므로, goal의 optimal value가 goal과 가까운 곳부터 퍼져나가면서 다른 위치의 칸들이 optimal vlaue를 계산할 수 있을 때 까지 여러번 반복된다. 이를 value iteration이라고 한다.
- 알고리즘이 State value function에 의존하고 있으면 한 iteration마다 complexity는 O(mn^2)
- 알고리즘이 State action value function에 의존하고 있으면 한 iteration마다 complexity는 O(m^2n^2)
위의 경우 모두 synchronous backup을 말하고 있는데, asynchronous backup을 하는 경우 computation을 줄일 수 있다.
(State 들이 비슷한 확률로 다양하게 뽑힌다면 수렴도 보장된다.)
asynchronous backup을 할 땐 state에 우선순위를 두고 하면 빠르게 수렴될 수 있는데, Bellman error가 클수록 우선순위를 높게 설정한다. asynchronous backup을 하는 경우에는 계산적 이득 뿐만 아니라 실제로 구현 시 v array를 하나만 사용해도 된다.
- Bellman error = |max_a(R_s + r\sum_{s' from State} P_{ss'}^a v(s)) - v(s)|
State Space가 넓고 Agent가 도달하는 State가 한정적인 경우에는, Agent를 움직이게 해 놓고, Agent가 방문한 State를 먼저 업데이트하는 Real-Time Dynamic Programming 기법이 효과적이다.
사실 DP는 full-width backup으로, s에서 갈 수 있는 모든 s'를 이용하여 value를 업데이트 하게 되기 때문에 medium-sized problem에는 효과적이지만, 큰 문제에서는 비효율적이다. (state 수가 늘어날수록 계산량이 exponential하게 증가하므로)
따라서 큰 문제에서는 sample backup을 사용한다.
- state가 많아져도 고정된 비용(sample 갯수)로 backup (=dimension이 커질 때 발생하는 문제를 sampling을 통해 해결)
- model-free 상황에서도 가능
Model-Free Prediction
'CS > Etc' 카테고리의 다른 글
| RL 스터디 개념 정리(1) 1~2강 RL 용어 정리 및 MDP (0) | 2024.01.18 |
|---|---|
| Strace to monitor Dockerized Application: trial and error (0) | 2023.04.26 |
| Memory Management in Python (2) - Python 가비지 컬렉터 (2) | 2023.01.13 |
| Memory Management in Python (1) - Python 메모리 할당 (0) | 2023.01.12 |